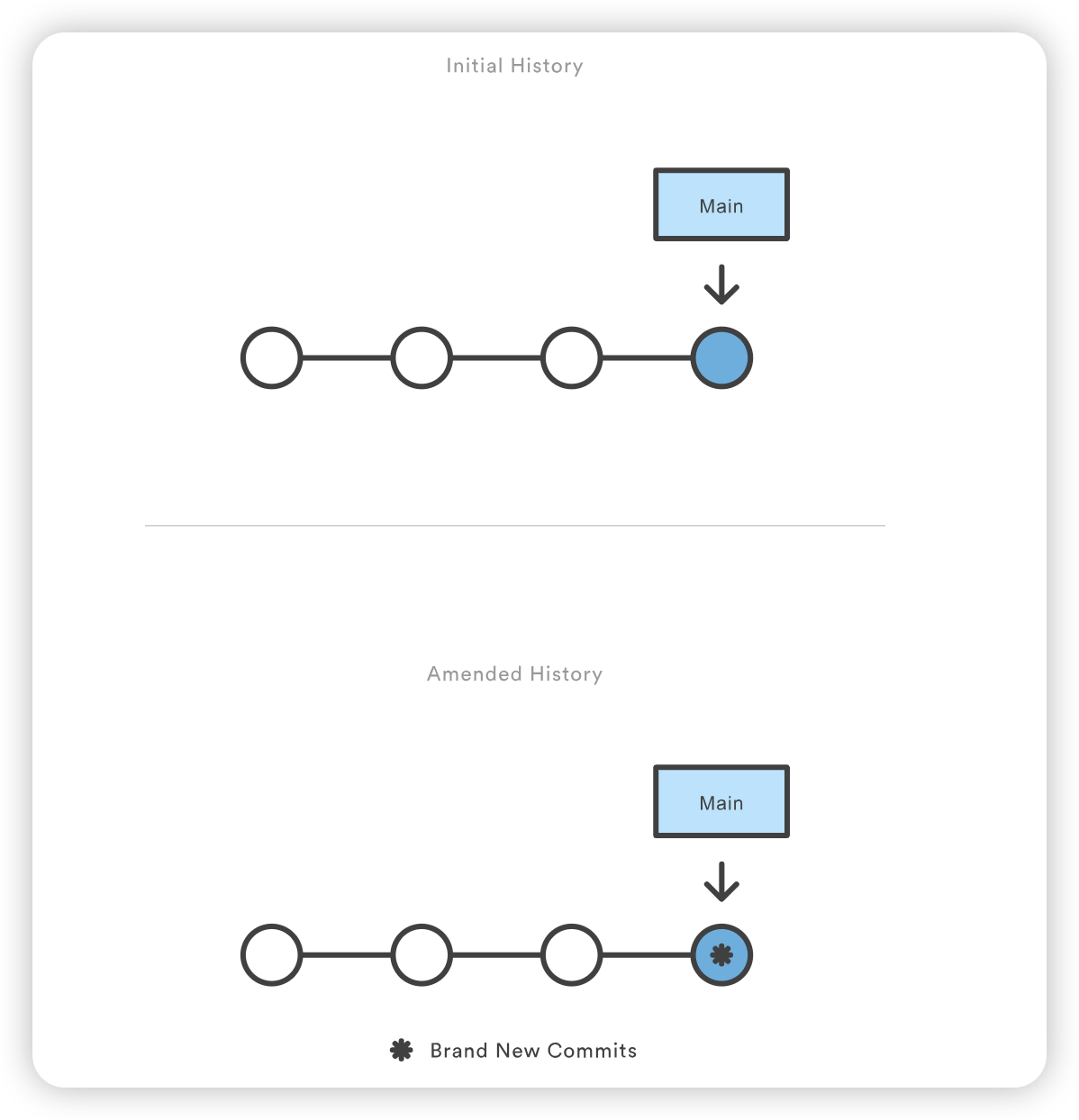
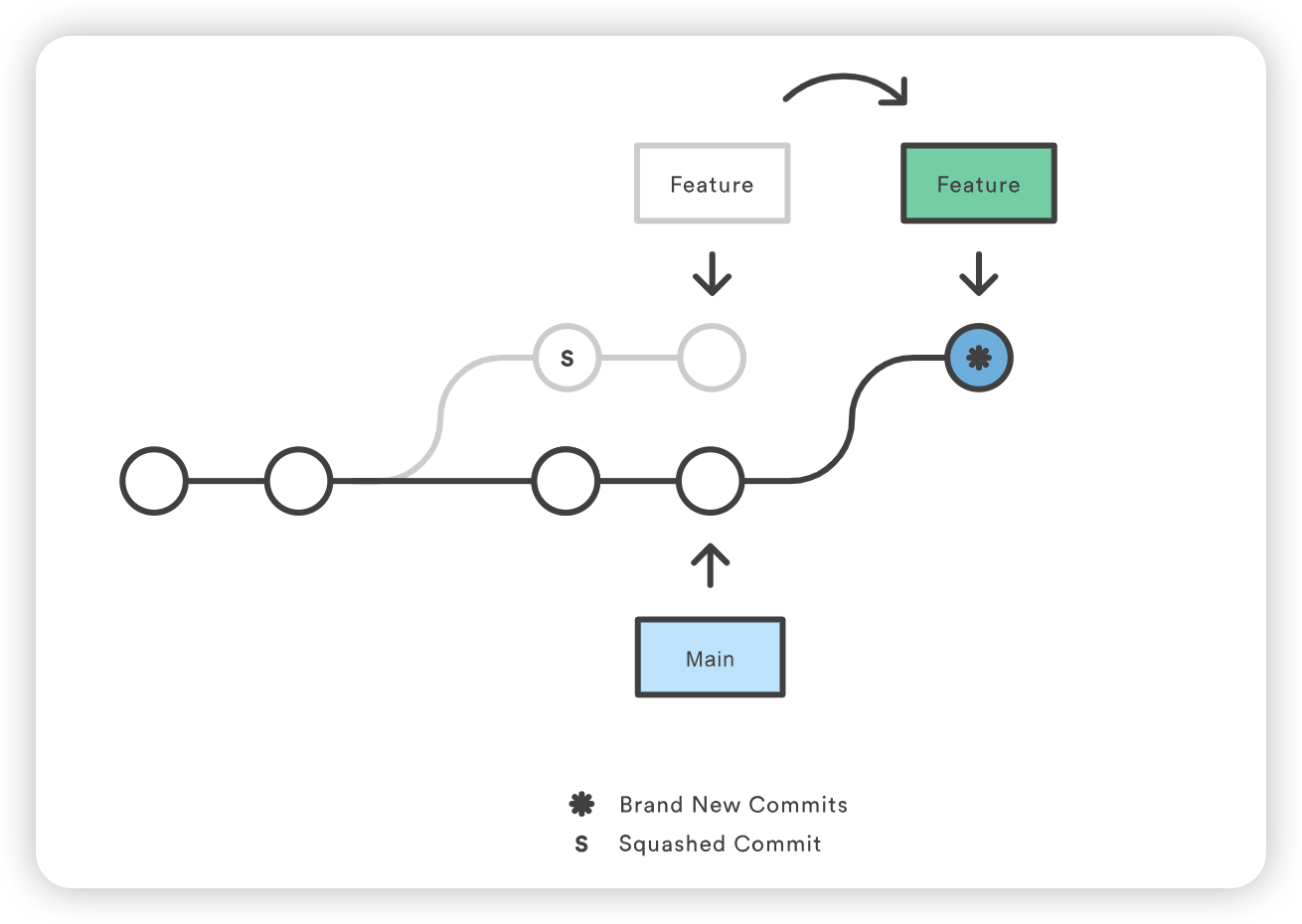
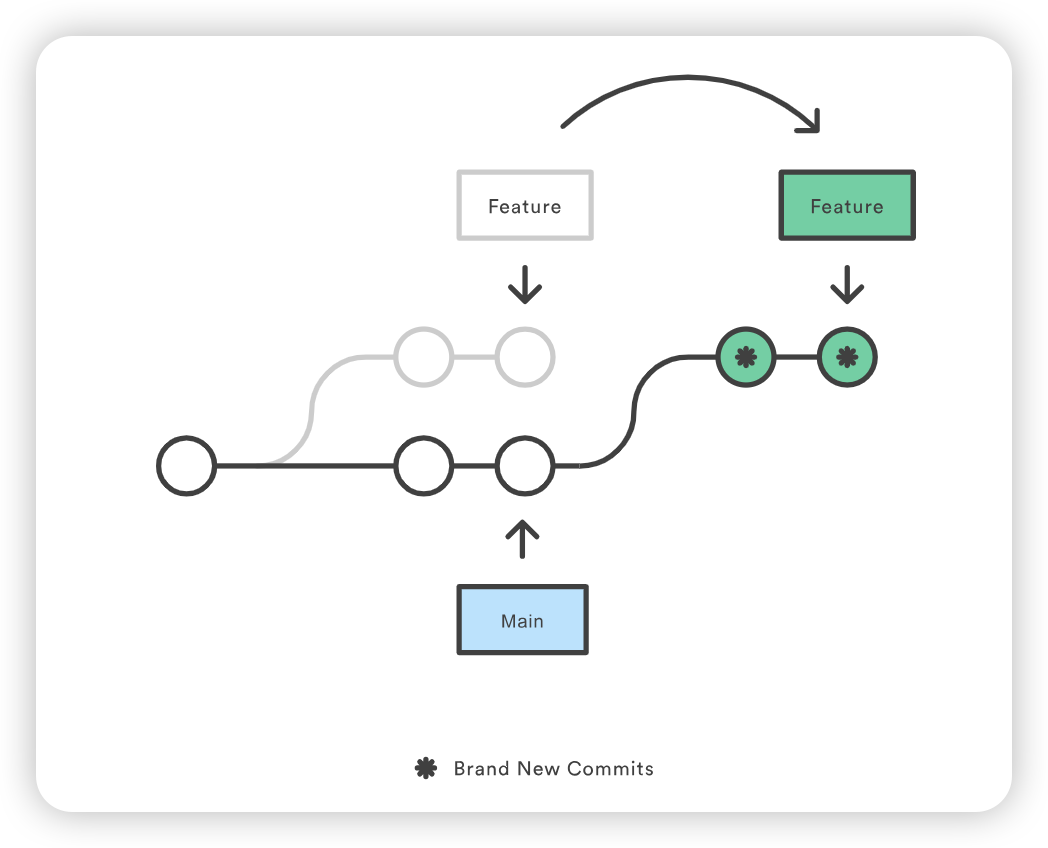
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded // 首先,检查 class 是否已经被加载 Class<?> c = findLoadedClass(name); if (c == null) { // 如果没有被加载 long t0 = System.nanoTime(); try { if (parent != null) { // 寻找 parent 加载器 c = parent.loadClass(name, false); } else { // 如果父加载器不存在,则委托给启动类加载器加载 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. // 如果仍然无法加载,才会尝试自身加载 long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } }
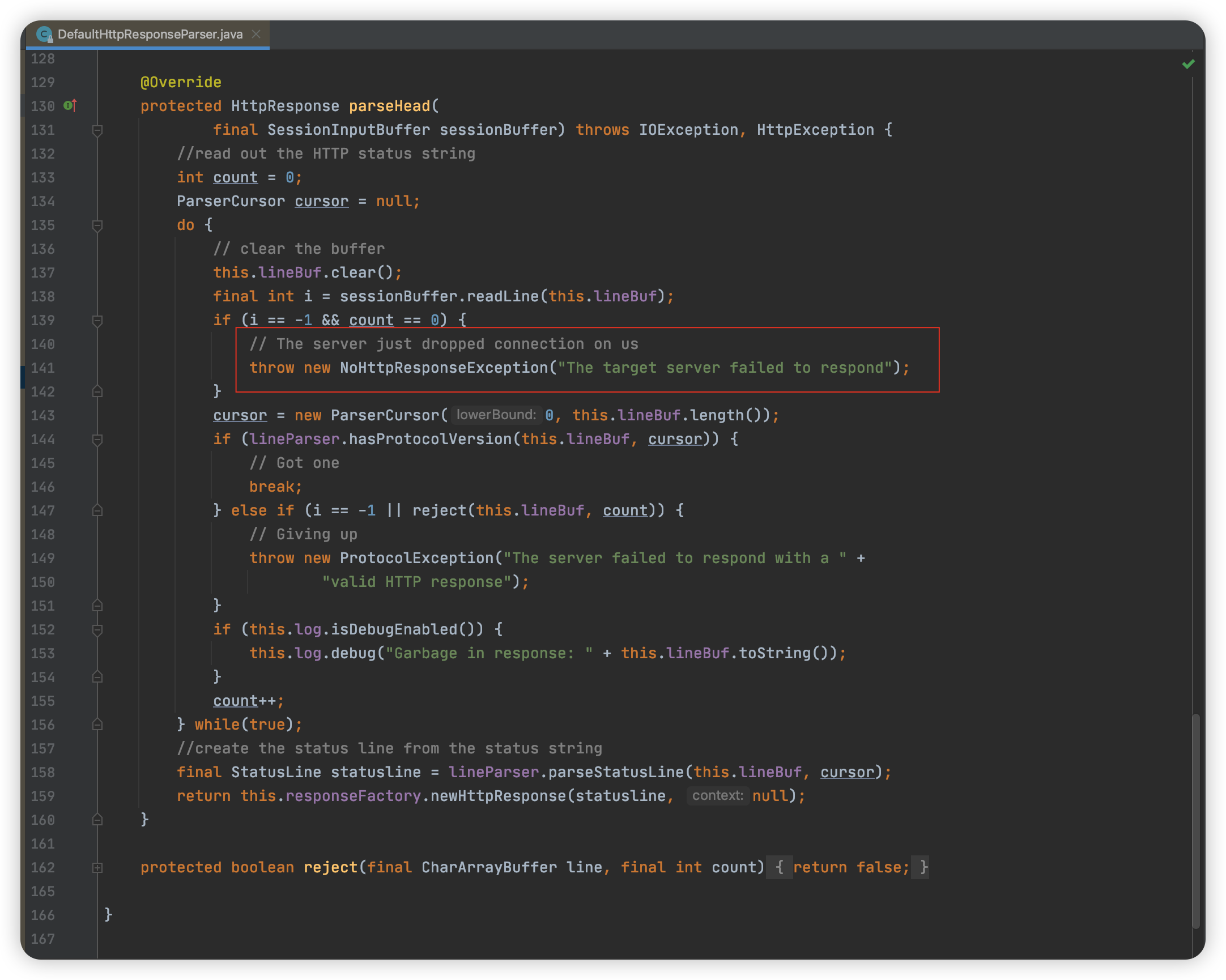
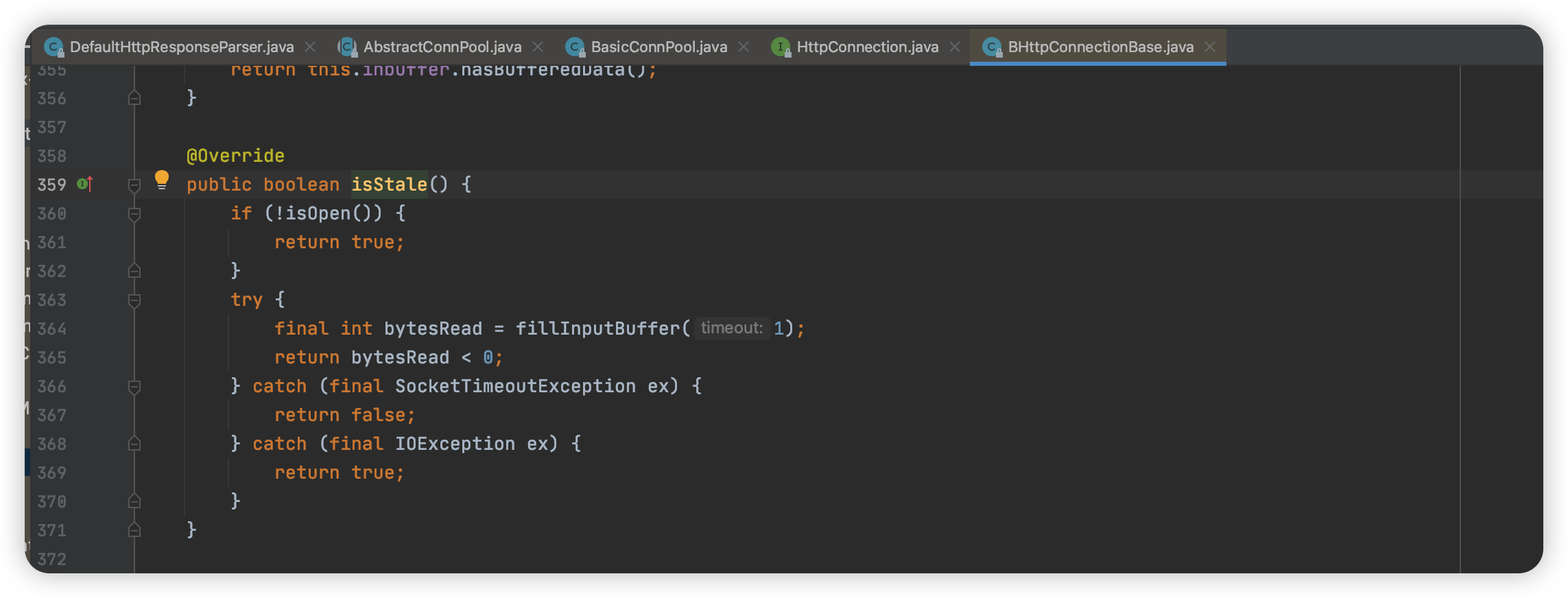
此时,502 Bad Gateway 的报错虽然没有出现,但是会偶发性的出现NoHttpResponseException的报错,大搞也是2亿笔出现3-4笔的NoHttpResponseException的报错。然后我们就怀疑502 Bad Gateway 报错和NoHttpResponseException报错本质上是一样的。
NoHttpResponseException错误详情:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
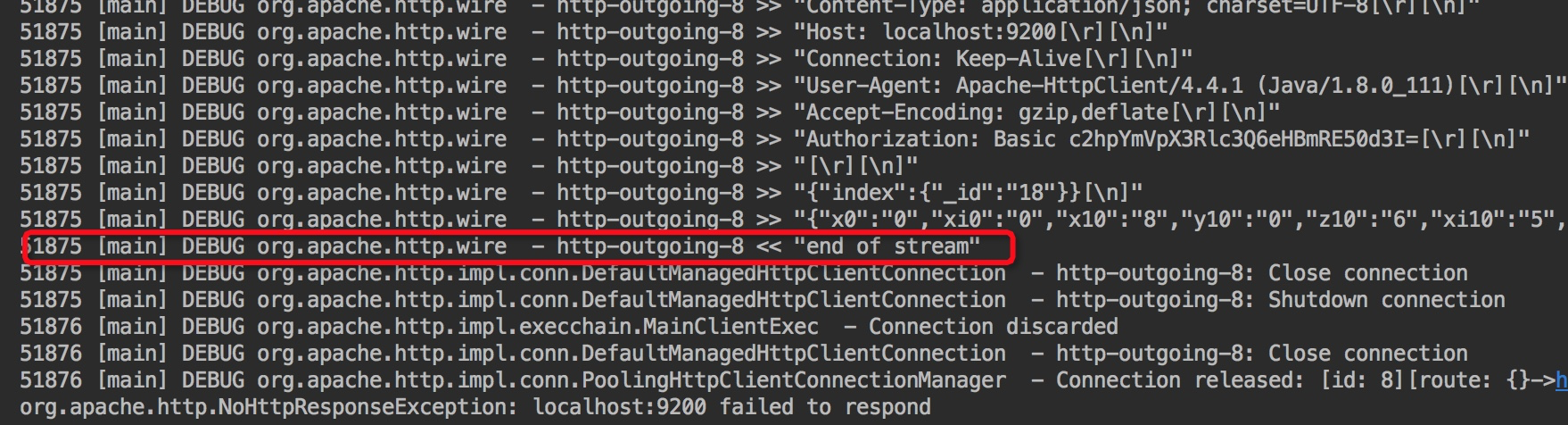
org.apache.http.NoHttpResponseException: target failed to respond at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:141) at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:56) at org.apache.http.impl.io.AbstractMessageParser.parse(AbstractMessageParser.java:259) at org.apache.http.impl.DefaultBHttpClientConnection.receiveResponseHeader(DefaultBHttpClientConnection.java:163) at org.apache.http.impl.conn.CPoolProxy.receiveResponseHeader(CPoolProxy.java:157) at org.apache.http.protocol.HttpRequestExecutor.doReceiveResponse(HttpRequestExecutor.java:273) at org.apache.http.protocol.HttpRequestExecutor.execute(HttpRequestExecutor.java:125) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:272) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)
command must be a valid jcmd commandfor the selected jvm. Use the command"help" to see which commands are available. If the pid is 0, commands will be sent to all Java processes. The main class argument will be used to match (either partially or fully) the class used to start Java. If no options are given, lists Java processes (same as -p).
PerfCounter.print display the counters exposed by this process -f read and execute commands from the file -l list JVM processes on the local machine -h this help
[root@localhost ~]$ jmap -help Usage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <core> (to connect to a core file) jmap [option] [server_id@]<remote server IP or hostname> (to connect to remote debug server)
where <option> is one of: <none> to print same info as Solaris pmap -heap to print java heap summary -histo[:live] to print histogram of java object heap; if the "live" suboption is specified, only count live objects -clstats to print class loader statistics -finalizerinfo to print information on objects awaiting finalization -dump:<dump-options> to dump java heap in hprof binary format dump-options: live dump only live objects; if not specified, all objects in the heap are dumped. format=b binary format file=<file> dump heap to <file> Example: jmap -dump:live,format=b,file=heap.bin <pid> -F force. Use with -dump:<dump-options> <pid> or -histo to force a heap dump or histogram when <pid> does not respond. The "live" suboption is not supported in this mode. -h | -help to print this help message -J<flag> to pass <flag> directly to the runtime system
[root@localhost ~]$ jmap -heap 21074 Attaching to process ID 21074, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.131-b11
using thread-local object allocation. Parallel GC with 4 thread(s)
"mythread2"#12 prio=5 os_prio=0 tid=0x0000018dc2547000 nid=0x2580 waiting on condition [0x000000468cdff000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to waitfor <0x000000076b8dbf28> (a java.util.concurrent.locks.ReentrantLock$NonfairSync) at java.util.concurrent.locks.LockSupport.park(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(Unknown Source) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(Unknown Source) at java.util.concurrent.locks.ReentrantLock$NonfairSync.lock(Unknown Source) at java.util.concurrent.locks.ReentrantLock.lock(Unknown Source) at DeathLock.lambda$deathLock$1(DeathLock.java:24) at DeathLock$$Lambda$2/1044036744.run(Unknown Source) at java.lang.Thread.run(Unknown Source)
查看帮助信息
可以通过执行jstack 或者 jstack -h来查看帮助信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ jstack Usage: jstack [-l] <pid> (to connect to running process) jstack -F [-m] [-l] <pid> (to connect to a hung process) jstack [-m] [-l] <executable> <core> (to connect to a core file) jstack [-m] [-l] [server_id@]<remote server IP or hostname> (to connect to a remote debug server)
Options: -F to force a thread dump. Use when jstack <pid> does not respond (process is hung) -m to print both java and native frames (mixed mode) -l long listing. Prints additional information about locks -h or -help to print this help message
"Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. However, this dress is about $ 3183 dollars. GNU is free air not free beer. Her hair is very beauty. I can't finish the test. Oh! The soup taste good. motorcycle is cheap than car. This window is clear. the symbol '*' is represented as start. Oh! My god! The gd software is a library for drafting programs. You are the best is mean you are the no. 1. The world <Happy> is the same with "glad". I like dog. google is the best tools for search keyword. goooooogle yes! go! go! Let's go. # I am VBird
范例 1:搜索特定字符
从文件中取得 the 这个特定字符串,最简单的方式如下
1 2 3 4 5 6
[mrcode@study tmp]$ grep -n 'the' regular_express.txt 8:I can't finish the test. 12:the symbol '*' is represented as start. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 18:google is the best tools for search keyword.
反向选择,可以看到输出结果少了上面的 8、12、15、16、18 行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[mrcode@study tmp]$ grep -vn 'the' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 5:However, this dress is about $ 3183 dollars. 6:GNU is free air not free beer. 7:Her hair is very beauty. 9:Oh! The soup taste good. 10:motorcycle is cheap than car. 11:This window is clear. 13:Oh! My god! 14:The gd software is a library for drafting programs. 17:I like dog. 19:goooooogle yes! 20:go! go! Let's go. 21:# I am VBird 22:
忽略大小写 ,多出来几行
1 2 3 4 5 6 7 8
[mrcode@study tmp]$ grep -in'the' regular_express.txt 8:I can't finish the test. 9:Oh! The soup taste good. 12:the symbol '*' is represented as start. 14:The gd software is a library for drafting programs. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 18:google is the best tools for search keyword.
范例 2:利用中括号[]来搜索集合字符
如果要搜索 test 或 taste 这两个单词时,可以发现他们其实有共同的 t?st 存在
1 2 3
[mrcode@study tmp]$ grep -n 't[ae]st' regular_express.txt 8:I can't finish the test. 9:Oh! The soup taste good.
中括号中,无论几个字符都表示任意一个字符。如果想要搜索到所有 oo 字符时
1 2 3 4 5 6 7
[mrcode@study tmp]$ grep -n 'oo' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes!
如果不想要 oo 前面的 g 呢?
1 2 3 4 5
[mrcode@study tmp]$ grep -n '[^g]oo' regular_express.txt 2:apple is my favorite food. 3:Football game is not use feet only. 18:google is the best tools for search keyword. 19:goooooogle yes!
# 由于小写字符的 ASCII 编码顺序是连续的,所以可以简化为,否则就需要把 a-z 都写出来 [mrcode@study tmp]$ grep -n '[^a-z]oo' regular_express.txt 3:Football game is not use feet only.
# 取得有数字那一行 [mrcode@study tmp]$ grep -n '[0-9]' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1.
[mrcode@study tmp]$ grep -n '[^[:lower:]]oo' regular_express.txt 3:Football game is not use feet only.
[mrcode@study tmp]$ grep -n '[[:digit:]]' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1.
# 只要行首是 the 的 [mrcode@study tmp]$ grep -n '^the' regular_express.txt 12:the symbol '*' is represented as start.
# 想要行首是小写字符开头的 [mrcode@study tmp]$ grep -n '^[a-z]' regular_express.txt 2:apple is my favorite food. 4:this dress doesn't fit me. 10:motorcycle is cheap than car. 12:the symbol '*' is represented as start. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. # 下面的等效 # [mrcode@study tmp]$ grep -n '^[[:lower:]]' regular_express.txt
# 不要英文字母开头的 # ^ 在中括号内表示反选,在外表示定位首航 [mrcode@study tmp]$ grep -n '^[^a-zA-Z]' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 21:# I am VBird
# 找出行尾为 . 符号的数据 # 使用 \ 对 小数点转义 [mrcode@study tmp]$ grep -n '\.$' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 5:However, this dress is about $ 3183 dollars. 6:GNU is free air not free beer. 7:Her hair is very beauty. 8:I can't finish the test. 9:Oh! The soup taste good. 10:motorcycle is cheap than car. 11:This window is clear. 12:the symbol '*' is represented as start. 14:The gd software is a library for drafting programs. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 17:I like dog. 18:google is the best tools for search keyword. 20:go! go! Let's go.
[mrcode@study tmp]$ cat -An regular_express.txt | head -n 10 | tail -n 6 5 However, this dress is about $ 3183 dollars.^M$ 6 GNU is free air not free beer.^M$ 7 Her hair is very beauty.^M$ 8 I can't finish the test.^M$ 9 Oh! The soup taste good.^M$ 10 motorcycle is cheap than car.$ # 但实际上 ^M 被丢失了
# 找出 g??d 的字符串,也就是 g 开头 d 结尾的 4 字符的字符串 [mrcode@study tmp]$ grep -n 'g..d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 9:Oh! The soup taste good. 16:The world <Happy> is the same with "glad".
# 找出 oo、ooo、ooo 等数据,至少含有 2 个 o # 注意,这里不能写 oo* 因为,*是作用于第二个 o 的,表示 0 到任意个 # 也就是说如果是 oo* 有可能匹配到一个 o [mrcode@study tmp]$ grep -n 'ooo*' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes!
# 找出 开头与结尾都是 g ,并且中间至少含有一个 o 的数据 # 也就是 gog、goog 之类的数据 [mrcode@study tmp]$ grep -n 'goo*g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
# 找出 开头与结尾都是 g,中间有无字符均可 [mrcode@study tmp]$ grep -n 'g*g' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 3:Football game is not use feet only. 9:Oh! The soup taste good. 13:Oh! My god! 14:The gd software is a library for drafting programs. 16:The world <Happy> is the same with "glad". 17:I like dog. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. # 使用 g*g 发现第一行的数据就不匹配,这个还是需要再终端看,因为可以开启高亮,方便查看哈 # 原因是 * 作用于 g,g* 代表空字符或一个以上的 g,因此应该匹配 g、gg、ggg 等 # 正确的应该这样实现 [mrcode@study tmp]$ grep -n 'g.*g' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 14:The gd software is a library for drafting programs. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go.
# 找出包含任意数字的数据 # 同上,[0-9]* 只作用于一个中括号 [mrcode@study tmp]$ grep -n '[0-9][0-9]*' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1. # 直接使用 grep -n '[0-9]' regular_express.txt 也可以得到相同结果哈
范例 5:限定连续 正则字符范围 {}
找出 2 个到 5 个 o 的连续字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 华括弧在 shell 中是特殊符号,需要转义 [mrcode@study tmp]$ grep -n 'o\{2\}' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes! # 上述结果是至少是 2 个 oo 的出来了
# 单词开头结尾都是 g,中间 o,至少 2 个,最多 5 个 [mrcode@study tmp]$ grep -n 'go\{2,5\}g' regular_express.txt 18:google is the best tools for search keyword.
# 承上,只是中间的 o 至少 2 个 [mrcode@study tmp]$ grep -n 'go\{2,\}g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
基础正则表示法字符汇总
^word:搜索的关键词 word 在行首
范例:搜索行首为 # 的,并列出行号 grep -n '^#' file
word$:搜索的关键词 word 在行尾
范例:搜索以 !结尾的,grep -n '!$' file
.:一定有一个任意字符
范例:搜索字符串可以是 eve、eae、eee、e e;grep -n 'e.e' file
\:转义字符
范例:搜索含有单引号数据。grep -n '\’' file
*:重复另个到无穷多个前一个字符
范例:找出含有 es、ess、esss 等字符串;grep -n 'es*' file
[list]:里面列出想要截取的字符合集
范例:找出含有 g1 或 gd 的数据;grep -n 'g[1d]' file
[n1-n2]:字符合集范围
范例:找出含有任意大写字母的数据;grep -n '[A-Z]' file
[^list]:不要包含该集合中的字符或该范围的字符
范例:找出 ooa、oog 但是不包含 oot 的数据; grep -n 'oo[^t]'
\{n,m\}:连续 n 到 m 个前一个字符
\{n\}:连续 n 个前一个字符
\{n,\}:至少 n 个以上的前一个字符;咋效果上感觉和 \{n\} 是一样的
最后再强调,通配符和正则表达式不一样,比如在 ls 命令中找出以 a 开头的文件
通配符:ls -l a*
正则表达式:ls | grep -n '^a' 或则 ls | grep -n '^a.*'
1 2 3 4 5
# 范例:以 ls -l 配合 grep 找出 /etc/ 下文件类型为链接文件属性的文件名 # 符号链接文件的特点是权限前面一位是 l,根据 ls 的输出,只要找到行首为 l 的即可 [mrcode@study tmp]$ ls -l /etc | grep '^l' lrwxrwxrwx. 1 root root 56 Oct 4 18:22 favicon.png -> /usr/share/icons/hicolor/16x16/apps/fedora-logo-icon.png lrwxrwxrwx. 1 root root 22 Oct 4 18:23 grub2.cfg -> ../boot/grub2/grub.cfg
sed 工具
了解了一些正则基础使用后,可以来玩一玩 sed 和 awk ;作者就利用他们两个实现了一个小工具:logfile.sh 分析登录文件(第十八章会讲解)。里面绝大部分关键词的提取、统计等都是通过他们来完成的
sed:本身是一个管线命令,可以分析 standard input 的数据,还可以将数据进行替换、新增、截取特定行等功能
1 2
sed [-nefr] [动作]
选项与参数:
n:使用安静(silent)模式
在一般 sed 的用法中,所有来自 STDIN 的数据一般都会列出到屏幕上,加上 -n 之后,只有经过 sed 特殊处理的那一行(或则动作)才会被打印出来
e:直接在指令模式上进行 sed 的动作编辑
f:直接将 sed 的动作写在一个文件内,- f filename 则可以执行 filename 内的 sed 动作
# 范例1:利用 sed 将 /tmp/regular_express.txt 内每一行结尾若为 . 则换成 ! # 下面还是使用了动作 s 替换,后面的是转义 . 和 ! # 这样可以直接修改文件内容 [mrcode@study tmp]$ sed -i 's/\./\!/g' regular_express.txt
# 范例2:利用 sed 直接在 /tmp/regular_express.txt 最后一行加入 # This is a test # $ 表示最后一行 [mrcode@study tmp]$ sed -i '$a # This is a test ' regular_express.txt # 想要删除最后一行就简单了 [mrcode@study tmp]$ sed -i '$d' regular_express.txt
[mrcode@study tmp]$ egrep -n 'go+d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 9:Oh! The soup taste good! 13:Oh! My god!
?:「0 个或 1 个」的前一个 RE 字符
范例:搜索 gd、god
1 2 3
[mrcode@study tmp]$ egrep -n 'go?d' regular_express.txt 13:Oh! My god! 14:The gd software is a library for drafting programs!
|:用或(or)的方式找出数个字符串
范例:搜索 gd 或 good
1 2 3 4
[mrcode@study tmp]$ egrep -n 'gd|good' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 9:Oh! The soup taste good! 14:The gd software is a library for drafting programs!
():找出「群组」字符串
范例:搜索 glad 或 good
1 2 3 4 5 6
# 当然,这里使用上面完整的或来匹配两个固定单词也是可以的 [mrcode@study tmp]$ egrep -n 'g(la)|(oo)d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 2:apple is my favorite food! 9:Oh! The soup taste good! 16:The world <Happy> is the same with "glad"!
# # # This file is used by the man-db package to configure the man and cat paths. # It is also used to provide a manpath for those without one by examining # their PATH environment variable. For details see the manpath(5) man page.
# 增加执行权限 [mrcode@study bin]$ chmod a+x read.sh # 执行 [mrcode@study bin]$ ./read.sh first name: zhu last name: mrcode You full name: zhumrcode
下面是书上的程序
1 2 3 4 5 6 7 8 9 10 11 12 13
vim showname.sh #!/bin/bash # Program: # 用户输入姓名,程序显示出输入的姓名 # History: # 2020/01/19 mrcode first release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "Please input you first name: " firstname # 提示使用者输入 read -p "Please input you last name: " lastname # 提示使用者输入 # -e 开启反斜杠转移的特殊字符显示,比如下面的 \n 换行显示 echo -e “\n Your full name is: ${firstname}${lastname}” # 结果由屏幕输出
1 2 3 4 5 6
# 执行结果 [mrcode@study bin]$ ./showname.sh Please input you first name: zhu Please input you last name: mrcode
Your full name is: zhumrcode
笔者小结:可以看到上面这个脚本,增加了一个良好的习惯,就是脚本说明等信息
随日期变化:利用 date 进行文件的建立
考虑一个场景,每天备份 MySql 的数据文件,备份文件名以当天日期命名,如 backup.2020-01-19.data.
vim file_perm.sh #!/bin/bash # Program # User input a filename,program will check the flowing: # 1.) exist? # 2.) file/directory? # 3.) file permissions # History # 2020/01/19 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo -e "Please input a filename,I will check the filename's type and permission. \n\n" read -p "Input a filename :" filename # 判断是否输入了字符串 test -z ${filename} && echo"You MUST input a filename. " && exit 0
# 判断该文件是否存在: 不存在输出提示信息并退出 test ! -e ${filename} && echo"The filename ${filename} does not exist" && exit 0
# 开始判断文件类型与属性 test -f ${filename} && filetype="regulare file" test -d ${filename} && filetype="directory" test -r ${filename} && perm="readable" test -w ${filename} && perm="${perm} writable" test -x ${filename} && perm="${perm} executable"
# 信息输出 echo"The filename: ${filename} is a ${filetype}" echo"And the permissions for you are : ${perm}"
测试输出如下
1 2 3 4 5 6 7 8 9 10 11 12 13
[mrcode@study bin]$ ./file_perm.sh Please input a filename,I will check the filename's type and permission. Input a filename :ss The filename ss does not exist [mrcode@study bin]$ ./file_perm.sh Please input a filename,I will check the filename's type and permission.
Input a filename :/etc The filename: /etc is a directory And the permissions for you are : readable executable
除了以上注意之外,中括号使用方式与 test 几乎一模一样,只是中括号比较常用在 条件判断 if…then..fi 的情况中。
实践范例需求如下:
当执行一个程序的时候,要求用户选择 Y 或 N
如果用户输入 Y 或 y 时,就显示「Ok,continue」
如果用户输入 N 或 n 时,就显示「Oh,interrupt!」
如果不是以上规定字符,则显示「I don’t know what your choice is」
利用中括号、&&、|| 来达成
1 2 3 4 5 6 7 8 9 10 11 12 13 14
vi ans_yn.sh #!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo"Ok,continue" && exit 0 [ "${yn}" == "N" -o "${yn}" == "n" ] && echo"Oh,interrupt!" && exit 0 echo"I don't know what your choice is" && exit 0
[mrcode@study bin]$ ./print_info.sh a b ./print_info.sh 2 ./print_info.sh:行11: 2: 没有那个文件或目录 a b a b
以下是书上的写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
vi how_paras.sh #!/bin/bash # Program: # 输出脚本文件名,与相关参数信息 # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo"The script name is ==> $0" echo"Total parameter number is ==> $#" [ "$#" -lt 2 ] && echo"参数数量太少,比如大于等于 2 个" && exit 0 echo"Your whole parameter is ==> '$@'" echo"The 1st parameter ==> $1" echo"The 2nd parameter ==> $2"
输出测试
1 2 3 4 5 6 7 8 9 10 11
[mrcode@study bin]$ ./how_paras.sh The script name is ==> ./how_paras.sh Total parameter number is ==> 0 参数数量太少,比如大于等于 2 个
[mrcode@study bin]$ ./how_paras.sh a b The script name is ==> ./how_paras.sh Total parameter number is ==> 2 Your whole parameter is ==> 'a b' The 1st parameter ==> a The 2nd parameter ==> b
shift:造成参数变量位置偏移
先修改下上面的范例,how_paras.sh 先来看看效果什么是偏移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
vi how_paras.sh #!/bin/bash # Program: # Program shows the effect of shift function # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo"Total parameter number is ==> $#" echo -e "Your whole parameter is ==> '$@' \n"
shift# 进行第一次 一个变量的 shift echo"Total parameter number is ==> $#" echo -e "Your whole parameter is ==> '$@' \n"
shift 3 # 进行第二次 三个变量的 shift echo"Total parameter number is ==> $#" echo"Your whole parameter is ==> '$@'"
#!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn # [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo "Ok,continue" && exit 0 if [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]; then echo"Ok,continue" exit 0 fi
# [ "${yn}" == "N" -o "${yn}" == "n" ] && echo "Oh,interrupt!" && exit 0 if [ "${yn}" == "N" ] || [ "${yn}" == "n" ]; then echo"Oh,interrupt!" exit 0 fi echo"I don't know what your choice is" && exit 0
if [ 条件表达式 ]; then 做点啥 elif [ 条件表达式 ]; then 做点啥 else 做点啥 fi
改写 ans_yn.sh 脚本如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn # [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo "Ok,continue" && exit 0 if [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]; then echo"Ok,continue" exit 0 else echo"Oh,interrupt!" exit 0 fi echo"I don't know what your choice is" && exit 0
#!/bin/bash # Program: # Chek $1 is equal to "hello" # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
if [ "$1" == "hello" ]; then echo"Hello, how ary you?" elif [ "$1" == "" ]; then echo"You MUST input parameters, ex> {${0} someword}" else echo"The only parameter is 'hello', ex> {${0} hello}" fi
信息输出如下
1 2 3 4 5 6
[mrcode@study bin]$ ./hello-2.sh You MUST input parameters, ex> {./hello-2.sh someword} [mrcode@study bin]$ ./hello-2.sh hell The only parameter is 'hello', ex> {./hello-2.sh hello} [mrcode@study bin]$ ./hello-2.sh hello Hello, how ary you?
echo"现在开始检测当前主机上的服务" echo -e "www、ftp、mail、www 服务将被检测 \n" # 将 local Address 字段截取出来 datas=$(netstat -tuln | awk '{print $4}') testing=$(grep ":80"${datas}) if [ ! -z "${testing}" ]; then echo"www" fi testing=$(grep ":22"${datas}) if [ ! -z "${testing}" ]; then echo"ssh" fi testing=$(grep ":21"${datas}) if [ ! -z "${testing}" ]; then echo"ftp" fi testing=$(grep ":25"${datas}) if [ ! -z "${testing}" ]; then echo"mail" fi
#!/bin/bash # Program: # Using netstat and grep to detect www⽀~Assh⽀~Aftp and mail services # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
testing=$(grep ":80"${testfile}) if [ "${testing}" != "" ]; then echo"www is running in you system. " fi
testing=$(grep ":22"${testfile}) if [ ! -z "${testing}" ]; then echo"ssh is running in you system. " fi
testing=$(grep ":21"${testfile}) if [ ! -z "${testing}" ]; then echo"ftp is running in you system. " fi testing=$(grep ":25"${testfile}) if [ ! -z "${testing}" ]; then echo"mail is running in you system. " fi
vim cal_retired.sh #!/bin/bash # Program: # You input you demobilization date,I calculate how many days before you demobilize. # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
# 1. 告知用户程序的用途,并且告知应该如何输入日期格式 # 这个程序将尝试计算出,您的退伍日期还有多少天 echo"This program will try to calculate :" echo"How many days before your demobilization date..." read -p "Please input your demobilization date (YYYYMMDD ex>20200112):" date2
# 2. 测试判定,输入内容是否正确,使用正则表达式 date_d=$(echo${date2} | grep '[0-9]\{8\}') # 匹配 8 位数的字符串 if [ -z "${date_d}" ]; then # 您输入了错误的日期格式 echo"You input the wrong date format..." exit 1 fi
# 3. 开始计算日期 declare -i date_dem=$(date --date="${date_d}" +%s) # 退伍日期秒数 declare -i date_now=$(date +%s) # 当前日期秒数 declare -i date_total_s=$((${date_dem}-${date_now})) # 剩余秒数 # 需要注意的是:这种嵌套执行的时候,括号一定要嵌套对位置 declare -i date_d=$((${date_total_s}/60/60/24)) # 转换为日 # 中括号里面不能直接使用 < 这种符号 if [ "${date_total_s}" -lt 0 ]; then # 这里是用 -1 乘,得到是正数,标识已经退伍多少天了 echo"You had been demobilization before: $((-1*${date_d})) ago" else # 这里使用 总秒数 - 转换为日的变量(这里只是转换为了天),剩余数据转成小时 # 则计算到 n 天 n 小时 declare -i date_h=$(($((${date_total_s}-${date_d}*60*60*24))/60/60)) echo"You will demobilize after ${date_d} days and ${date_h} hours." fi
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200120 # 输入当天 You had been demobilization before: 0 ago
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200119 # 输入前一天 You had been demobilization before: 1 ago
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200121 # 输入明天 You will demobilize after 0 days and 8 hours.
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):2020^H^H3 # 输入错误的格式 You input the wrong date format...
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20300120 # 输入10 年后 You will demobilize after 3652 days and 8 hours.
[mrcode@study bin]$ ./show123.sh 只能输入 one、two、three [mrcode@study bin]$ ./show123.sh one one [mrcode@study bin]$ ./show123.sh two two [mrcode@study bin]$ ./show123.sh three three [mrcode@study bin]$ ./show123.sh three111 只能输入 one、two、three
利用 function 功能
函数功能,不用多说,可以被复用,优化程序结构,语法如下
1 2 3
functionfname(){ 程序段 }
TIP
由于 shell script 执行方式是由上而下,由左而右,因此 function 的代码一定要在程序的最前面
[mrcode@study bin]$ ./show123-2.sh one Your choice is one [mrcode@study bin]$ vim show123-2.sh [mrcode@study bin]$ ./show123-2.sh tow 只能输入 one、two、three [mrcode@study bin]$ ./show123-2.sh two Your choice is TWO
[mrcode@study bin]$ ./show123-3.sh one Your choice is 1 [mrcode@study bin]$ ./show123-3.sh two Your choice is 2 # 可以看到,这里给定参数 1,那么在里面获取 ${1},的时候就获取到了
[mrcode@study bin]$ ./show123-3.sh three Your choice is three # 在外部给定的是脚本中的变量 $1, 在内部也能获取到变量的具体内容 [mrcode@study bin]$ ./show123-3.sh threex 只能输入 one、two、three
read -p "请输入一个目录,将会检测该目录是否可读、可写、可执行:" dir # 判定输入不为空,并且目录存在 if [ "${dir}" == '' -o ! -d "${dir}" ]; then echo"The ${dir} is NOT exist in your system" exit 1 fi
# 获取该目录下的文件权限信息 filelist=$(ls ${dir}) for file in${filelist} do perm="" test -r "${dir}/${file}" && perm="${perm} readable" test -w "${dir}/${file}" && perm="${perm} writable" test -x "${dir}/${file}" && perm="${perm} executable" echo"The file ${dir}/${file}'s permission is ${perm}" done
[mrcode@study bin]$ ./what_to_eat.sh your may eat 太上皇 [mrcode@study bin]$ ./what_to_eat.sh your may eat 越油越好吃打呀 [mrcode@study bin]$ ./what_to_eat.sh your may eat 想不出吃什么 [mrcode@study bin]$ ./what_to_eat.sh
while [ "${eated}" -lt 3 ]; do check=$((${RANDOM} * ${eatnum} / 32767 + 1)) mycheck=0 # 当为 0 时,表示不重复 # 去重检查 if [ ${eated} -gt 0 ]; then# 当已选中至少一个店铺的时候,才执行 for i in $(seq 1 ${eated}) do if [ "${eatedcon[$i]}" == $check ]; then mycheck=1 fi done fi if [ ${mycheck} == 0 ]; then echo"your may eat ${eat[${check}]}" eated=$(( ${eated} + 1 )) eatedcon[${eated}]=${check}# 将已选中结果存储起来 fi done
# 范例 2:将 show_animal.sh 的执行过程全部列出来 [mrcode@study bin]$ sh -x show_animal.sh + PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:/home/mrcode/bin + export PATH + for animal in dog cat elephant + echo'There are dogs...' There are dogs... + for animal in dog cat elephant + echo'There are cats...' There are cats... + for animal in dog cat elephant + echo'There are elephants...' There are elephants...
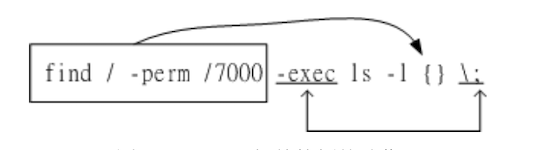
# 范例 1: 执行 find / -perm /7000 > /tmp/text.txt,立刻丢到背景去暂停 [root@study ~]# find / -perm /7000 > /tmp/text.txt find: '/proc/29541/task/29541/fd/5': No such file or directory find: '/proc/29541/task/29541/fdinfo/5': No such file or directory find: '/proc/29541/fd/6': No such file or directory find: '/proc/29541/fdinfo/6': No such file or directory ^Z [4]+ Stopped find / -perm /7000 > /tmp/text.txt
# 范例 2:让该工作在背景下进行,并且观察他 [root@study ~]# jobs ; bg %4; jobs [2]- Stopped vim ~/.bashrc [3] Stopped find / -print [4]+ Stopped find / -perm /7000 > /tmp/text.txt
# 最终的指令是如下的 [root@study ~]# kill -SIGHUP $(ps aux | grep 'rsyslogd' | grep -v 'grep' | awk '{print $2}') # 是否重启无法看通过看进程来知道,可以看日志 [root@study ~]# tail -5 /var/log/messages Mar 9 23:20:01 study systemd: Removed slice User Slice of root. Mar 9 23:30:01 study systemd: Created slice User Slice of root. Mar 9 23:30:01 study systemd: Started Session 19 of user root. Mar 9 23:30:01 study systemd: Removed slice User Slice of root. Mar 9 23:35:20 study rsyslogd: [origin software="rsyslogd" swVersion="8.24.0-38.el7" x-pid="1273" x-info="http://www.rsyslog.com"] rsyslogd was HUPed # 看上面,rsyslogd was HUPed 的字样,表示有重新启动
# 范例 2:强制终止所有以 httpd 启动的进程(其实当前没有该进程启动) [root@study ~]# killall -9 httpd httpd: no process found
# 范例 3:依次询问每个 bash 程序是否需要被终止 [root@study ~]# killall -i -9 bash Signal bash(7780) ? (y/N) n Signal bash(7835) ? (y/N) n Signal bash(9051) ? (y/N) n bash: no process found
# 这里都选择了 n,所以提示没有进程被找到,按下 y 就杀掉了
关于程序的执行顺序
CPU 是切换着执行进程,那么谁先执行?这个就要看进程的优先级 priority 与 CPU 排程(每个进程被 CPU 运行的演算规则)
Priority 与 Nice 值
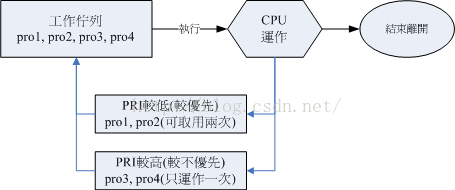
CPU 一秒钟可以运行多达数 G 的微指令次数,通过核心的 CPU 调度可以让各程序 被 CPU 所切换运行, 因此每个程序在一秒钟内或多或少都会被 CPU 执行部分的指令码。
如上图,有了优先级之后,高优先级的可用被执行两次,低优先级则执行 1 次,但是上图仅是示意图,并非高优先级的就会执行两次,Linux 给予进程一个优先执行序(priority PRI),PRI 值越低优先级越高,不过该值是由核心动态调整的,用户无法直接调整 PRI 值
1 2 3 4 5
[root@study ~]# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 0 R 0 7183 9051 0 90 10 - 12406 - pts/0 00:00:00 ps 4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su 4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash
由于 PRI 是动态调整的,用户无法干涉,但是可以通过 Nice 值来达到一定的优先级调整,Nice 就是上述中的 NI 值,一般来说 PRI 与 NI 的相关性 PRI(new)=PRI(old)+nice,虽然可以调整 nice 的值,由于 PRI 是动态调整的,所以不包装调整完之后,最终的 PRI 就会变低,优先级变高的
此外,必须要注意,nice 值范围
nice 值范围是 -20~19
root 可随意调整自己或他人进程的 Nice 值,且范围为 -20~19
一般使用者仅可调整自己进程的 Nice 值,且范围仅为 0~19(避免一般用户抢占系统资源)
一般使用者仅可将 nice 值越调越高;比如 nice 为 5,则未来仅能调整到大于 5;
那么调整 nice 值有两种方式:
一开始执行程序就立即给予一个特定的 nice 值:用 nice 指令
调整某个已经存在的 PID 的 nice 值:用 renice 指令
nice:新执行的指令给予新的 nice 值
1 2 3 4
nice [-n 数字] command
-n:后面接一个数值,数值范围 -20~19
1 2 3 4 5 6 7 8 9 10 11
# 范例 1: 用 root 给一个 nice 值为 -5,用于执行 vim,并观察该进程 [root@study ~]# nice -n -5 vim & [2] 30185 [root@study ~]# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su 4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash 4 T 0 30185 9051 0 85 5 - 10791 do_sig pts/0 00:00:00 vim 0 R 0 30652 9051 0 90 10 - 12407 - pts/0 00:00:00 ps # 原本的 bash PRI 为 90,所以 vim 预设为 90,这里给予 nice -5,所以最终 PRI 变成了 85 # 要注意:不一定正好变成 85,因为会动态调整的
[root@study home]# cd ~ [root@study ~]# umount /home/ umount: /home: target is busy. (In some cases useful info about processes that use the device is found by lsof(8) or fuser(1)) # 通过 fuser 知道有好几个进程在该目录下运行,可以通过如下的方式一个一个删除 [root@study ~]# fuser -mki /home/ /home: 7294c 7358c 7362c 7722c 8884c 19238c 19289c 19291c 19601c 25650c 25674c 25685c 25746c Kill process 7294 ? (y/N) # 以上指令有一个问题,颇为棘手,就是很容易杀到自己 bash 的进程,那么久直接把直接踢掉了 # 不知道这个这么排除掉是出方便的
# 3. 强制重新启动 crond,然后查看登录日志 [root@study ~]# systemctl restart crond [root@study ~]# tail /var/log/cron Mar 17 13:01:01 study run-parts(/etc/cron.hourly)[3889]: finished mcelog.cron Mar 17 13:10:01 study CROND[3972]: (root) CMD (/usr/lib64/sa/sa1 1 1) Mar 17 13:14:01 study crond[1400]: ((null)) Unauthorized SELinux context=system_u:system_r:system_cronjob_t:s0-s0:c0.c1023 file_context=unconfined_u:object_r:admin_home_t:s0 (/etc/cron.d/checktime) Mar 17 13:14:01 study crond[1400]: (root) FAILED (loading cron table) Mar 17 13:15:08 study crond[1400]: (CRON) INFO (Shutting down) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 13% if used.) Mar 17 13:15:08 study crond[4073]: ((null)) Unauthorized SELinux context=system_u:system_r:system_cronjob_t:s0-s0:c0.c1023 file_context=unconfined_u:object_r:admin_home_t:s0 (/etc/cron.d/checktime) Mar 17 13:15:08 study crond[4073]: (root) FAILED (loading cron table) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (running with inotify support) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (@reboot jobs will be run at computer's startup.) # 上述日志中有 Unauthorized 的信息,表示有错误,因为原本的安全本文与文件的实际安全本文无法搭配的缘故, # 信息还列出了 SELinux context 与 file_context 的信息,表示的确不匹配
SELinux 三种模式的启动、关闭与观察
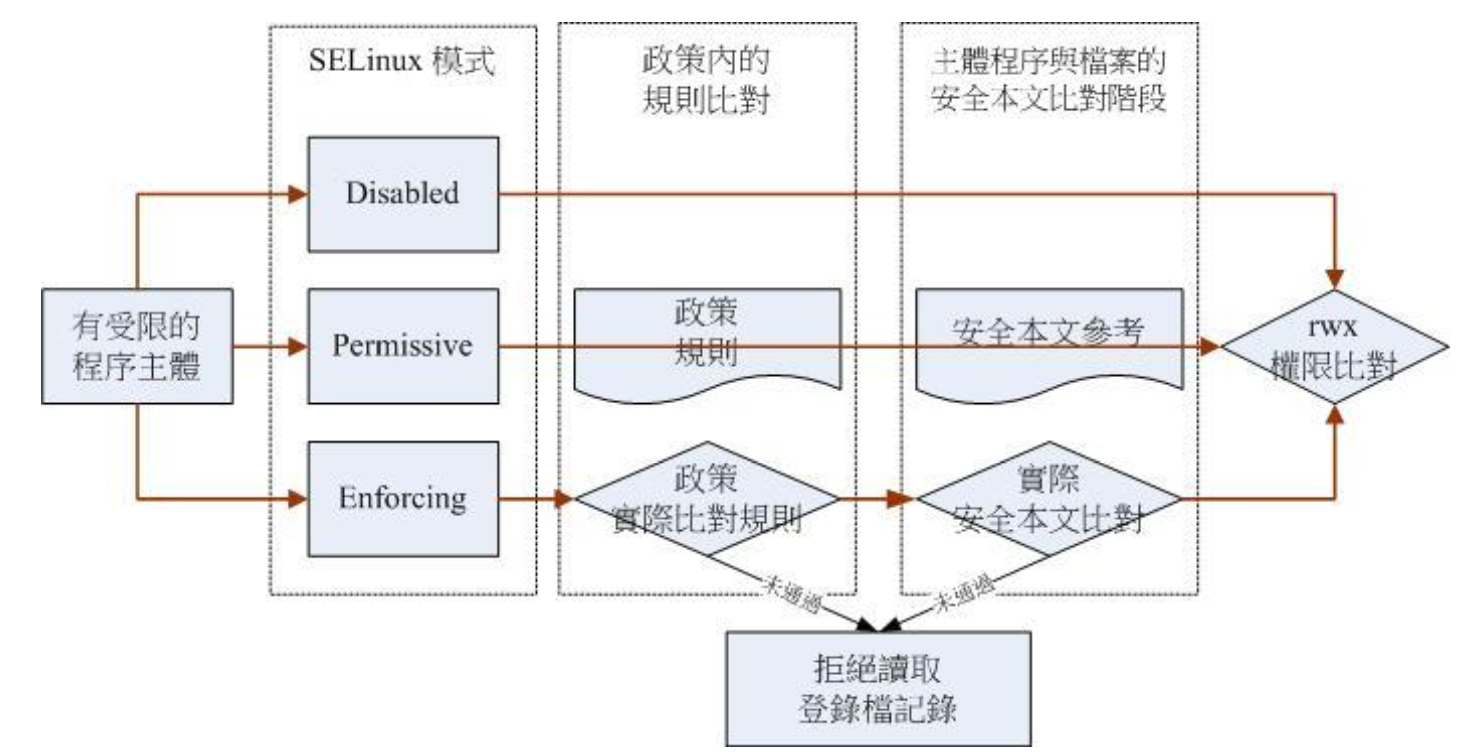
并非所有的 Linux distribution 都支持 SELinux,CentOS 7.x 本身就有支持 SELinux,所以你不需要自行编译 SELinux 到你的 Linux 核心中。目前 SELinux 是否启动有三种模式:
[root@study ~]# vim /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=enforcing # 可选择为上述 3 个 # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted # 可选值为上述 3 个
# 范例 1:查询所有的布尔值设置 [root@study ~]# getsebool -a abrt_anon_write --> off abrt_handle_event --> off abrt_upload_watch_anon_write --> on ... cron_can_relabel --> off # 这个与 cron 有关 cron_system_cronjob_use_shares --> off cron_userdomain_transition --> on ... httpd_anon_write --> off # 与网页 http 有关 httpd_builtin_scripting --> on httpd_can_check_spam --> off # 每一行都是一个规则
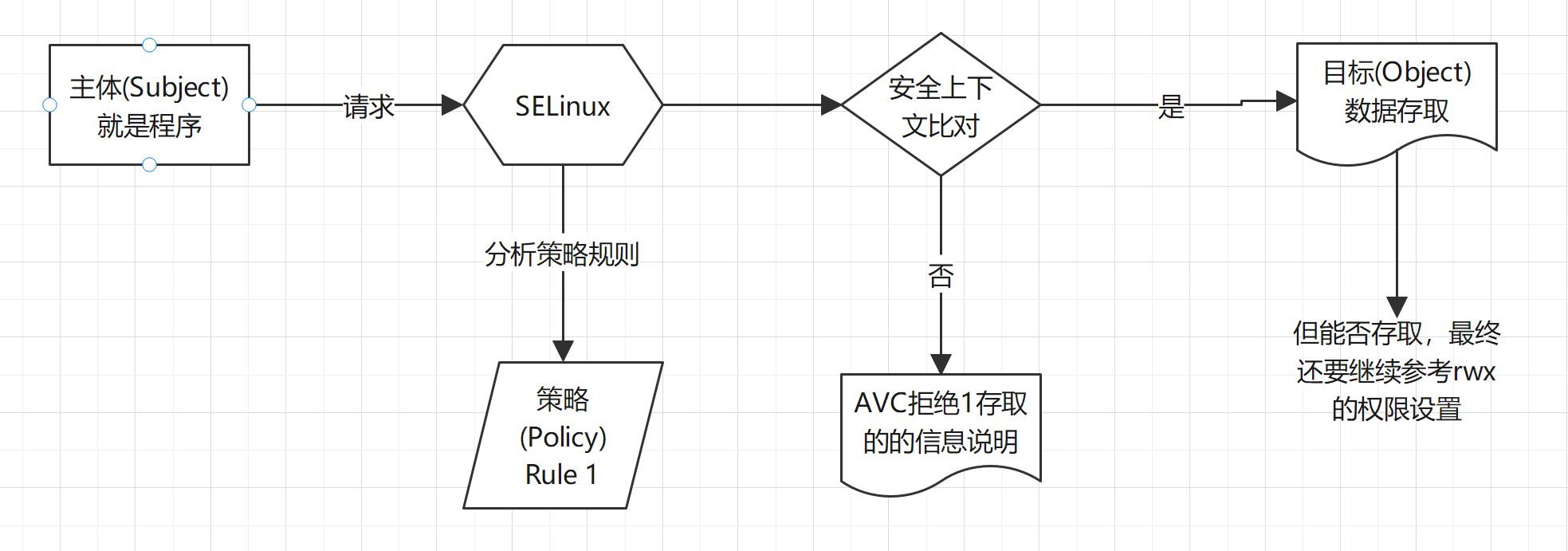
SELinux 各个规则规范的主体进程能够读取的文件 SELinux type 查询 seinfo、sesearch
# 范例 4:重新启动 crond 看看有没有正确启动 checktime [root@study ~]# systemctl restart crond [root@study ~]# tail /var/log/cron Mar 17 16:01:01 study CROND[5886]: (root) CMD (run-parts /etc/cron.hourly) Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5886]: starting 0anacron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5898]: finished 0anacron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5886]: starting mcelog.cron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5904]: finished mcelog.cron Mar 17 16:10:01 study CROND[5989]: (root) CMD (/usr/lib64/sa/sa1 1 1) Mar 17 16:12:48 study crond[4073]: (CRON) INFO (Shutting down) Mar 17 16:12:48 study crond[6068]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 62% if used.) Mar 17 16:12:49 study crond[6068]: (CRON) INFO (running with inotify support) Mar 17 16:12:49 study crond[6068]: (CRON) INFO (@reboot jobs will be run at computer's startup.) # 没有报错信息
从这里看来 restorecon 很方便,chcon 还是比较麻烦的
semanage 默认目录的安全性本文查询与修改
为什么 restorecon 可以恢复原本的 SELinux type 呢?那一定是有个地方在记录每个文件/目录的 SELinux 默认类型
# 3. 查看里面的文件内容 [root@study ~]# curl ftp://localhost/pub/sysctl.conf # sysctl settings are defined through files in # /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/. # # Vendors settings live in /usr/lib/sysctl.d/. # To override a whole file, create a new file with the same in # /etc/sysctl.d/ and put new settings there. To override # only specific settings, add a file with a lexically later # name in /etc/sysctl.d/ and put new settings there. # # For more information, see sysctl.conf(5) and sysctl.d(5).
[root@study ~]# vim /var/log/messages Aug 9 02:55:58 station3-39 setroubleshoot:SELinux is preventing /usr/sbin/vsftpd from lock access on the file /home/ftptest/test.txt. For complete SELinux messages. run sealert -l 3axxxxxxxx # 之类的字样,关键词就是 sealert ,执行这条命令 [root@study ~]# sealert -l 3axxxxxxxx SELinux is preventing /usr/sbin/vsftpd from lock access on the file /home/ftptest/test/txt. # 下面说有 47.5% 的几率是由于这个原因所发生,并且可以使用 setsebool 去解决的意思 ******* Plugin catchall_boolean(47.5 confidence) suggests ********
if you want to allow ftp to home dir ... Do setsebool -P ftp_home_dir 1
If you want to allow vsftpd to have read access on the test.txt file Then you need to change the label on test.txt Do # 下面这一条数据 # semanage fcontext -a -t FILE_TYPE 'test.txt' .... 很多数据 Then execute: restorecon -v 'test.txt'# 还有这一条数据,都是要参考的解决方案
If you believe that vsftpd should be allowed read access on the test.txt file by default. Then you should report this as a bug. You can generate a local policy module to allow this access. Do allow this access for now by executing: # ausearch -c 'vsftpd' --raw | audit2allow -M my-vsftpd # semodule -i my-vsftpd.pp
Additional Information: Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023 Target Context unconfined_u:object_r:var_t:s0 Target Objects test.txt [ file ] Source vsftpd Source Path /usr/sbin/vsftpd Port <Unknown> Host study.centos.mrcode Source RPM Packages Target RPM Packages Policy RPM selinux-policy-3.13.1-252.el7.noarch Selinux Enabled True Policy Type targeted Enforcing Mode Enforcing Host Name study.centos.mrcode Platform Linux study.centos.mrcode 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 Alert Count 2 First Seen 2020-03-17 22:46:17 CST Last Seen 2020-03-17 22:46:32 CST Local ID 88f08c09-c510-4518-bbcc-58bcee06ffb0
Raw Audit Messages type=AVC msg=audit(1584456392.386:979): avc: denied { read } for pid=10979 comm="vsftpd" name="test.txt" dev="dm-0" ino=35108539 scontext=system_u:system_r:ftpd_t:s0-s0:c0.c1023 tcontext=unconfined_u:object_r:var_t:s0 tclass=file permissive=0
# 1. 先处理 vsftpd 的配置文件,加入 port 的端口参数 [root@study ~]# vim /etc/vsftpd/vsftpd.conf listen_port=555
# 2. 重启服务,并查看日志 [root@study ~]# systemctl restart vsftpd Job for vsftpd.service failed because the control process exited with error code. See "systemctl status vsftpd.service" and "journalctl -xe"for details. [root@study ~]# grep sealert /var/log/messages Mar 17 23:03:23 study setroubleshoot: SELinux is preventing /usr/sbin/vsftpd from name_bind access on the tcp_socket port 555. For complete SELinux messages run: sealert -l e3e3dee0-83eb-4cb8-b894-8be590fee082
[root@study ~]# sealert -l e3e3dee0-83eb-4cb8-b894-8be590fee082 SELinux is preventing /usr/sbin/vsftpd from name_bind access on the tcp_socket port 555.
If you want to allow /usr/sbin/vsftpd to bind to network port 555 Then you need to modify the port type. Do # semanage port -a -t PORT_TYPE -p tcp 555 where PORT_TYPE is one of the following: certmaster_port_t, cluster_port_t, ephemeral_port_t, ftp_data_port_t, ftp_port_t, hadoop_datanode_port_t, hplip_port_t, isns_port_t, port_t, postgrey_port_t, unreserved_port_t.
If you believe that vsftpd should be allowed name_bind access on the port 555 tcp_socket by default. Then you should report this as a bug. You can generate a local policy module to allow this access. Do allow this access for now by executing: # ausearch -c 'vsftpd' --raw | audit2allow -M my-vsftpd # semodule -i my-vsftpd.pp
Additional Information: Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023 Target Context system_u:object_r:hi_reserved_port_t:s0 Target Objects port 555 [ tcp_socket ] Source vsftpd Source Path /usr/sbin/vsftpd Port 555 Host study.centos.mrcode Source RPM Packages vsftpd-3.0.2-25.el7.x86_64 Target RPM Packages Policy RPM selinux-policy-3.13.1-252.el7.noarch Selinux Enabled True Policy Type targeted Enforcing Mode Enforcing Host Name study.centos.mrcode Platform Linux study.centos.mrcode 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 Alert Count 1 First Seen 2020-03-17 23:03:20 CST Last Seen 2020-03-17 23:03:20 CST Local ID e3e3dee0-83eb-4cb8-b894-8be590fee082
Raw Audit Messages type=AVC msg=audit(1584457400.225:1008): avc: denied { name_bind } for pid=11443 comm="vsftpd" src=555 scontext=system_u:system_r:ftpd_t:s0-s0:c0.c1023 tcontext=system_u:object_r:hi_reserved_port_t:s0 tclass=tcp_socket permissive=0
那么[Ctrl]-d是什么呢?就是[Ctrl]与d按键的组合啊!这个组合按键通常代表着: “键盘输入结 束(End Of File, EOF 或 End Of Input)”的意思! 另外,他也可以用来取代exit的输入呢!例 如你想要直接离开命令行,可以直接按下[Ctrl]-d就能够直接离开了(相当于输入exit啊!)。
# 用 nl 列出 /etc/issue 的内容 # 默认不显示空行的行号 [root@study tmp]# nl /etc/issue 1 \S 2 Kernel \r on an \m
# 显示空行行号 [root@study tmp]# nl -b a /etc/issue 1 \S 2 Kernel \r on an \m 3 # 行号自动补 0,前面说的左右,看下面的对比,这个右是指,行号区域的左右 [root@study tmp]# nl -b a -n rz /etc/issue 000001 \S 000002 Kernel \r on an \m 000003 [root@study tmp]# nl -b a -n rn /etc/issue 1 \S 2 Kernel \r on an \m 3 [root@study tmp]# nl -b a -n ln /etc/issue 1 \S 2 Kernel \r on an \m 3
可翻页检视
more 一页一页翻动
1 2 3 4 5 6 7 8
[root@study tmp]# more /etc/man_db.conf # # # This file is used by the man-db package to configure the man and cat paths. # It is also used to provide a manpath for those without one by examining # their PATH environment variable. For details see the manpath(5) man page. # --More--(14%) # 重点在这一行,你的光标也会在这里等待你的指令
在 more 程序中,有几个按键可以按:
空格键(space):向下翻一页
Enter:向下翻一行
/字符串:在显示的内容中,向下搜索「字符串」这个关键词
q:立即离开 more
b 或 ctrl+b:向前翻页,只针对文件有用,对管线(管道 |)无用
less 一页一页翻动
1 2 3 4 5 6 7
# 使用指令后,就会进入到 less 环境 less /etc/man_db.conf
# This file is used by the man-db package to configure the man and cat paths. # It is also used to provide a manpath for those without one by examining
笔者工作中查看日志中有用得数据的时候,就是这个 less 了,但是只知道 shift+g 可以前进到最后一行去,原来 shift+g 其实就是输入了大写的 G 指令
资料摘取
可以将输出的资料做一个最简单的摘取,如去除文件前面几行(head)或则后面几行(tail), 需要注意的是, head 和 tail 都是以行为单位来进行摘取的
head 取出前面几行
1 2 3 4
head [-n number] 文件
-n:后面接数字,表示摘取几行
1 2 3 4 5 6 7 8 9 10 11 12
# 默认显示前 10 行,可以指定显示 20 行 head -n 20 /etc/man_db.conf
# 注意后面的数值为负数 # 该文件共有 131 行,这里是的意思就是,从尾部 -128 行,剩下的内容显示 # 也就是说,忽略显示后 128 行的数据 [root@study tmp]# head -n -128 /etc/man_db.conf # # # This file is used by the man-db package to configure the man and cat paths.
[root@study ~]# od -t oCc /etc/issue 0000000 134 123 012 113 145 162 156 145 154 040 134 162 040 157 156 040 \ S \n K e r n e l \ r o n 0000020 141 156 040 134 155 012 012 a n \ m \n \ 0000027
例如:mrcode 用户在 A 目录是具有 w 的权限(群组或其他人类型权限),这表示 mrcode 对该目录 内任何人简历的目录或则文件均可进行删除、更名、搬移等动作,但是将 A 目录加上了 SBIT 的权限时,则 mrcode 只能够针对自己建立的文件或目录进行删除、更名、搬移等动作,而无法删除他人的文件
TIP
这部分内容在后续章节「关于程序方面」的只是后,再回过头来看,才能明白讲的是什么
SUID、SGID、SBIT 权限设定
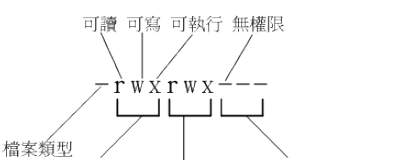
可以使用数值权限更改方法来设置,他们代表的数值是:
SUID:4
SGID:2
SBIT:1
下面演示具体这个数值加载哪里
1 2 3 4 5 6 7 8
[root@study tmp]# cd /tmp/ [root@study tmp]# touch test # -rwsr-xr-x 拥有者权限 rwx 都有分数为 7,后面的都是5,原本权限为 755 # 那么久在 755 前增加特殊权限数值即可 # 这里添加 SUID 的权限 [root@study tmp]# chmod 4755 test; ls -l test -rwsr-xr-x. 1 root root 0 10月 16 22:16 test
下面再来演示几个
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 添加 SUID + SGID 权限 [root@study tmp]# chmod 6755 test; ls -l test -rwsr-sr-x. 1 root root 0 10月 16 22:16 test
# 添加 SBIT [root@study tmp]# chmod 1755 test; ls -l test -rwxr-xr-t. 1 root root 0 10月 16 22:16 test
# 添加具有空的 SUID SGID 权限 # 这里出现了大写的 SST [root@study tmp]# chmod 7666 test; ls -l test -rwSrwSrwT. 1 root root 0 10月 16 22:16 test
上面最后一个例子出现了大写的三个特殊权限 S、S、T,这里是这样的,因为 666 的权限中 不包含 x 权限,所以当特殊权限出现在 x 中的时候(又不拥有 x)则会出现大写的,表示空。 SUID 表示该文件在执行的时候,具有文件拥有者的权限,但是文件拥有者都无法执行了, 哪里来的权限给其他人使用呢?
除了数值,还可以使用符号来处理:
SUID:u+s
SGID:g+s
SBIT:o+t
1 2 3 4 5 6 7 8 9
# 设置为 -rws--x--x [root@study tmp]# chmod u=rwxs,go=x test; ls -l test -rws--x--x. 1 root root 0 10月 16 22:16 test
# 在上面的权限基础上,增加 SGID 与 SBIT [root@study tmp]# chmod g+s,o+t test; ls -l test -rws--s--t. 1 root root 0 10月 16 22:16 test
观察文件类型 file
想知道某个文件的基本数据,例如属于 ASCII 或则是 data 文件、binary 、是否用到动态函数库(share library)等信息,可以使用 file 指令来检阅
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# ASCII 文本文件 [root@study tmp]# file ~/.bashrc /root/.bashrc: ASCII text
为什么需要拿到根目录呢?主要是为了安全,使用 tar 备份的数据可能会需要解压缩回来使用,在 tar 所记录的文件名(上面 -jtv 显示的文件名)就是解压缩后的实际文件名。如果拿到了根目录,则会在当前目录解压。比如现在在 /tmp ,解压后就变成 /tmp/etc/xxx;如果不拿掉根目录,源文件就被覆盖了
系统管理员的重要工作就是需要修改与设置某些重要软件的配置文件,因此至少得学会一种以上的文字模式下的文本编辑器。所有的 Linux distribution 上都有一套文本编辑器 vi,而且很多软件默认也是使用 vi 作为他们编辑器的接口。此外 vim 是进阶版的 vi,不但可以用不同颜色显示文字内容,还能够进行诸如 shell script、C program 等程序编辑功能,可以将 vim 视为一种程序编辑器
vi 与 vim
在 LInux 的世界中,绝大部分的配置文件都是以 ASCII 的纯文本形态存在的,因此利用简单的文字编辑软件就可以修改配置了
在 linux 的文本模式下的编辑器有:emacs、pico、nano、joe、vim 等,那么为何就要学 vi 呢?
为何要学 vim
为什么需要学习 vi ?原因如下:
所有 Unix Like 系统都会内置 vi 编辑器,其他的编辑器则不一定会存在
很多各别软件的编辑接口都会主动调用 vi (例如未来会讲解的 crontab、visudo、edquota 等指令)
vim 具有程序编辑的能,可以主动的以字体颜色辨别语法的正确性,方便程序设计
因为程序简单,编辑速度相当快
可以将 vim 视作是 vi 的进阶版,有语法高亮等功能。比如当使用 vim 编辑一个 shell script 脚本时,vim 会依据文件的扩展名或则是文件内的开头信息,判断该文件的内容而自动调用该程序的语法判断。甚至一些 Linux 基础配置文件内的语法,都能用 vim 来检查,例如第 7 章谈到的 /etc/fstab 文件内容
简单说,vi 是老式的文字处理器,vim 则是程序开发工具(https://www.vim.org/ 官网也是这样介绍的)而不是文字处理软件。因为 vm 里面加入了很多额外的功能,例如支持正规表示法的搜索架构、多文件编辑、区块复制等等。
[mrcode@study vitest]$ cd /tmp/vitest/ [mrcode@study vitest]$ vim man_db.conf # 使用 vim 进入文件后,然后按 ctrl + z 组合键,会退出来,并提示下面的信息 # 该组合键的作用是吧 vim man_db.conf 丢到背景去执行(后续在 16 章程序管理中会讲解) [1]+ Stopped vim man_db.conf
# 找到 .swp 的文件 [mrcode@study vitest]$ ls -al total 48 drwxrwxr-x. 2 mrcode mrcode 96 Oct 29 18:27 . drwxrwxrwt. 54 root root 4096 Oct 29 18:26 .. -rw-rw-r--. 1 mrcode mrcode 4862 Oct 29 17:13 man_db.conf -rw-r--r--. 1 mrcode mrcode 16384 Oct 29 18:27 .man_db.conf.swp
[1]+ Stopped vim man_db.conf # swp 文件还存在 [mrcode@study vitest]$ ls -al .man_db.conf.swp -rw-r--r--. 1 mrcode mrcode 16384 Oct 29 18:27 .man_db.conf.swp [1]+ Killed vim man_db.conf
# 再次进入该文件 [mrcode@study vitest]$ vim man_db.conf E325: ATTENTION # 错误代码 Found a swap file by the name ".man_db.conf.swp"# 有暂存当的存在,并显示相关信息 owned by: mrcode dated: Tue Oct 29 18:27:34 2019 file name: /tmp/vitest/man_db.conf # 这个暂存当实际属于哪个文件 modified: no user name: mrcode host name: study.centos.mrcode process ID: 2259 While opening file "man_db.conf" dated: Tue Oct 29 17:13:28 2019
# 下面说明可能发生这个错误的两个主要原因与解决方案 (1) Another program may be editing the same file. If this is the case, be careful not to end up with two different instances of the same file when making changes. Quit, or continue with caution. (2) An edit session for this file crashed. If this is the case, use ":recover" or "vim -r man_db.conf" to recover the changes (see ":help recovery"). If you did this already, delete the swap file ".man_db.conf.swp" to avoid this message.
其实,目前大部分的distribution 都以 vim 取代 vi 的功能了,因为 vim 具有颜色显示、支持许多程序语法(syntax)等功能
那么怎么分辨是否当前 vi 被 vim 取代了呢?
通过 alias 分辨
1 2 3 4 5 6 7 8 9 10 11
[mrcode@study vitest]$ alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias ls='ls --color=auto' alias vi='vim'# 可以看到这里 vi 调用的就是 vim aliaswhich='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde' # 原来上一个章节,笔者使用的不是 vi 而是 vim
通过界面分布
区块选择(Visual Block)
上面提到的简单 vi 操作过程中,几乎提到的都是以行为单位来操作的。那么如果想要搞定一个区块范围呢?如下面这个文件内容
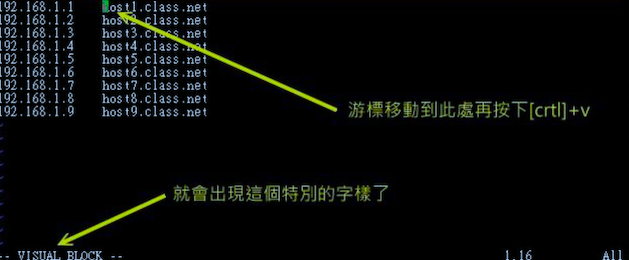
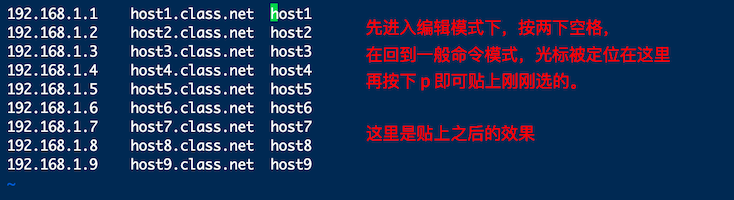
假设想要将 host1,host2 等复制,并且加到每一行的后面,即每一行的结果变成 192.168.1.1 host1.class.net host2.class.net... 。在传统或现代的窗口型编辑器似乎不容易达到这个需求,在 vim 中可以使用 Visual Block 区块功能。当按下 v 或 V 或则 ctrl+v 时,光标移动过的地方就会开始反白,按键含义如下
按键
含义
v
字符选择,会将光标经过的地方反白选择
V
行选择,会将光标经过的行反白选择
ctrl + v
区块选择,可以用长方形的方式选择
y
将反白的地方复制起来
d
将反白的地方删除
p
将刚刚复制的区块,在光标所在处贴上
实践练习区块怎么使用
多文件编辑
想象这样一个场景:要将刚刚 host 内的 IP 复制到 /etc/hosts 这个文件去,那么该如何编辑?我们知道在 vi 内可以使用 :r filename 来读入某个文件的内容,不过是将整个文件读入,如果只想要部分内容呢?这个时候就可以使用 vim 的多文件编辑功能了。使用 vim 后面同时接好几个文件来同时开启,相关按键有
按键
含义
:n
编辑下一个文件
:N
编辑上一个文件
:files
列出目前这个 vim 开启的所有文件
没有多文件编辑的话,实现将 A 文件内的 10 条消息移动到 B 文件中,通常需要开两个 vim 窗口来复制,但是无法在 A 文件下达 nyy 再跑到 B 文件去 p 的指令。
练习多文件编辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 开启两个文件,host 是我们刚刚编辑的那个 vi host /etc/hosts # 使用 files 指令查看编辑的文件有哪些 # 在一般指令模式下输入 :files 指令 :files 1 %a "host" line 1 2 "/etc/hosts" line 0 Press ENTER or typecommand to continue # 上面列出了两个,并告知按下任意键会回到 vim 的一般指令模式中
1. 回到一般指令模式中,跳转到第一行,输入 4yy 复制 4 行数据 2. 输入 :n 会来到第二个编辑的文件,也就是 /etc/hosts 3. 按下 G 跳转到最后一行,再按 p 贴上 4 行数据 4. 按下多次 u 来取消刚才的操作,也就是恢复 /etc/hosts 中数据到原样 5. 最终按下 :q 离开 vim 编辑器
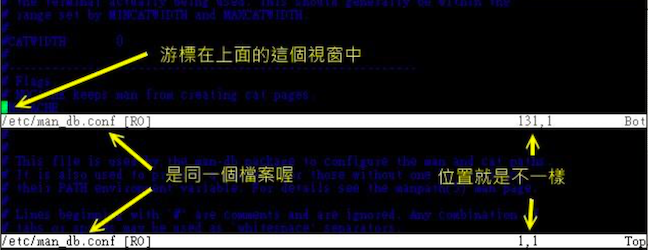
多窗口功能
在开始逐个小节前,先来想象两个情况:
当我有一个文件非常的大,查阅到后面的数据时,想要对照前面的数据,是否需要使用 ctrl + f 与 ctrl + b 或 pageup、pagedown 功能键来前后翻页对照?
我有两个需要对照看的文件,不想使用前一小节提到的多文件编辑功能
vim 有「分区窗口」的功能,在指令行模式输入 :sp filename即可,filename 存在则开启另一个文件,不存在则出现的是相同的文件内容
使用 vim /etc/man_db.conf,然后输入 「**:sp**」就会出现上下各一个窗口,两个窗口都是同一个文件内容
再次输入 :sp /etc/hosts 则会再分出来一个窗口
可以使用 ctrl + w + ↑ 和 ctrl + w + ↓ 组合键来切换窗口(笔者测试使用 ctrl + w 可以切换 ctrl + w + 箭头触发了宿主机的 ui 切换功能)
多窗口情况下的按键功能
按键
说明
:sp [filename]
开启一个新窗口,不加 filename 则默认打开当前文件,否则打开指定文件
ctrl + w + j/↓
使用方法:先按下 ctrl 不放,再按下 w 后放开所有的按键,再按下 j 或向下的箭头键,则光标可移动到下方的窗口
ctrl + w + k/上
同上
ctrl + w + q
就是 :q 结束离开。比如:想要结束下方的窗口,先使用 ctrl + w + j 移动到下方窗口,输入 :q 或则按下 ctrl + w + q 离开
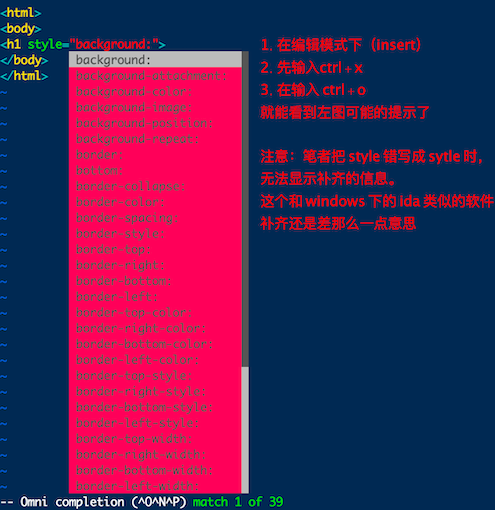
vim 的挑字补全功能
我们知道在 bash 环境下可以按下 tab 按钮来达成指令、参数、文件名的补全功能,还有 windows 系统上的各种程序编辑器,如 **notepad++**,都会提供:语法检验和根据扩展名来挑字的功能。
有没有发现:如果以 vim 软件来搜寻一个文件内部的某个字符串时,这个字符串会被反白,而下次我们再次以 vim 编辑这个文件时,该搜索的字符串反白的情况还是存在的,甚至于在编辑其他文件时,如果也存在该字符,也会主动反白。另外,当我们重复编辑同一个文件时,当第二次进入该文件时,光标竟然在上次离开的那一行上面
这是因为 vim 会主动将你曾经做过的行为记录在 ~/.viminfo 文件中,方便你下次可以轻松作业
此外,每个 distribution 对 vim 的预设环境都不太相同,例如:某些版本在搜寻关键词时并不会高亮度反白,有些版本则会主动帮你进行缩排的行为。这些其实都可以自定设置的,vim 的环境设置参数有很多,可以在一般模式下输入「**:set all**」来查询,不过可设置的项目太多了,这里仅列出一些平时比较常用的一些简单设置值,供你参考
vim 的环境设置参数
item
含义
:set nu、**:set nonu**
设置与取消行号
:set hlsearch、:set nohlsearch
hlsearch 是 high light search (高亮度搜索)。设置是否将搜索到的字符串反白设置。默认为 hlsearch
:set autoindent、**:set noautoindent**
是否自动缩排?当你按下 Enter 编辑新的一行时,光标不会在行首,而是在于上一行第一个非空格符处对齐
一般来说,如果我们按下 i 进入编辑模式后,可以利用退格键(baskpace)来删除任意字符的。但是某些 distribution 则不允许如此。此时,可以通过 backpace 来设置,值为 2 时,可以删除任意值;0 或 1 时,仅可删除刚刚输入的字符,而无法删除原本就已经存在的文字
:set all
显示目前所有的环境参数设置
:syntax on 、 :syntax off
是否依据程序相关语法显示不同颜色
:set bg=dark、**:set bg=light**
可以显示不同颜色色调,预设是 light。如果你常常发现批注的字体深蓝色是在很不容易看,就可以设置为 dark
总之这些常用的设置非常有用处,但是在行模式下设置只是针对当前打开的 vim 有效果;想要修改默认打开就生效的话,可以修改 ~/.vimrc 这个文件来达到(如果此文件不存在,请手工创建)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
vi ~/.vimrc " 该文件的注释是使用双引号表达 set hlsearch "高亮度反白 set backspace=2 "可随时用退格键删除 set autoindent "自动缩进 set ruler "可现实最后一列的状态 set showmode "左下角那一列的状态 set nu "在每一行的最前面显示行号 set bg=dark "显示不同的底色色调 syntax on "进行语法检验,颜色显示 # 保存后,再次打开最明显的就是自动显示行号了,可见是生效了的
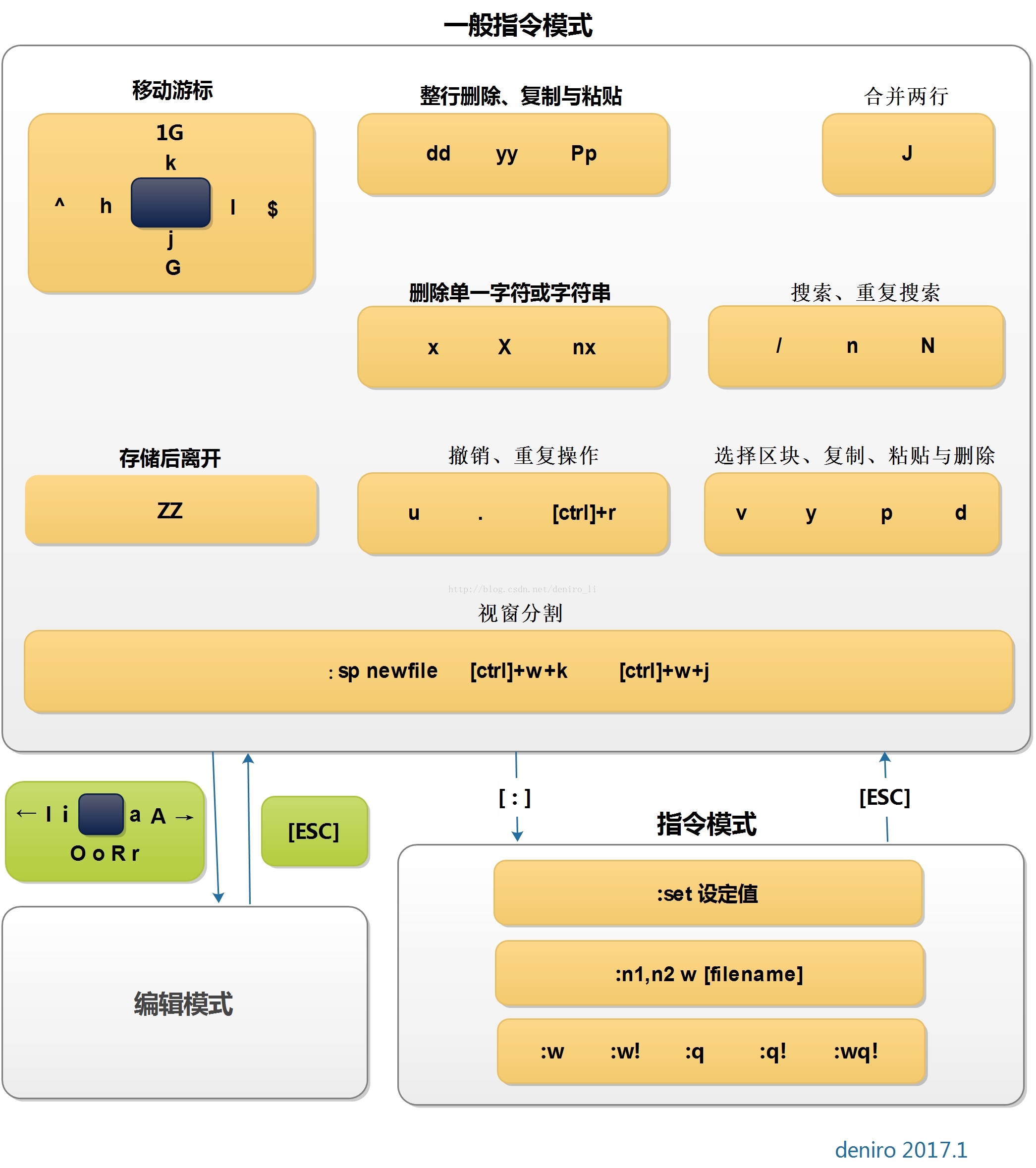
vim 常用指令示意图
其他 vim 使用注意事项
vim 功能很强大,但是上手不是那么容易,下面分享一些需要注意地方
中文编码的问题
在 vim 里面无法显示中文,那么你需要考虑:
Linux 系统默认支持的语系数据,与 /etc/locale.conf 有关
终端界面(bash)的语系;与 LANG、LC_ALL 几个参数有关
文件原本的编码
开机终端机的软件,例如在 GNOME 下的窗口
上面最重要的是第 3 和 4 点,只要这两点编码一致,就能不乱码;
可以使用如下的方式来暂时修改 tty 的语系(前面都讲过的)
1 2
LANG=zh_CN.UTF-8 export LC_ALL=zh_CN.UTF-8
DOS 与 Linux 的断行字符
cat 命令 中讲解过 DOS(windows 系统)建立的文件的特殊格式,发现 DOS 为 ^M$,而 linux 是 $,windows 是 CR(^M) 与 LF($) 两个符号组成的,Linux 是 LF ;对于 Linux 的影响很大
在 Linux 指令开始执行的时候,判断依据是 Enter 按键(也就是换行符,回车一下就会出现换行符),由于两个系统的换行符不一致,会导致 shell script 程序文件无法执行
每個系統管理員都應該至少要學會一種文字介面的文書處理器,以方便系統日常的管理行為。 在 Linux 上頭的文書處理軟體非常的多,不過,鳥哥還是建議使用 vi 這個正規的文書處理器。 這是因為 vi 幾乎在任何一個 Unix Like 的機器都存在,學會他,輕鬆很多啊! 而且後來的計畫也有推出 vim 這個 vi 的進階版本,可以用的額外功能更多了! vi 是未來我們進行 shell script 程式的編寫與伺服器設定的重要工具喔! 而且是非常非常重要的工具,一定要學會才行啊! ^_^
無論如何,要管理好 Linux 系統時,純文字的手工設定仍是需要的!那麼在 Linux 底下有哪些文書編輯器呢? 可多了~例如 vi, emacs, xemacs, joe, e3, xedit, kedit, pico .... 多的很~ 各家處理器各有其優缺點,您當然可以選擇任何一個您覺得適用的文書處理器來使用。不過,鳥哥還是比較建議使用 vi 啦!這是因為 vi 是 Unix Like 的機器上面預設都有安裝的軟體,也就是說,您一定可以接觸到這個軟體就是了。 另外,在較新的 distributions 上,您也可以使用較新較先進的 vim 這個文書處理器! vim 可以看做是 vi 的進階軟體,他可以具有顏色顯示,很方便程式開發人員在進行程式的撰寫呢!
簡單的來說, vi 是老式的文書處理器,不過功能已經很齊全了,但是還是有可以進步的地方。 vim 則可以說是程式開發者的一項很好用的工具,就連 vim 的官方網站 (http://www.vim.org) 自己也說 vim 是一個『程式開發工具』而不是文書處理軟體~^_^。 因為 vim 裡面加入了很多額外的功能,例如支援正規表示法的搜尋架構、多檔案編輯、區塊複製等等。 這對於我們在 Linux 上面進行一些設定檔的修訂工作時,是很棒的一項功能呢!
底下鳥哥會先就簡單的 vi 做個介紹,然後再跟大家報告一下 vim 的額外功能與用法呢!
1 2 3 4
[root@study ~]# cd /tmp/ [root@study tmp]# vi big5.txt # 把上面的内容保存到该文件中,然后使用这个文件来练习
但是这里还是需要再强调下:x window 与 web 接口的工具,它虽然功能强大,只是把所有利用到的软件整合到一起的一组程序而已,并非一个完整的套件,所以某些当你升级或则是使用其他套件管理模块(如 tarball 而非 npm 文件等)时,就会造成设置的困扰了。甚至不同的 distribution 所设计的 x window 接口也都不相同,这样也造成学习方面的困扰
而几乎各家 distribution 使用的 bash 都是一样的,如此一来几乎上能够轻轻松松的转换不同的 distribution
远程管理:文字接口就是比较快
Linux 的管理常常需要通过远程联机,而联机时文字接口的传输速度一定比较快,而且不容易出现断线或则是信息外流的问题,因此 shell 真的是得学习的一项工具,而且会让你更深入 Linux。
由于早年 Unix 年代,发展众多,所以 shell 依据发展者的不同就有许多版本,例如 Bourne SHell(sh)、在 Sun 里头预设的 CSHell、商业上常用的 K Shell、TCSH 等,每一种 Shell 都各有其特点。而 Linux 使用的这一种版本就称为「Bourne Again SHell(简称 bash),是 Bourne Shell 的增强版,也是基于 GNU 的架构下发展出来的
shell 简单历史
第一个流行的 shell 是由 Steven Bourne 发展出来的,所以称为 Bourne shell(简称 sh)。后来另一个广泛流传的 shell 是由柏克莱大学的 Bill Joy 设计依附于 BSD 版的 Unix 系统中的 shell,该 shell 语法类似 c 语言,所以才得名为 C shell(简称 csh)。 Sun 主要是 BSD 的分支之一,而且 Sun 主机势力庞大,所以 csh 流传广泛
假如我需要知道这个目录下的所有文件(包含隐藏文件)以及所有的文件属性,那么必须下达 ls -al这样的指令,可以通过 alias 来自定义命令取代上面的命令
1 2
alias lm='ls -al' # 这里使用 lm 取代了 ls -al
工作控制、前景背景控制(job control、foreground、background)
这部分在 第十六章 Linux 过程控制中详细讲解。使用前、背景可以让工作进行得更为顺利,而工作控制(jobs)用途则更广,可以让我们随时将工作丢到背景中执行,而不怕不小心使用了 ctrl + c 来停掉该程序。此外,可以在单一登录的环境中,达到多任务的目的
程序化脚本(shell scripts)
在 DOS 年代将一堆指令写在一起的批处理文件,在 Linux 下的 shell scripts 则发挥更强大的功能,可以将你平时管理系统常需要下达的连续指令写成一个文件,该文件并且可以通过对谈交互式的方式来进行主机的侦测工作。也可以借由 shell 提供的环境变量及相关指令来进行设计,以前在 DOS 下需要程序语言才能写的东西,在 Linux 下使用简单的 shell scripts 就可以实现,这部分在 第十二章 讲解
通配符(wildcard)
举例来说:想要知道 /usr/bin 下有多少以 X 开头的文件,使用ls -l /usr/bin/X* 就可以知道,此外还有其他可用的通配符
查询指令是否为 Bash shell 的内置命令:type
可以通过 man bash 查看联机帮助文档,内容很多,让你看几天几夜也无法看完,不过该 bash 的 man page 中,还有其他文件的说明,比如 cd 指令也在该 man page 内。在输入 man cd 时,最上方也出现一堆的指令介绍,这是由于方便 shell 的操作内置了这些指令
可以通过 type 指令来观察某个指令是否是内置指令
1 2 3 4 5 6 7 8 9 10
type [-tpa] name
- 不加任何选项与参数时,type 会显示出 name 是外部指令还是 bash 内置指令 - t:type 会将 name 以下面这些字眼显示出他的意义 file:表示为外部指令 alias:为别名 builtin:bash 内置指令 - p:如果后面接的 name 为外部指令时,才会显示完整文件名 - a:根据 PATH 变量定义的路径中,将含有 name 的指令都列出来,包含 alias
实践练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 查询 ls 这个指令是否为 bash 内置 # 未加任何参数,列出 ls 的最主要使用情况 [mrcode@study ~]$ type ls ls is aliased to `ls --color=auto' # 仅列出执行时的依据 [mrcode@study ~]$ type -t ls alias [mrcode@study ~]$ type -a ls ls is aliased to `ls --color=auto'# 最先使用 aliased ls is /usr/bin/ls # 还找到外部指令在 /bin/ls
# 查看 cd 的情况 [mrcode@study ~]$ typecd cd is a shell builtin# cd 是 shell 内置指令
# 练习 6:如何进入到你目前核心的模块目录? cd /lib/modules/3.10.0-1062.el7.x86_64/kernel/ # 由于每个 linux 能够拥有多个核心版本,且几乎 distribution 的核心版本都不相同 # 所以上面的指令无法通用,这个时候可以使用其他额外指令语法来达成 cd /lib/modules/`uname -r`/kernel cd /lib/modules/$(uname -r)/kernel
[mrcode@study kernel]$ ls -ld `locate crontab` -rw-------. 1 root root 541 Aug 9 07:07 /etc/anacrontab -rw-r--r--. 2 root root 451 Jun 10 2014 /etc/crontab -rwsr-xr-x. 1 root root 57656 Aug 9 07:07 /usr/bin/crontab # 这个是个目录,上面使用 -d 参数的效果就是,不输出该目录下的明细,只输出目录信息 drwxr-xr-x. 2 root root 21 Oct 4 18:25 /usr/share/doc/man-pages-overrides-7.7.3/crontabs -rw-r--r--. 1 root root 17738 Aug 9 08:47 /usr/share/doc/man-pages-overrides-7.7.3/crontabs/COPYING -rw-r--r--. 1 root root 2626 Aug 9 07:07 /usr/share/man/man1/crontab.1.gz -rw-r--r--. 1 root root 4229 Jun 10 2014 /usr/share/man/man1p/crontab.1p.gz -rw-r--r--. 1 root root 1121 Jun 10 2014 /usr/share/man/man4/crontabs.4.gz -rw-r--r--. 1 root root 1658 Aug 9 07:07 /usr/share/man/man5/anacrontab.5.gz -rw-r--r--. 1 root root 4980 Aug 9 07:07 /usr/share/man/man5/crontab.5.gz -rw-r--r--. 1 root root 2566 Aug 9 11:17 /usr/share/vim/vim74/syntax/crontab.vim
# 练习 9:如何简化一条命令 # cd /cluster/server/work/taiwan_2015/003 假设这条命令是经常用到的,但是特别长,如何简化? work="/cluster/server/work/taiwan_2015/003" cd work # 使用变量方式,来达成效果 # 该变量可以记录在 bash 的配置文件 「~/.bashrc」中,那么以后可随时使用 cd $work 进入该目录
# 范例 1:让用户由键盘输入一个内容,将该内容变成名为 atest 的变量 [mrcode@study ~]$ read atest this is a test# 光标闪烁,等待你的输入 [mrcode@study ~]$ echo${atest}# 这里打印刚刚用户输入的信息 this is a test
# 范例 2:提示使用者 30 秒内输入自己的大名,将该输入字符串作为名为 named 的变量内容 [mrcode@study ~]$ read -p "Please keyin your name: " -t 30 named Please keyin your name: mrcode # -p 的提示信息 [mrcode@study ~]$ echo${named} mrcode
# -t 30 ,如果 30 秒之后没有输入,则自动略过
declare 、 typeset
declare 或 typeset 都是声明变量的类型。如果使用 declare 后面并没有接任何参数,那么 bash 会主动将所有变量名称与内容显示出来,就好像使用 set 一样。语法如下
[mrcode@study ~]$ alias alias egrep='egrep --color=auto' alias fgrep='fgrep --color=auto' alias grep='grep --color=auto' alias l.='ls -d .* --color=auto' alias ll='ls -l --color=auto' alias lm='ls -al | more' alias ls='ls --color=auto' alias rm='rm -i' alias vi='vim' aliaswhich='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
在 root 用户下是没有 vi='vim' 的,一般用户会默认添加该别名
想取消别名可以使用 unalias 指令
1
unalias lm
例题:DOS 年代,列出目录与文件用 dir,清除屏幕用 cls,在 linux 如何达到这个效果?
1 2
[mrcode@study ~]$ alias cls='clear' [mrcode@study ~]$ alias dir='ls -l'
历史命令:history
前面提过 bash 有提供指令历史的服务,可以使用 history 来查询曾经下达过的指令
1 2 3 4
history [n] history [-c] history [-raw] histfiles
选项与参数:
n:数字,列出最近 n 条命令
c:将目前的 shell 中的所有 history 内容全部消除
a:将目前新增的 history 指令新增如 histfiles 中,若没有加 histfiles 则预设写入 ~/.bash_history
# 范例 1:列出目前内存内的所有 history 记忆 [mrcode@study ~]$ history 1 cd /root/ 2 sudo 3 sudo cd /root/ .... 中间省略 666 alias 667 alias cls='clear' 668 alias dir='ls -l' 669 dir 670 history
# 范例 2:列出们目前最近的 3 条指令 [mrcode@study ~]$ history 3 669 dir 670 history 671 history 3
# 使用范例 [mrcode@study ~]$ history 4 681 man rm 682 alias 683 man history 684 history 4 [mrcode@study ~]$ !681 # 执行第 681 条指令 man rm # 这里会显示具体执行的指令是什么 [mrcode@study ~]$ !! # 执行上一个指令 man rm [mrcode@study ~]$ !al # 从最新的历史指令开始搜索 al 开头的指令并执行他 alias
虽然好用,但是需要小心安全问题,尤其是 root 的历史记录,这是黑客的最爱。另外使用 history 配合 ! 曾经使用过的指令下达是很有效率的一个指令下达方式
在我们登陆主机的时候,屏幕上会有一些说明文字,告知我们的 Linux 版本之类的信息,还可以显示一些欢迎等信息。此外,我们习惯的环境变量、命令别名等,是否可以在登录后就主动帮我设置好?
这些设置又分为系统全局配置和个人账户级配置,仅是文件放置位置不同
路径与指令搜寻顺序
前面讲到过使用 alias 可以建立别名,比如创建了一个 ls 的别名,其实 ls 有少的指令,那么到底是哪一个会被选中执行呢?基本上,指令运行顺序可以这样看:
以相对、绝对路径执行命令,例如 /bin/ls 或 ./ls
由 alias 找到该指令来执行
由 bash 内置的指令来执行
通过 $PATH 这个变量的顺序搜索到第一个指令执行
举例来说:
/bin/ls:该指令运行后,没有颜色
ls:该指令运行后输出的内容有颜色,因为是使用别名 alias ls=‘ls --color=auto’
也可以使用 type -a ls 来查询指令搜寻的顺序
1 2 3 4 5 6 7
# 范例:设置 echo 的命令别名为 echo -n,然后观察 echo 执行的顺序 [mrcode@study ~]$ aliasecho='echo -n' [mrcode@study ~]$ type -a echo echo is aliased to `echo -n' echo is a shell builtin echo is /usr/bin/echo
[mrcode@study ~]$ cat > catfile << 'eof' > This is a test > Ok new stop > eof [mrcode@study ~]$ cat catfile This is a test Ok new stop # 只有两行数据,不会存在关键词一行 # 这里就有点类似判定结束标准输入的功能
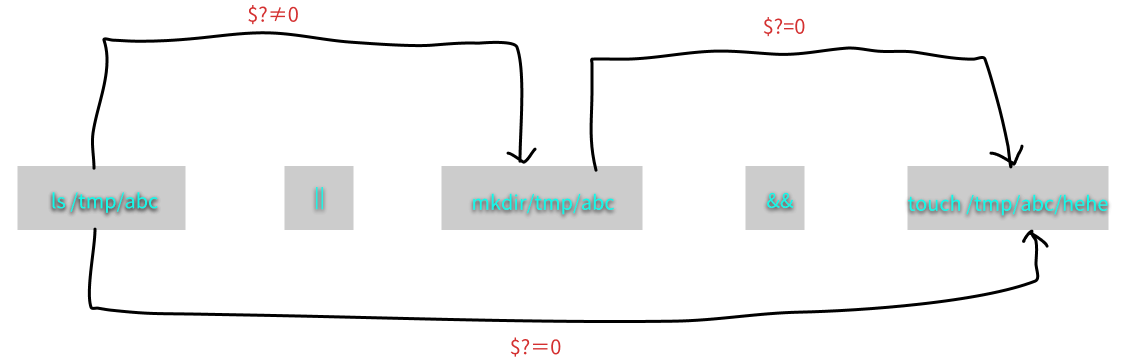
## 例题:以 ls 测试 /tmp/mrcode 是否存在,存在则显示 exist, 不存在则显示 not exist [mrcode@study ~]$ ls /tmp/mrcode && echo'exist' || echo'not exist' ls: cannot access /tmp/mrcode: No such file or directory not exist
## 例题:以 ls 测试 /tmp/mrcode 是否存在,存在则显示 exist, 不存在则显示 not exist [mrcode@study ~]$ ls /tmp/mrcode && echo'exist' || echo'not exist' ls: cannot access /tmp/mrcode: No such file or directory not exist
# 范例 1:将 last 中,有出现 root 的那一行找出来 [mrcode@study ~]$ last | grep 'root' root tty3 Sun Oct 6 23:16 - crash (22:40) root tty4 Fri Oct 4 22:48 - 22:48 (00:00) # 会发现 root 被高亮颜色了,我们时候 type 命令查看,发现被自动加上了 color 参数 [mrcode@study ~]$ type grep grep is aliased to 'grep --color=auto'
# 范例 2:与 范例 1 相反,不要 root 的数据 [mrcode@study ~]$ last | grep -v 'root' mrcode pts/1 192.168.0.105 Mon Dec 2 01:25 still logged in mrcode pts/0 192.168.0.105 Mon Dec 2 01:25 still logged in mrcode pts/1 192.168.0.105 Mon Dec 2 00:21 - 01:12 (00:51) reboot system boot 3.10.0-1062.el7. Fri Oct 4 18:47 - 03:43 (08:56)
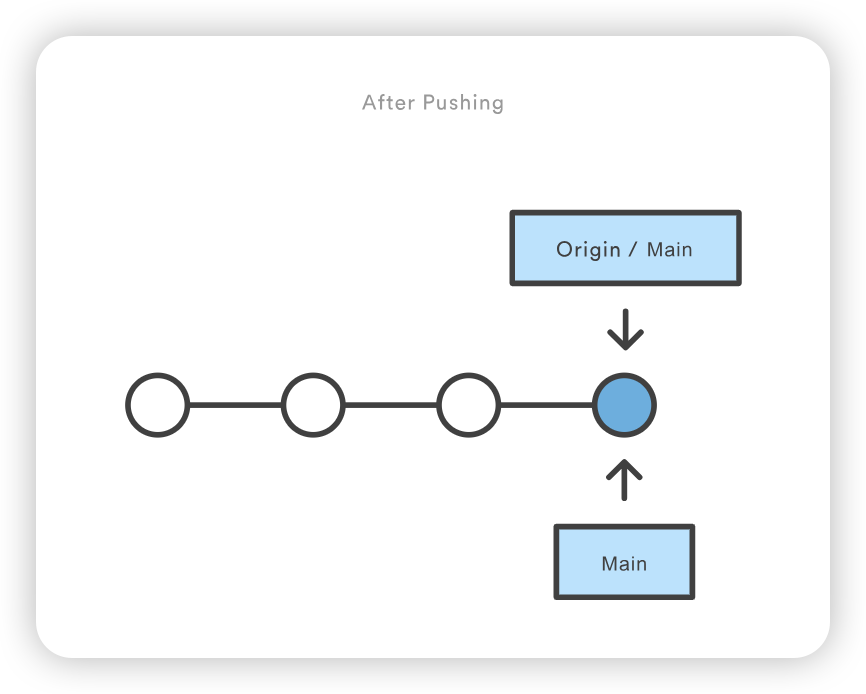
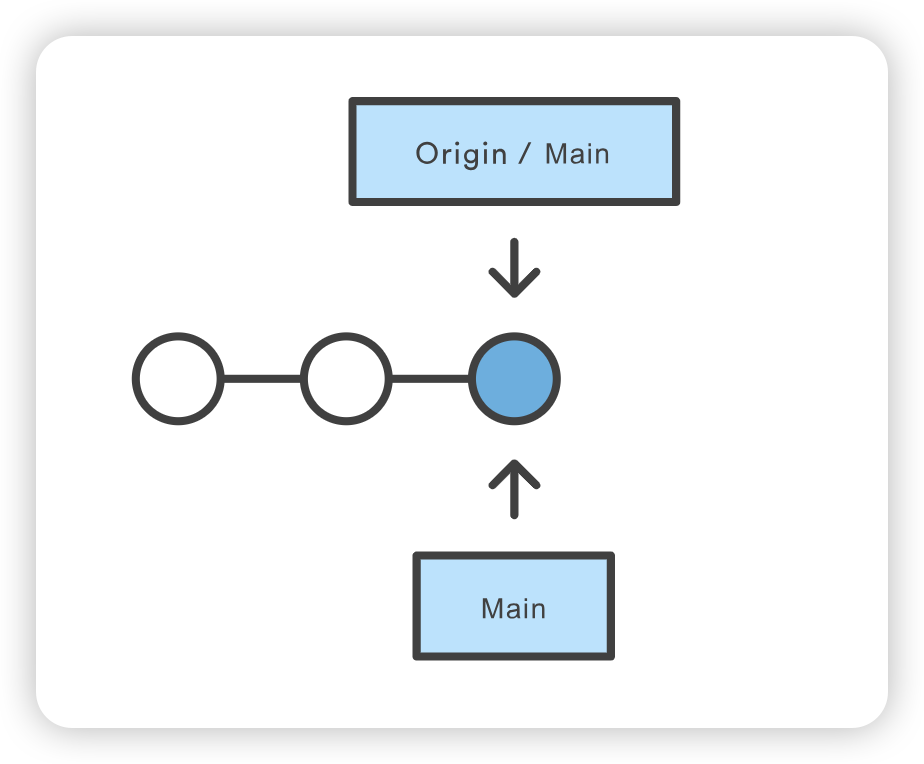
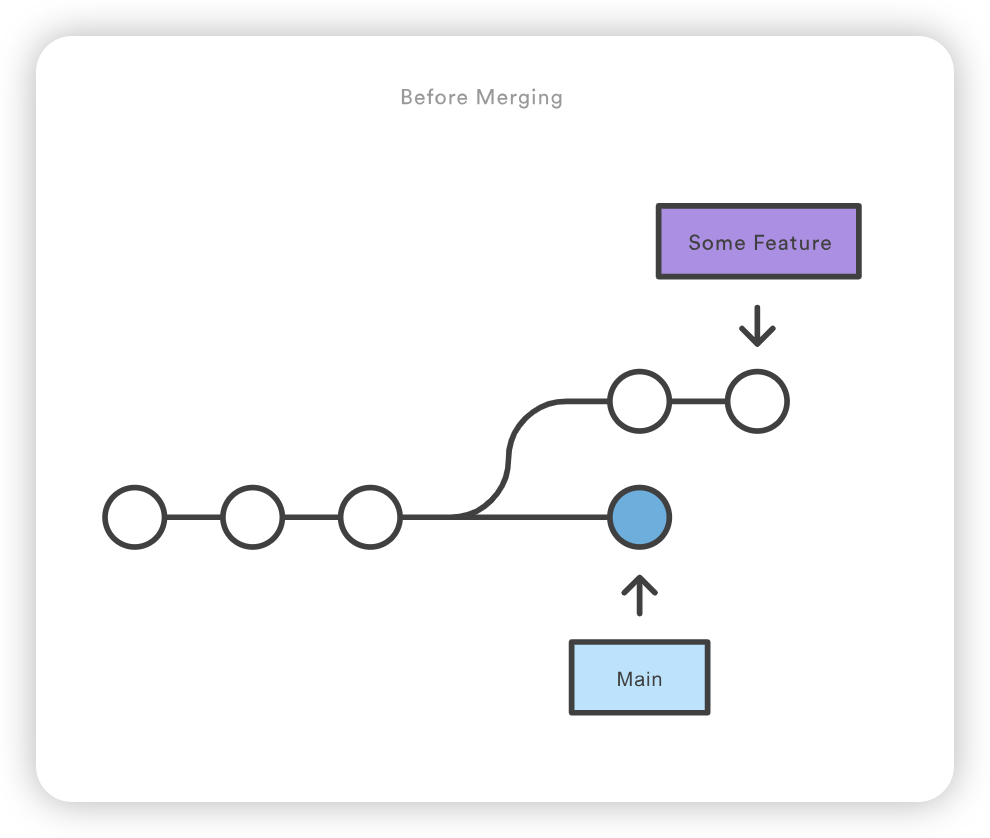
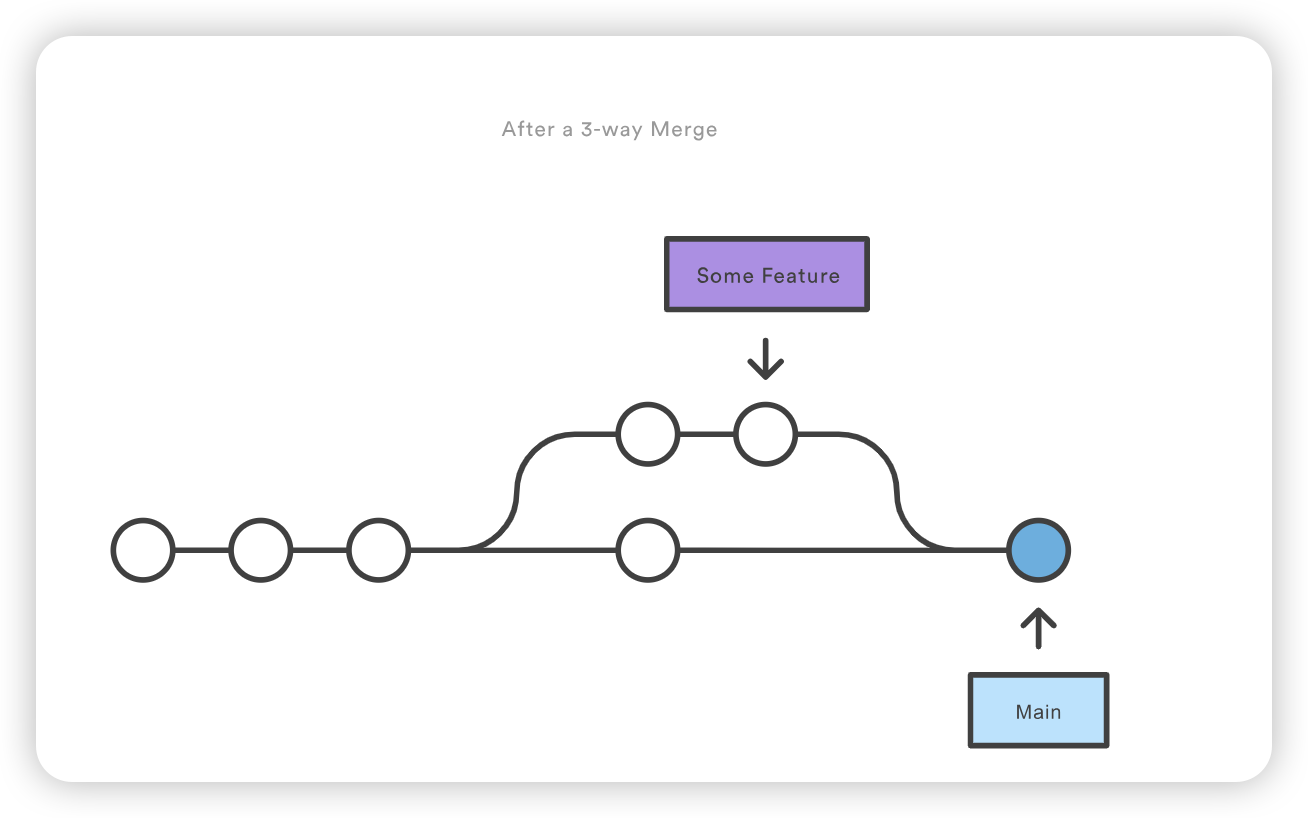
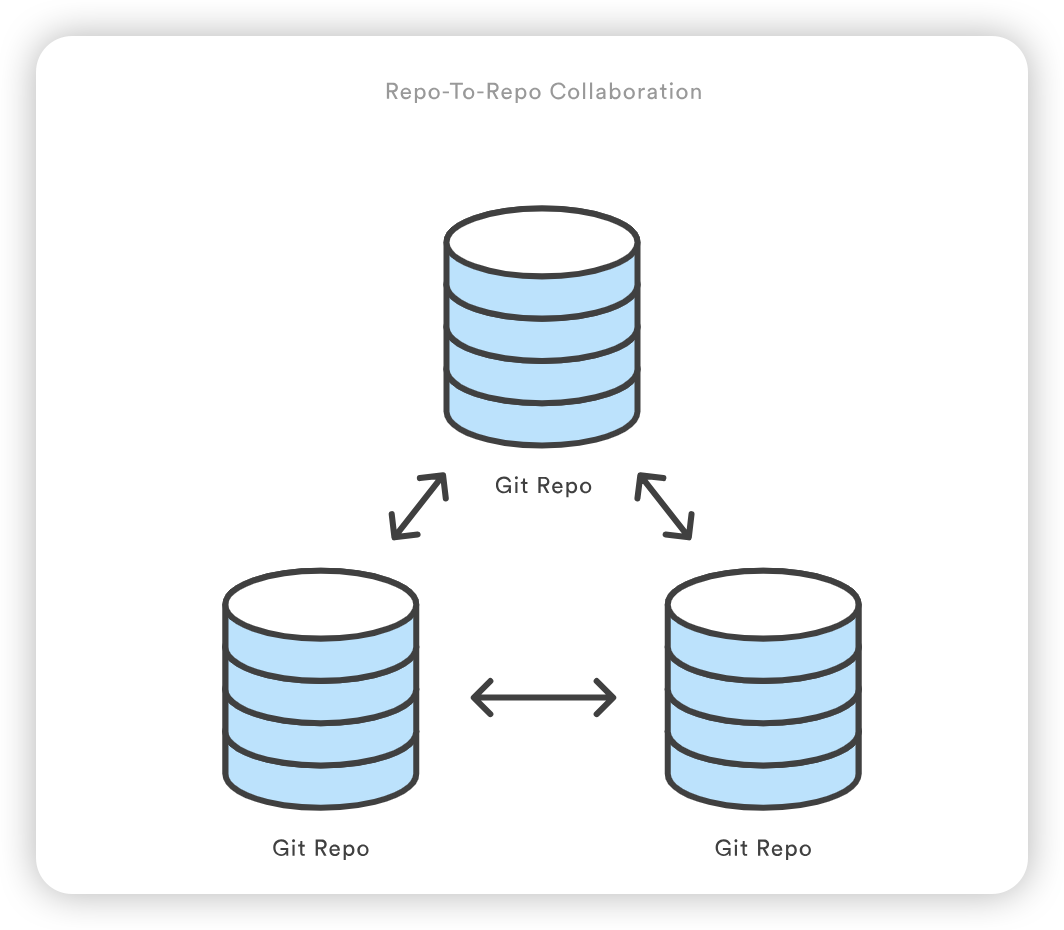
show 子命令可附加到 git remote,以提供远程配置的详细输出。该输出将包含与远程相关联的分支列表,以及用于获取和推送的端点。
1 2 3 4 5 6 7 8 9 10 11
git remote show upstream * remote upstream Fetch URL: https://bitbucket.com/upstream_user/reponame.git Push URL: https://bitbucket.com/upstream_user/reponame.git HEAD branch: main Remote branches: main tracked simd-deprecated tracked tutorial tracked Local ref configured for'git push': main pushes to main (fast-forwardable)
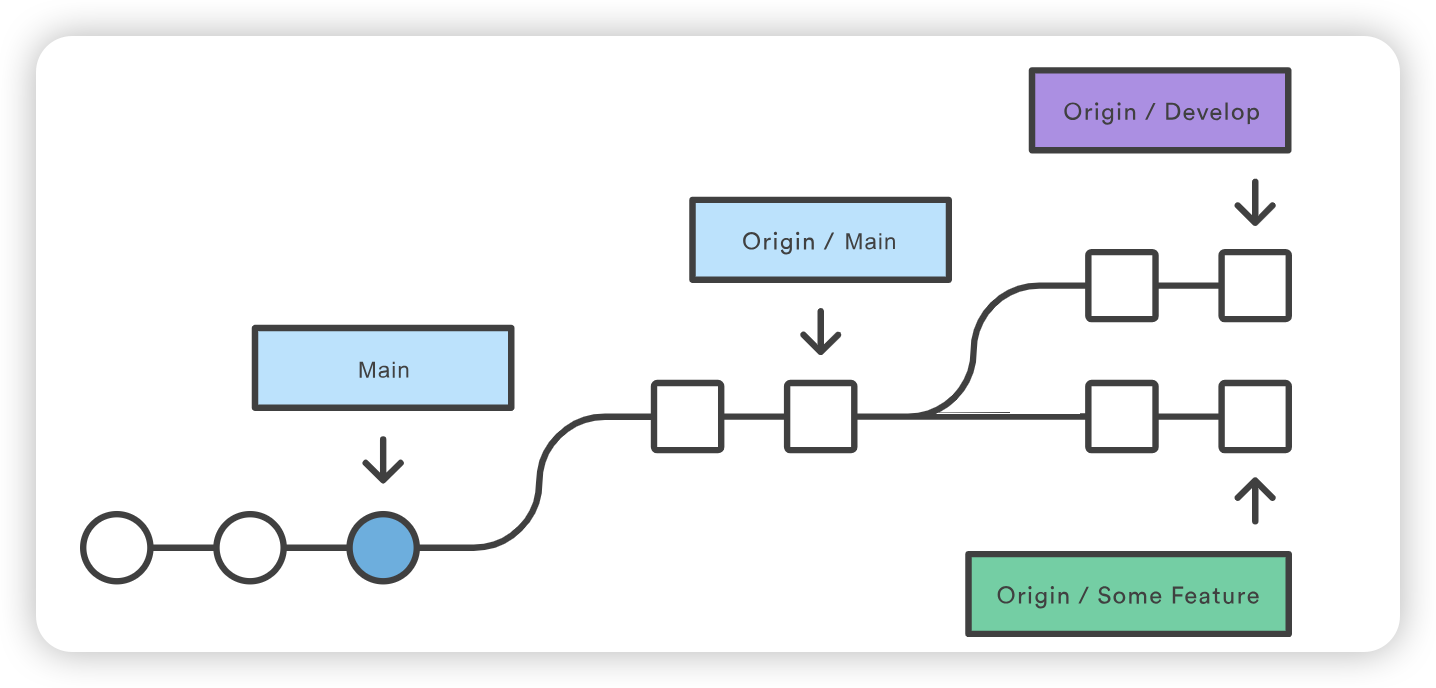
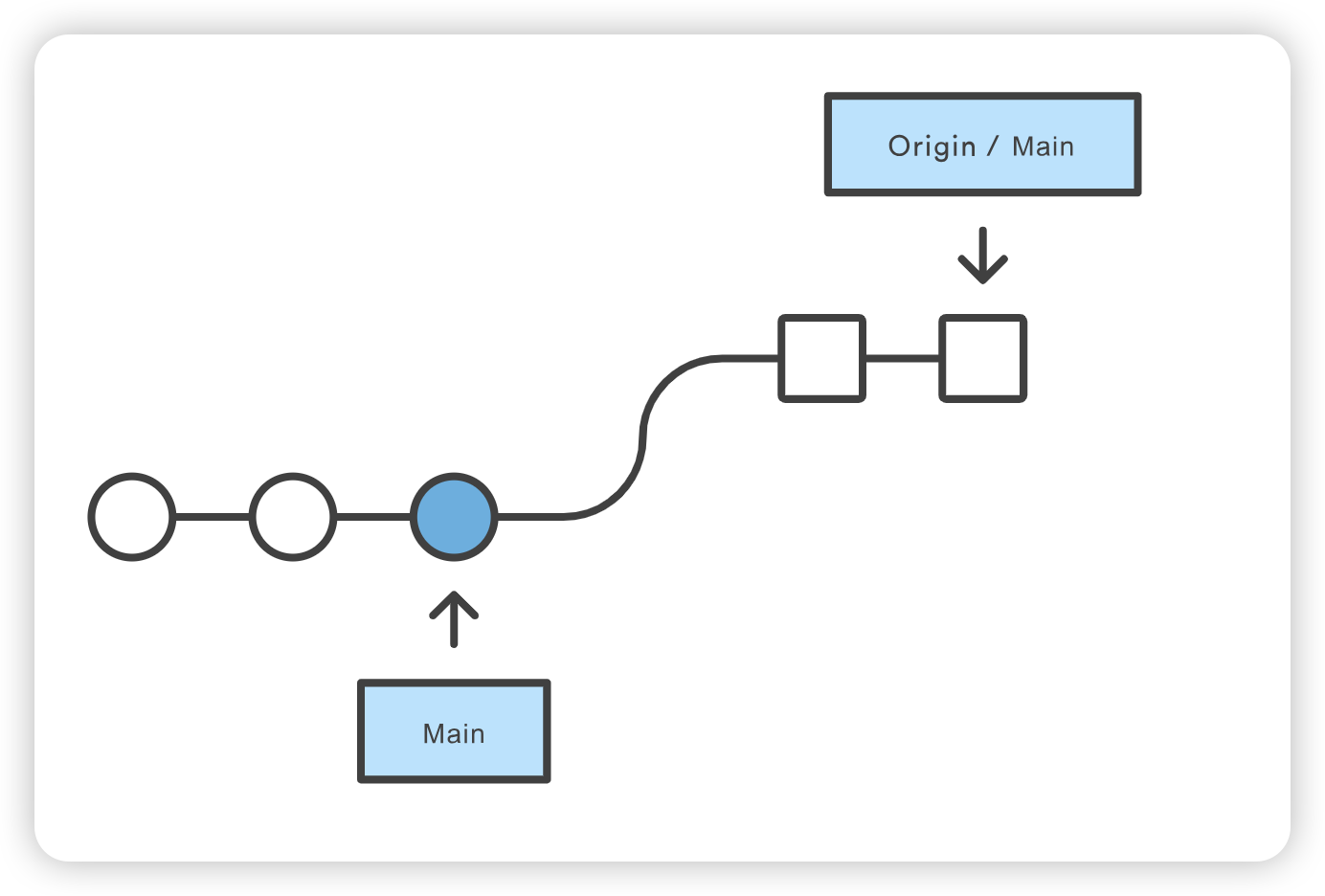
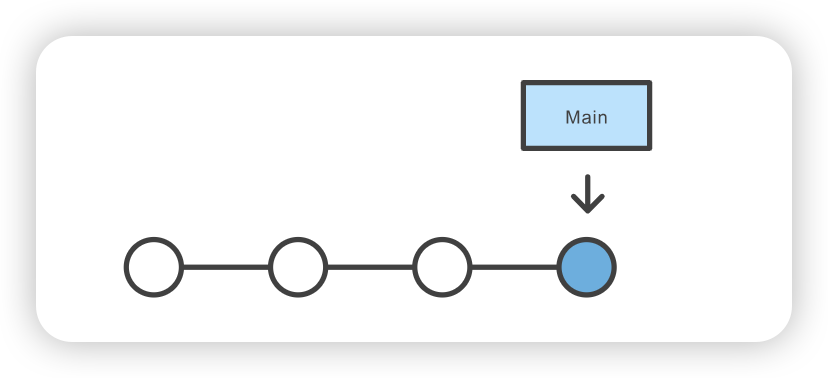
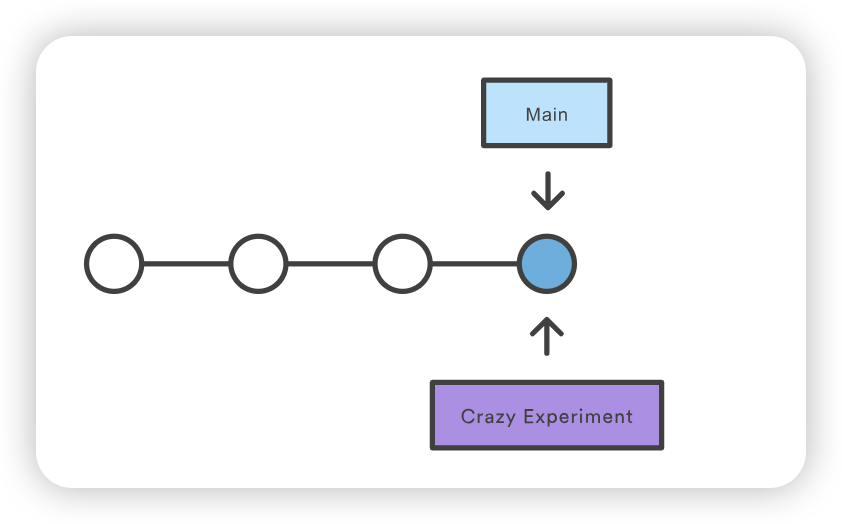
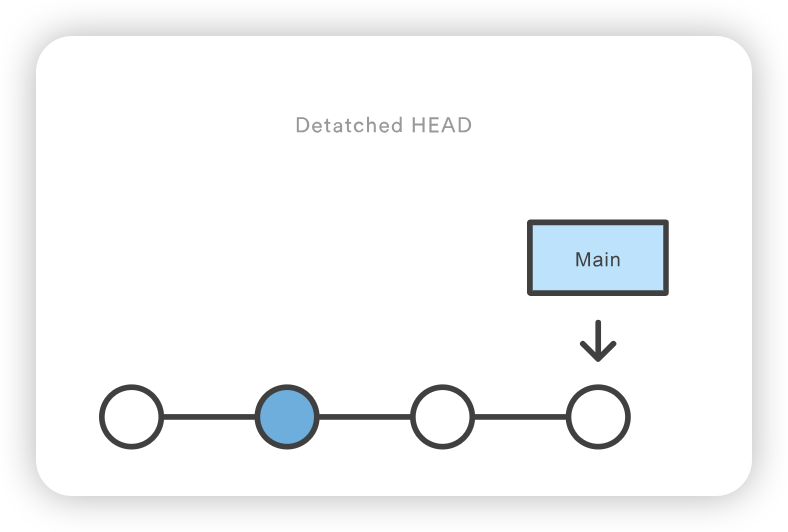
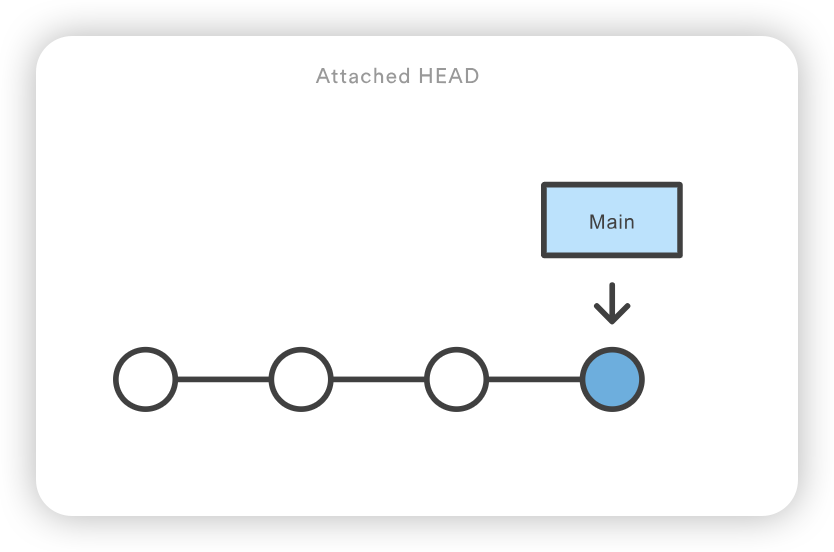
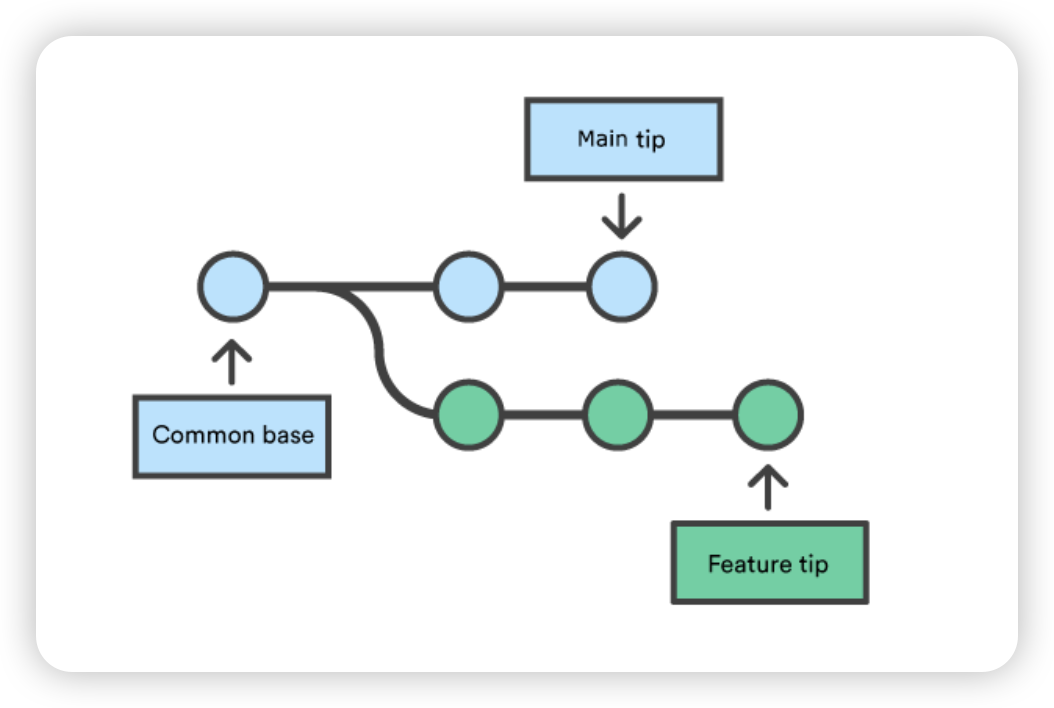
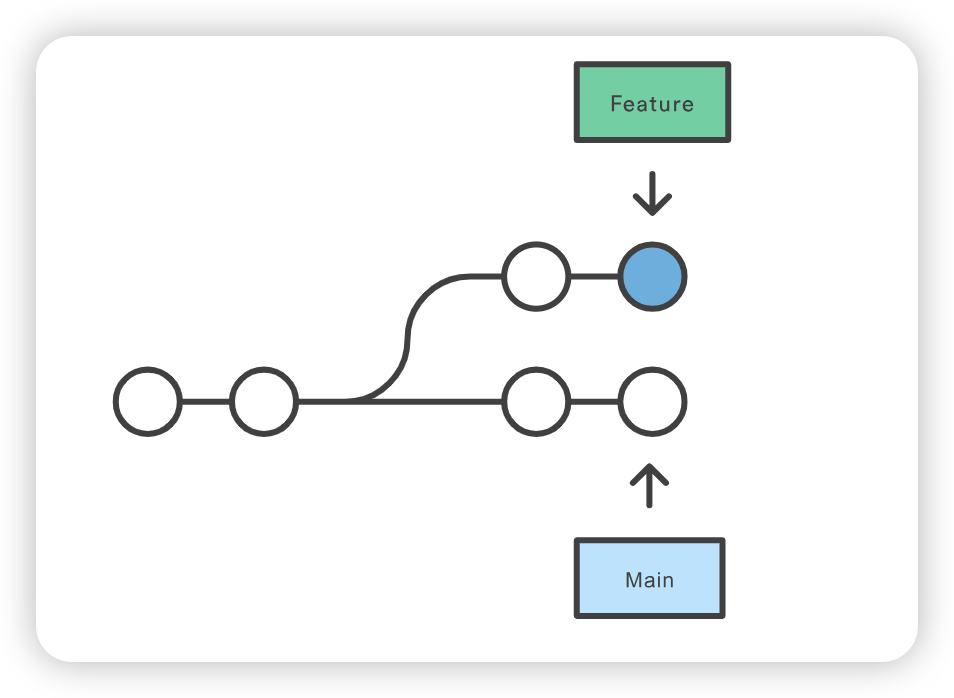
git checkout coworkers/feature_branch Note: checking out coworkers/feature_branch'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -b with the checkout command again. Example: git checkout -b <new-branch-name>
该检出操作的输出结果显示,我们处于分离的 HEAD 状态。这是意料之中的,这意味着我们的 HEAD ref 指向的 ref 与本地历史不一致。由于 HEAD 指向的是coworkers/feature_branch ref,我们可以从该 ref 创建一个新的本地分支。分离的 HEAD “输出向我们展示了如何使用 git checkout 命令来做到这一点:
Start a new feature git checkout -b new-feature main # Edit some files git add <file> git commit -m "Start a feature" # Edit some files git add <file> git commit -m "Finish a feature" # Develop the main branch git checkout main # Edit some files git add <file> git commit -m "Make some super-stable changes to main" # Merge in the new-feature branch git merge new-feature git branch -d new-feature
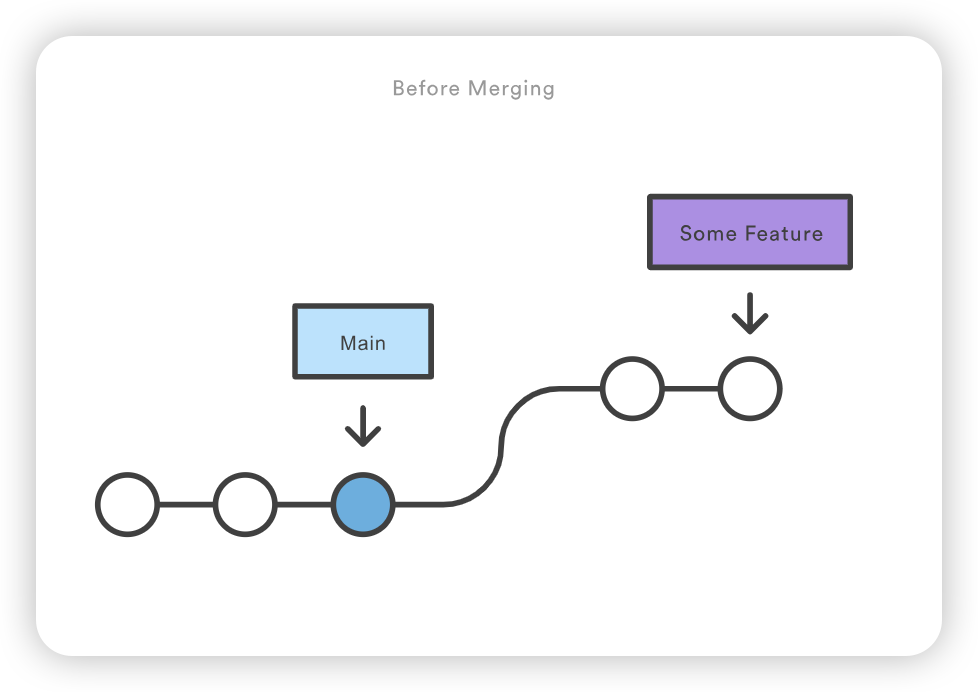
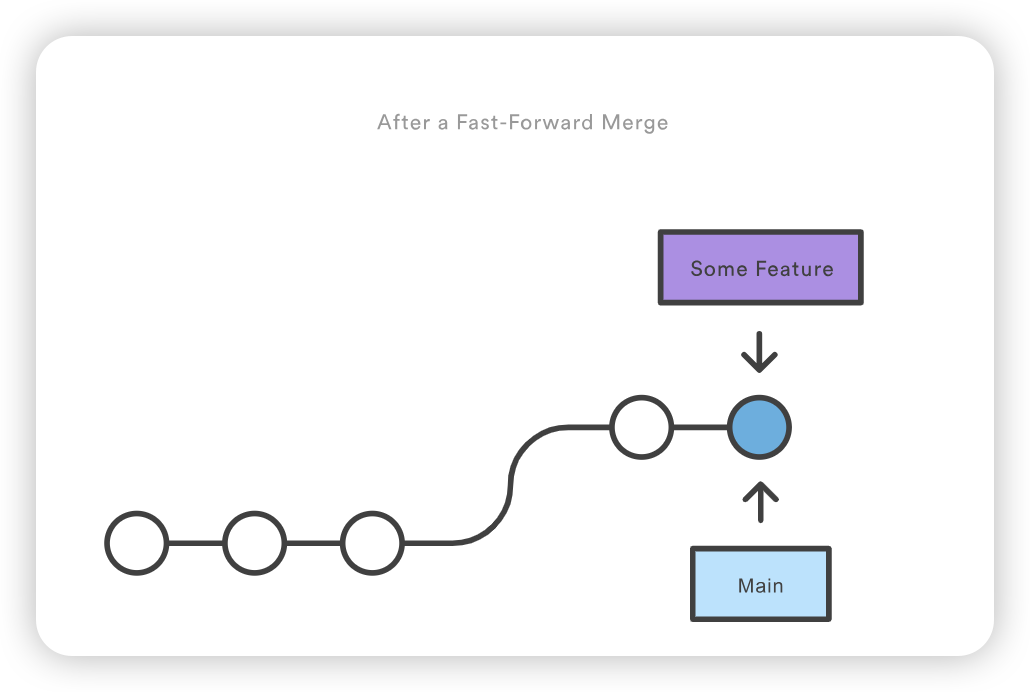
请注意,Git 不可能执行快进合并,因为没有办法在不回溯的情况下将 main 上移到 new-feature。
对于大多数工作流程来说,new-feature 会是一个更大的特性分支,需要很长时间才能开发完成,这也是新提交会同时出现在 main 上的原因。如果您的特性分支和上面例子中的分支一样小,您最好将其重定向到主分支,然后进行快进合并。这样可以防止多余的合并提交扰乱项目历史。
here is some content not affected by the conflict <<<<<<< main this is conflicted text from main ======= this is conflicted text from feature branch >>>>>>> feature branch;
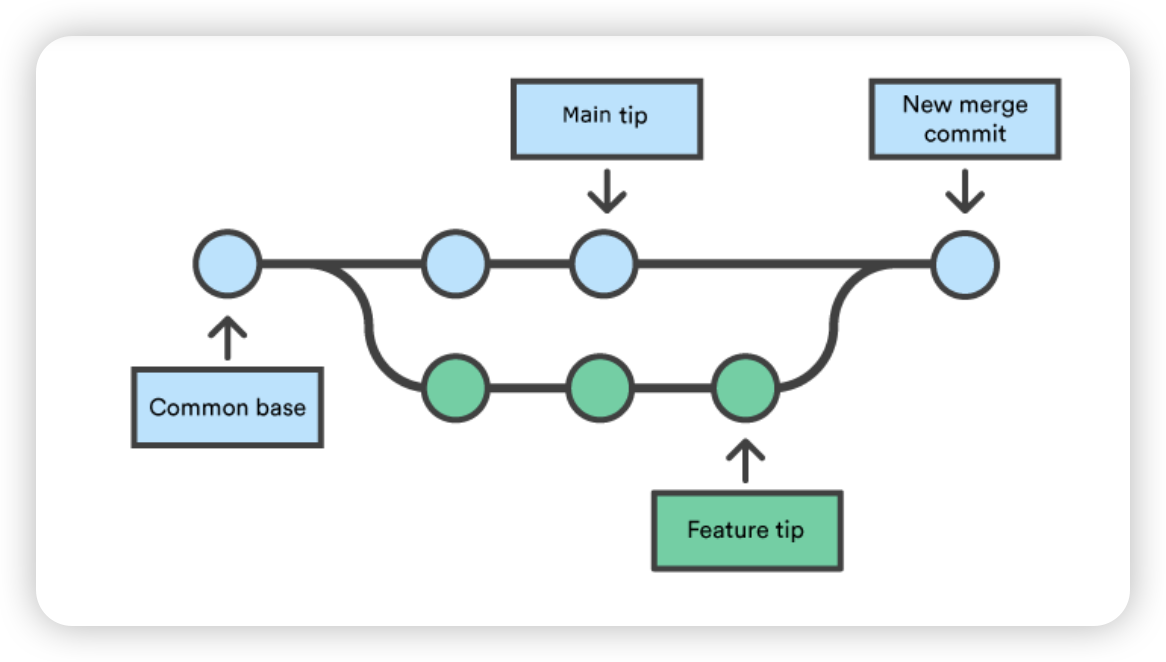
版本控制系统主要是管理多个分布式作者(通常是开发人员)之间的贡献。有时,多个开发人员可能会尝试编辑相同的内容。如果开发人员 A 试图编辑开发人员 B 正在编辑的代码,就可能发生冲突。为了减少冲突的发生,开发者会在独立的分支中工作。git merge命令的主要职责就是合并不同的分支,并解决任何冲突的编辑。
$ git checkout -b new_branch_to_merge_later $ echo"totally different content to merge later" > merge.txt $ git commit -am"edited the content of merge.txt to cause a conflict" [new_branch_to_merge_later 6282319] edited the content of merge.txt to cause a conflict 1 file changed, 1 insertion(+), 1 deletion(-)
$ git merge new_branch_to_merge_later Auto-merging merge.txt CONFLICT (content): Merge conflict in merge.txt Automatic merge failed; fix conflicts and then commit the result.
BOOM 💥. 冲突出现了。感谢 Git 让我们了解到这一点!
如何确定合并冲突
正如我们在下面的例子中所体验到的,Git 会产生一些描述性输出,让我们知道发生了冲突。我们可以通过运行 git status 命令进一步了解情况
1 2 3 4 5 6 7 8 9 10
$ git status On branch main You have unmerged paths. (fix conflicts and run "git commit") (use "git merge --abort" to abort the merge)
Unmerged paths: (use "git add <file>..." to mark resolution)
both modified: merge.txt
git status 的输出显示,由于冲突,存在未合并的路径。现在,merge.text 文件处于修改状态。让我们检查一下文件,看看修改了什么。
1 2 3 4 5 6 7
$ cat merge.txt <<<<<<< HEAD this is some content to mess with content to append ======= totally different content to merge later >>>>>>> new_branch_to_merge_later
在这里,我们使用 cat 命令输出了 merge.txt 文件的内容。我们可以看到一些奇怪的新内容
<<<<<<< HEAD
=======
>>>>>>> new_branch_to_merge_later
将这些新线视为 “冲突分界线”。======= 行是冲突的 “中心”。中心和 <<<<<<< HEAD 行之间的所有内容都是 HEAD ref 指向的当前分支 main 中存在的内容。或者,中心线和 >>>>>>> new_branch_too_merge_later 之间的所有内容都是合并分支中的内容。
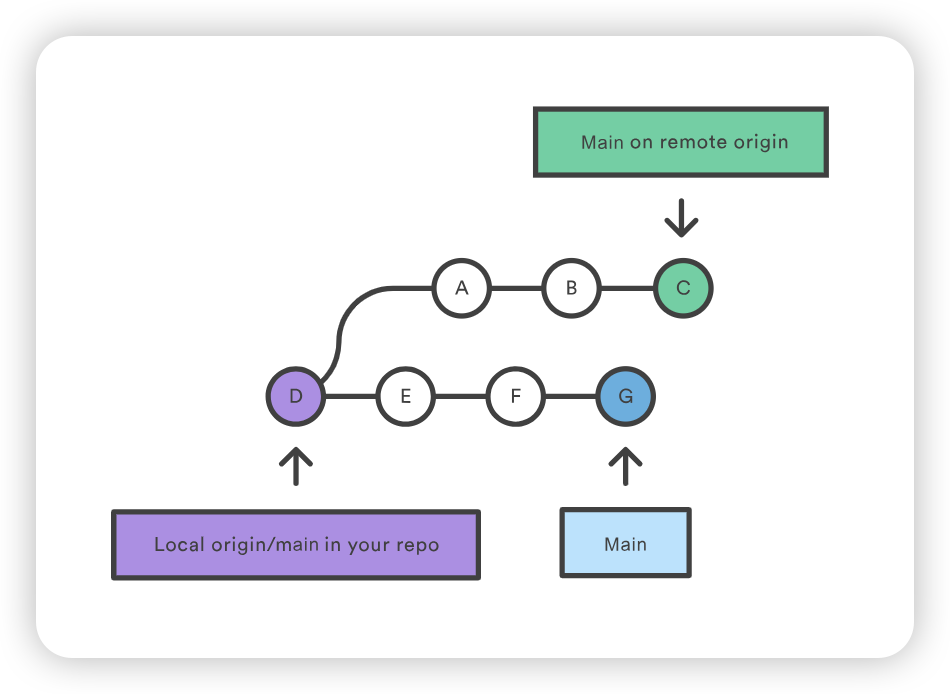
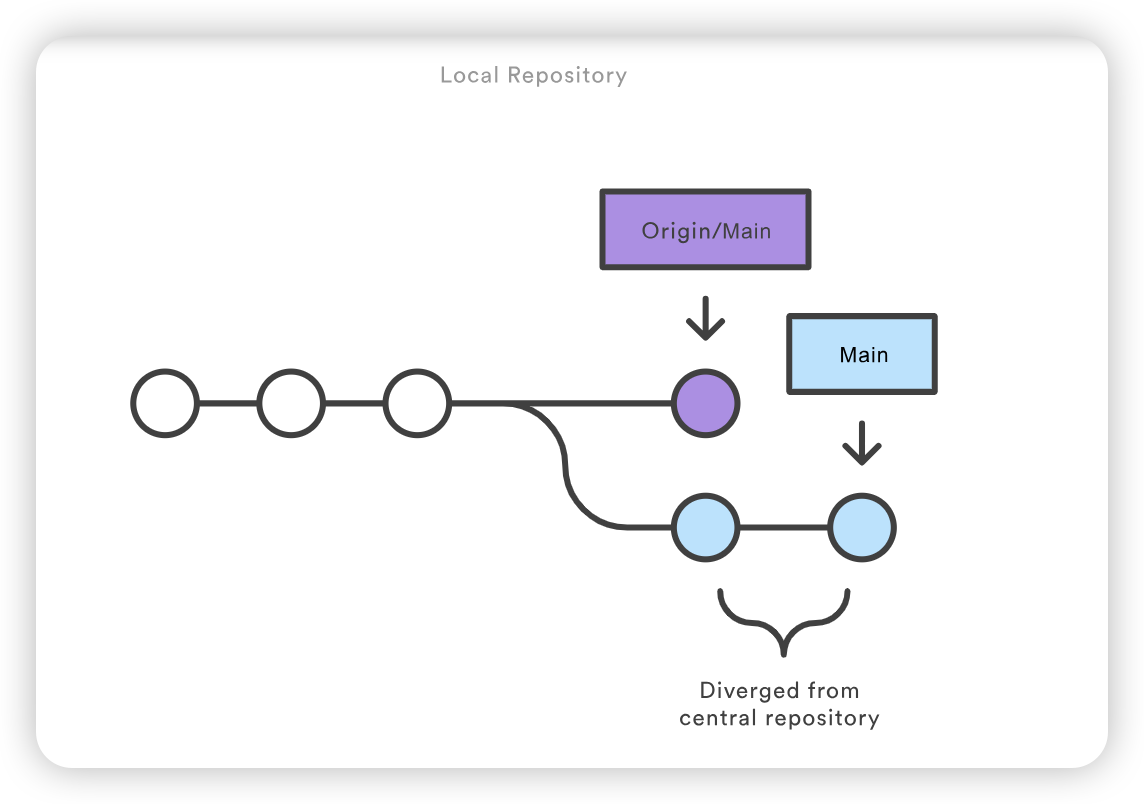
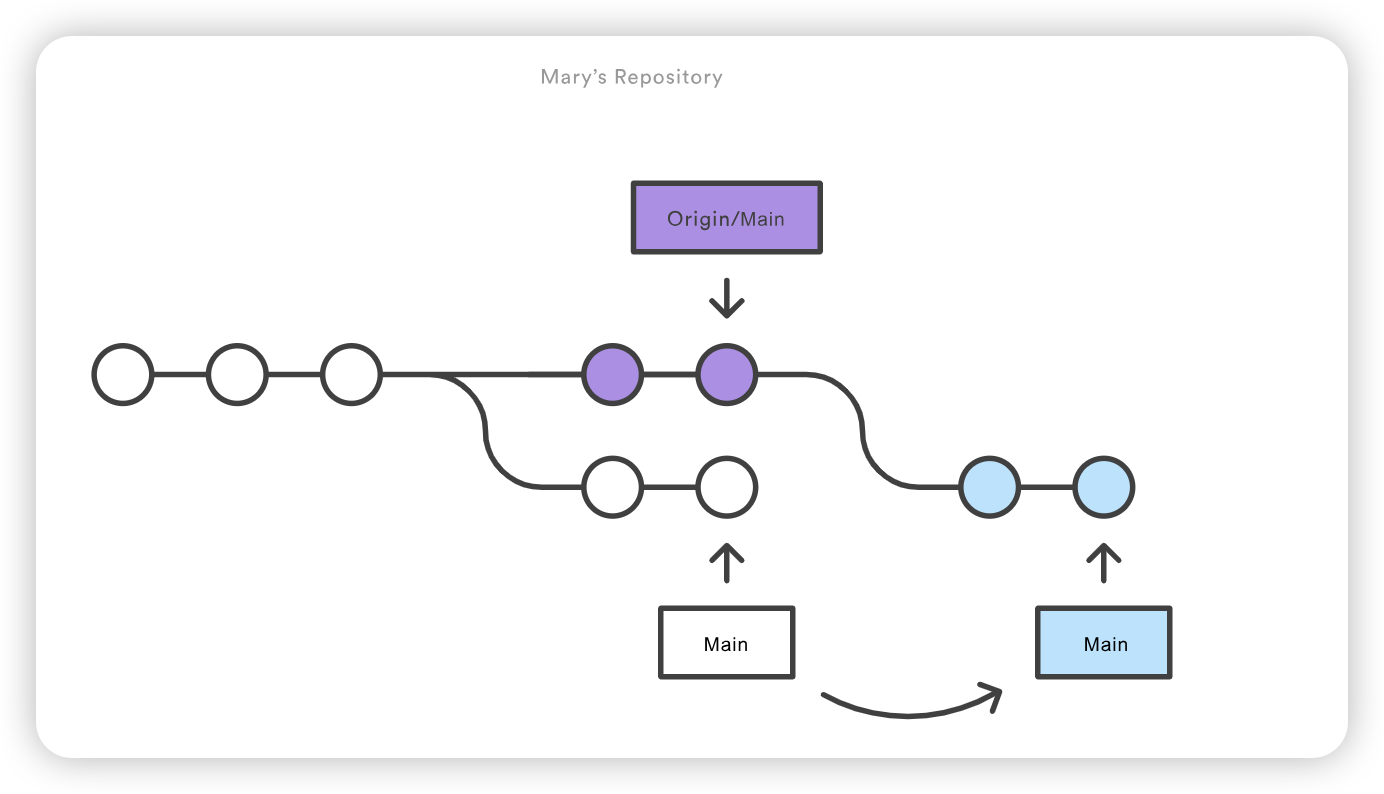
让我们看看如果 Mary 在 John 成功将其更改发布到中心版本库后尝试推送她的功能会发生什么。她可以使用完全相同的推送命令:
1
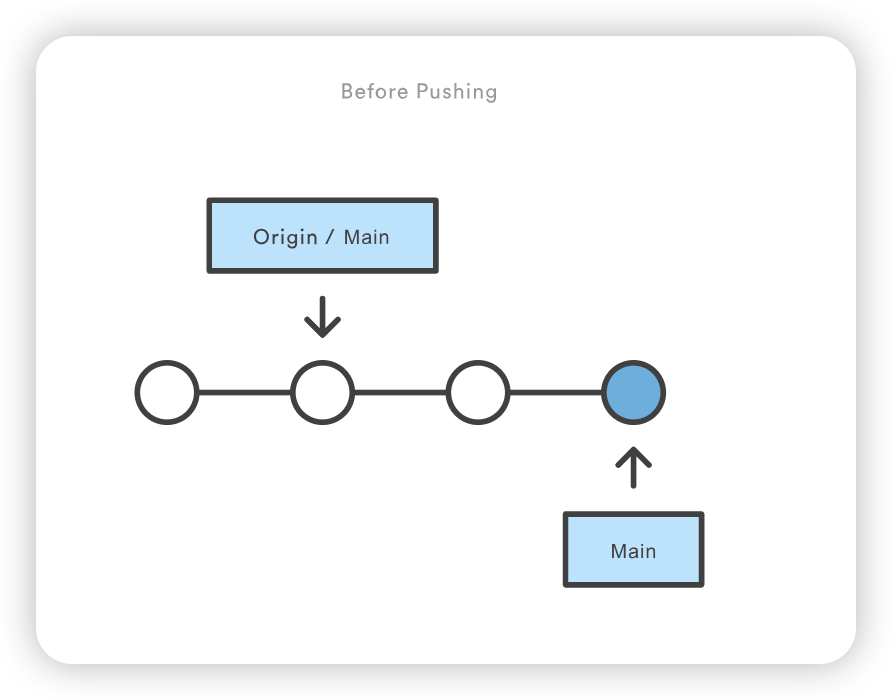
git push origin main
但是,由于她的本地历史已经偏离了中央仓库,Git 会拒绝该请求,并给出一条相当冗长的错误信息:
1 2 3 4 5
error: failed to push some refs to '/path/to/repo.git' hint: Updates were rejected because the tip of your current branch is behind hint: its remote counterpart. Merge the remote changes (e.g. 'git pull') hint: before pushing again. hint: See the 'Note about fast-forwards'in'git push --help'for details.
这就防止了 Mary 覆盖官方提交。她需要将 John 的更新拉入自己的版本库,与本地变更整合,然后再试一次。
Mary在John提交的基础上进行Rebase
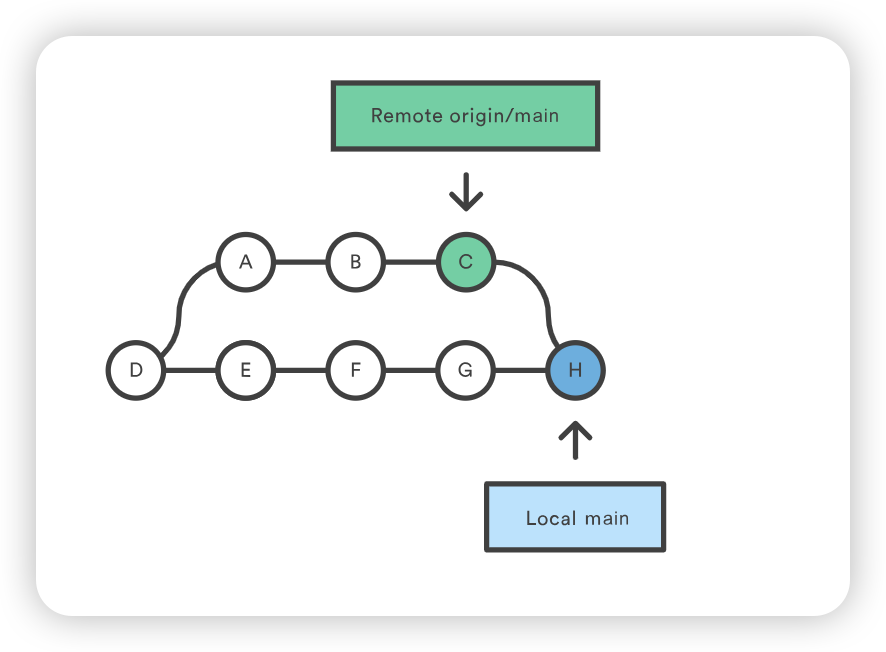
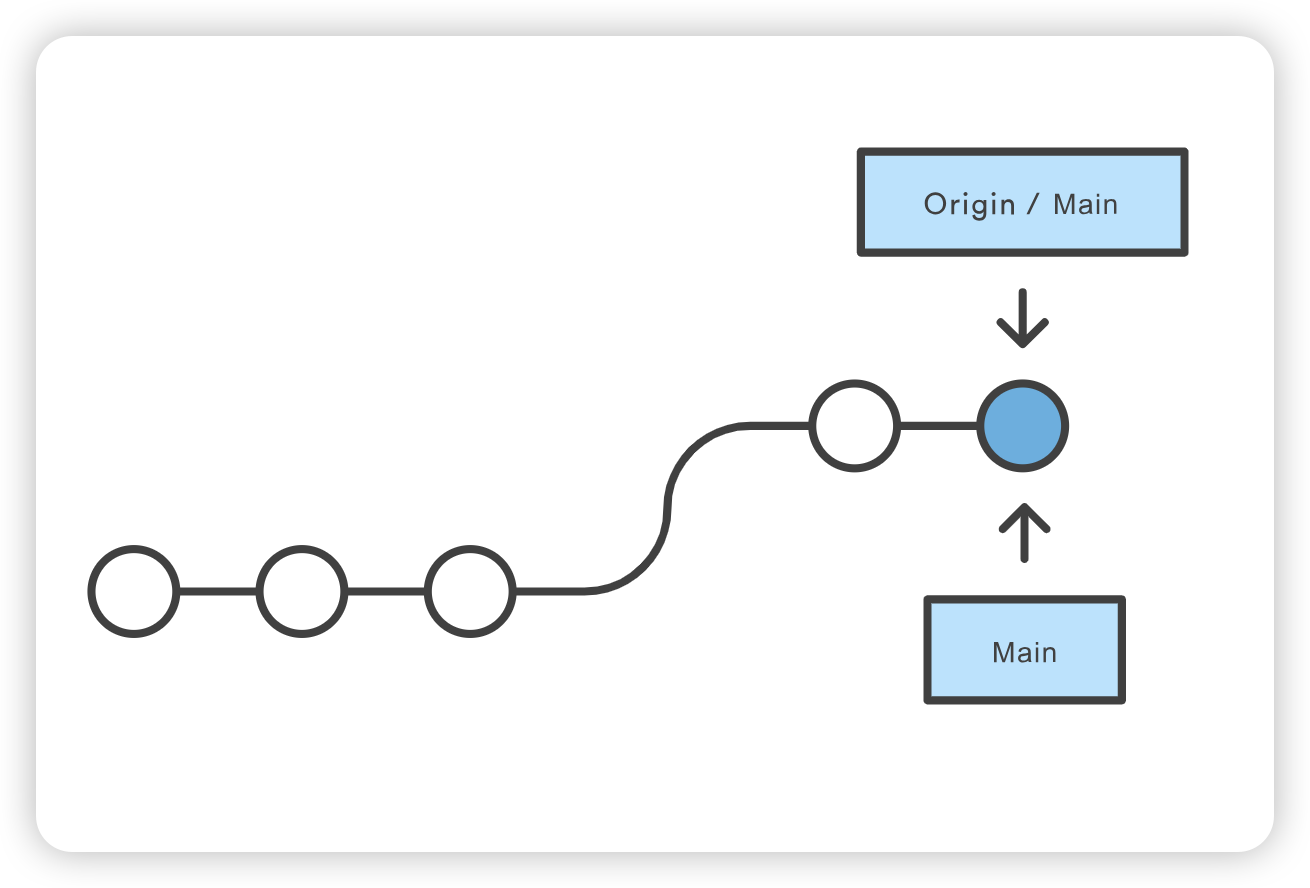
Mary 可以使用 git pull 将上游的改动整合到自己的版本库中。这个命令有点像 svn update–它会把整个上游提交历史拉入 Mary 的本地仓库,并尝试将其与本地提交整合在一起:
1
git pull --rebase origin main
如下所示,--rebase 选项会告诉 Git 将 Mary 的所有提交与中心仓库的改动同步后移到主分支的顶端:
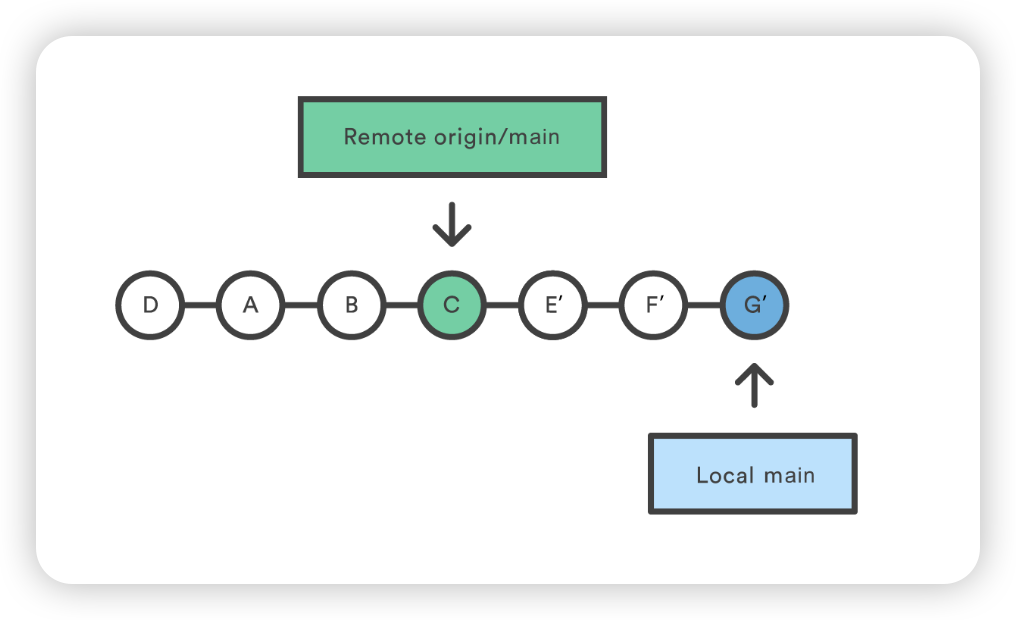
如果 Mary 和 John 正在开发不相关的功能,Rebasing过程不太可能产生冲突。但如果发生冲突,Git 会在当前提交处暂停重置,并输出以下信息和相关说明:
1
CONFLICT (content): Merge conflict in <some-file>
Git 的好处在于,任何人都可以解决自己的合并冲突。在我们的例子中,Mary 只需运行 git status 就能看到问题所在。有冲突的文件会出现在未合并路径部分:
1 2 3 4 5
# Unmerged paths: # (use "git reset HEAD <some-file>..." to unstage) # (use "git add/rm <some-file>..." as appropriate to mark resolution) # # both modified: <some-file>
然后,她会按照自己的喜好编辑文件。一旦她对结果感到满意,就可以按照通常的方式对文件进行暂存,然后让 git rebase 完成剩下的工作:
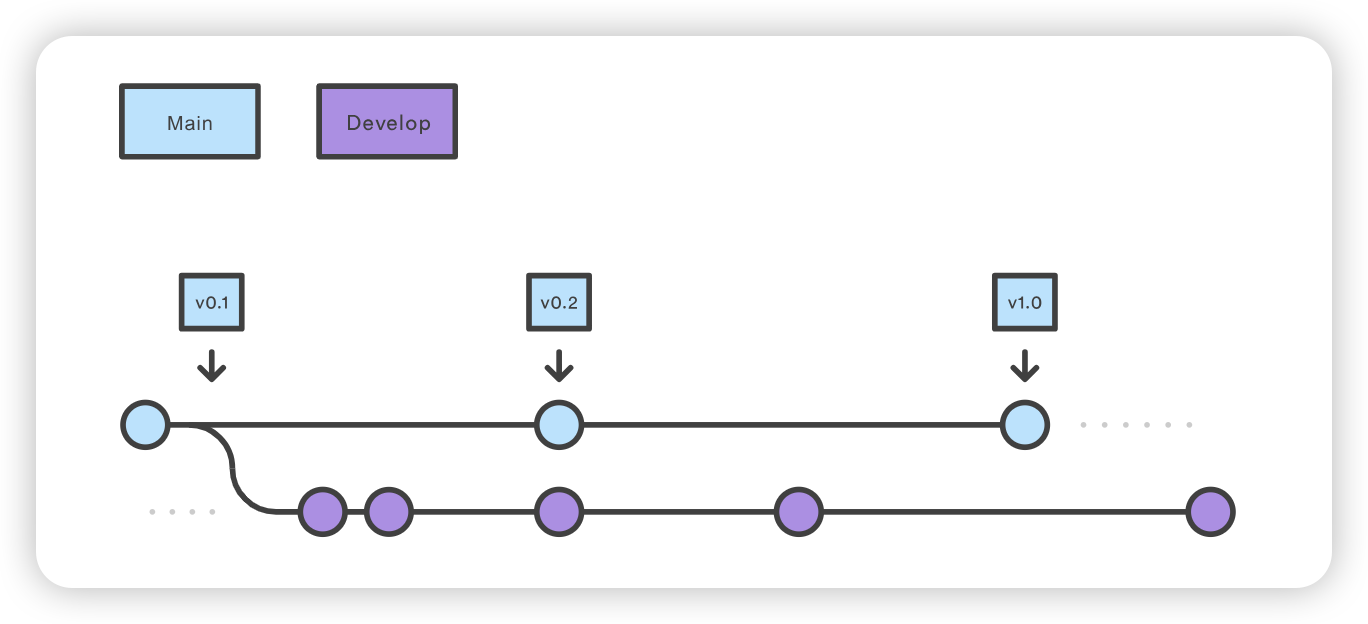
Initialized empty Git repository in ~/project/.git/ No branches exist yet. Base branches must be created now. Branch name for production releases: [main] Branch name for"next release" development: [develop]
How to name your supporting branch prefixes? Feature branches? [feature/] Release branches? [release/] Hotfix branches? [hotfix/] Support branches? [support/] Version tag prefix? []
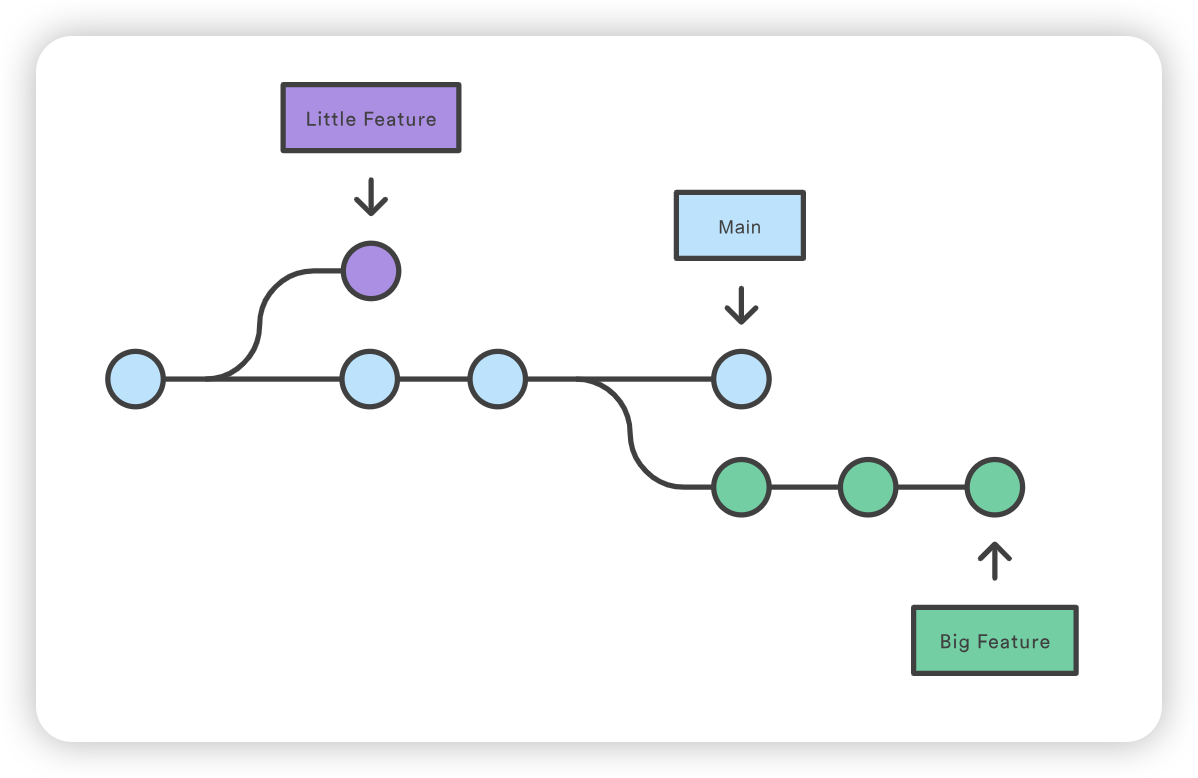
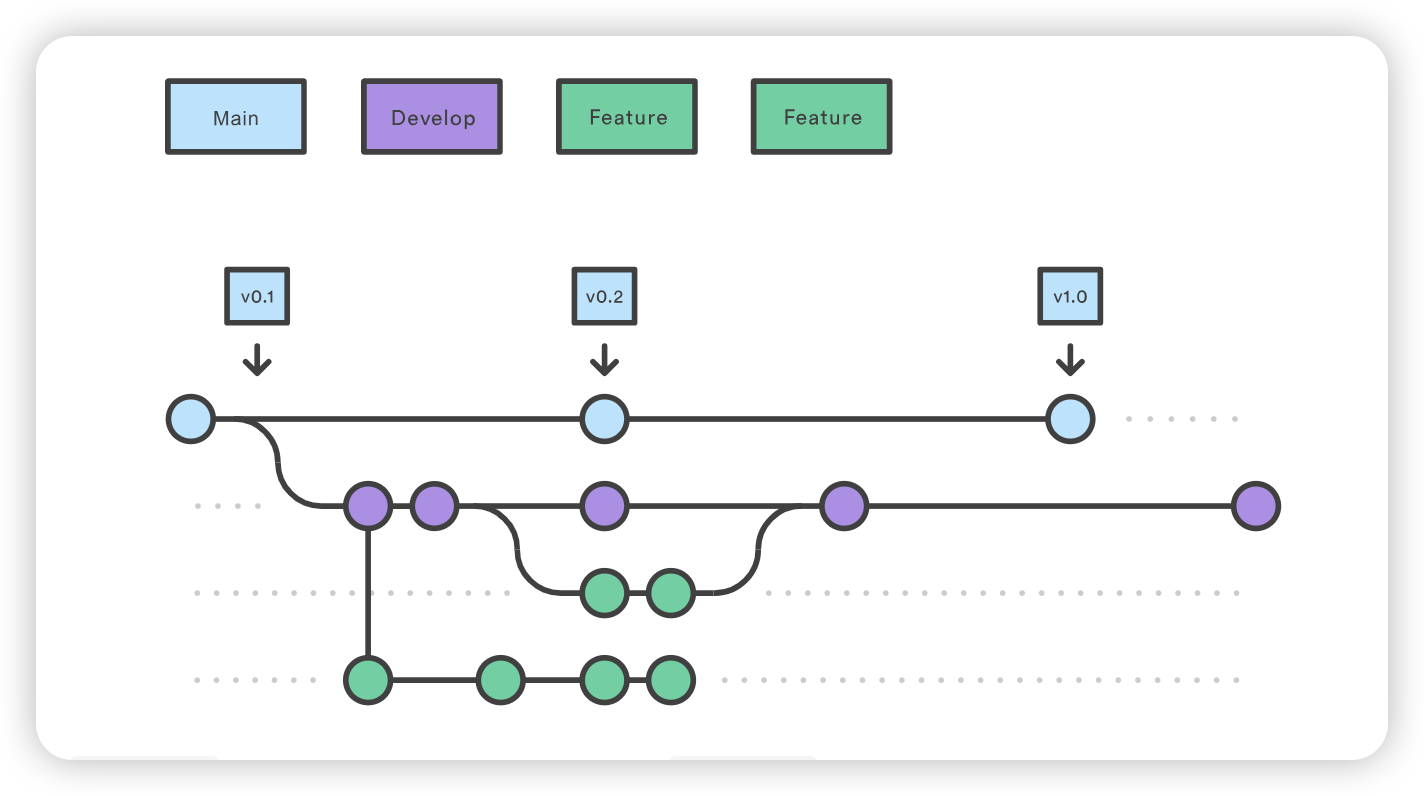
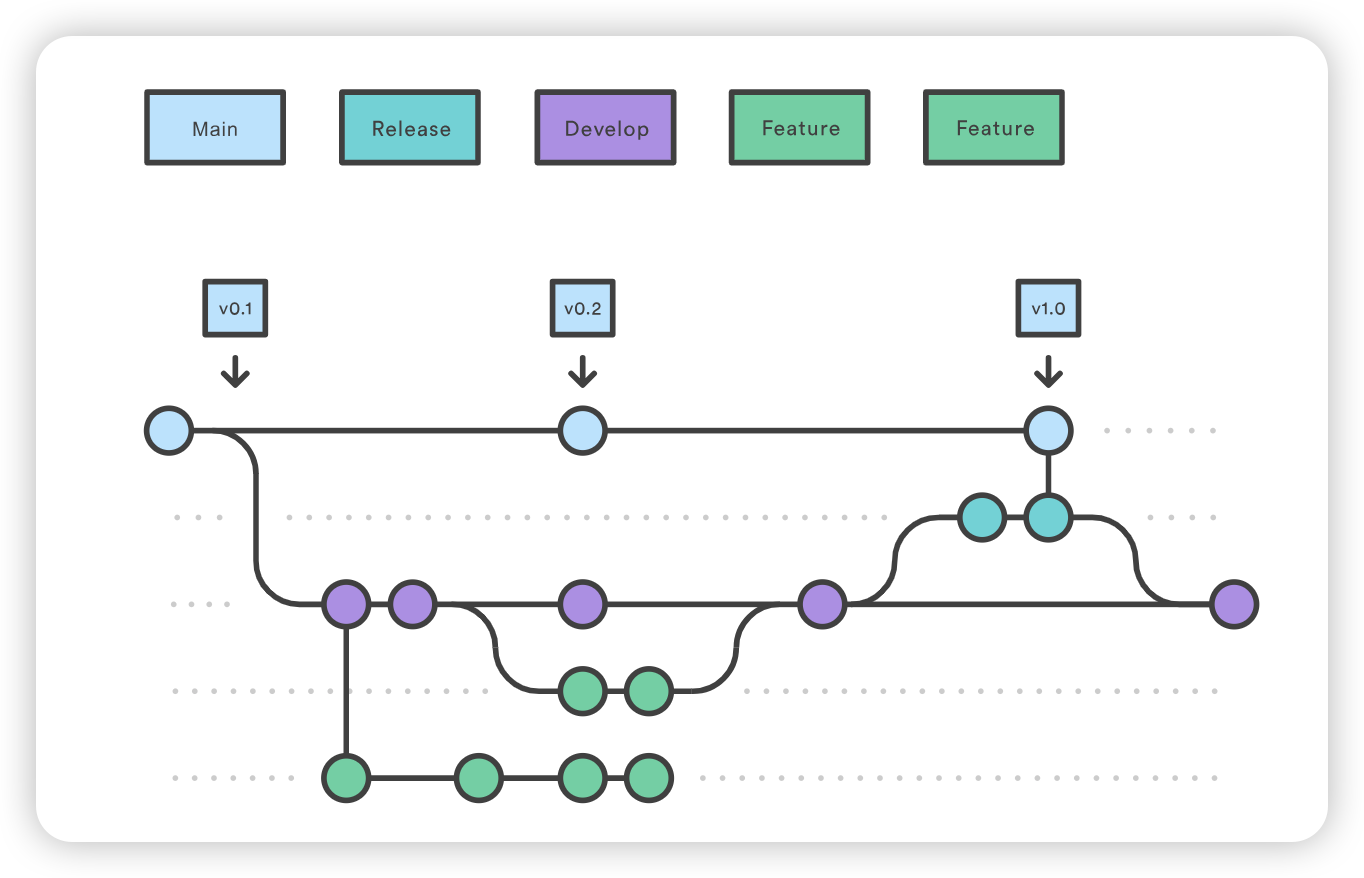
git checkout main git checkout -b develop git checkout -b feature_branch # work happens on feature branch git checkout develop git merge feature_branch git checkout main git merge develop git branch -d feature_branch
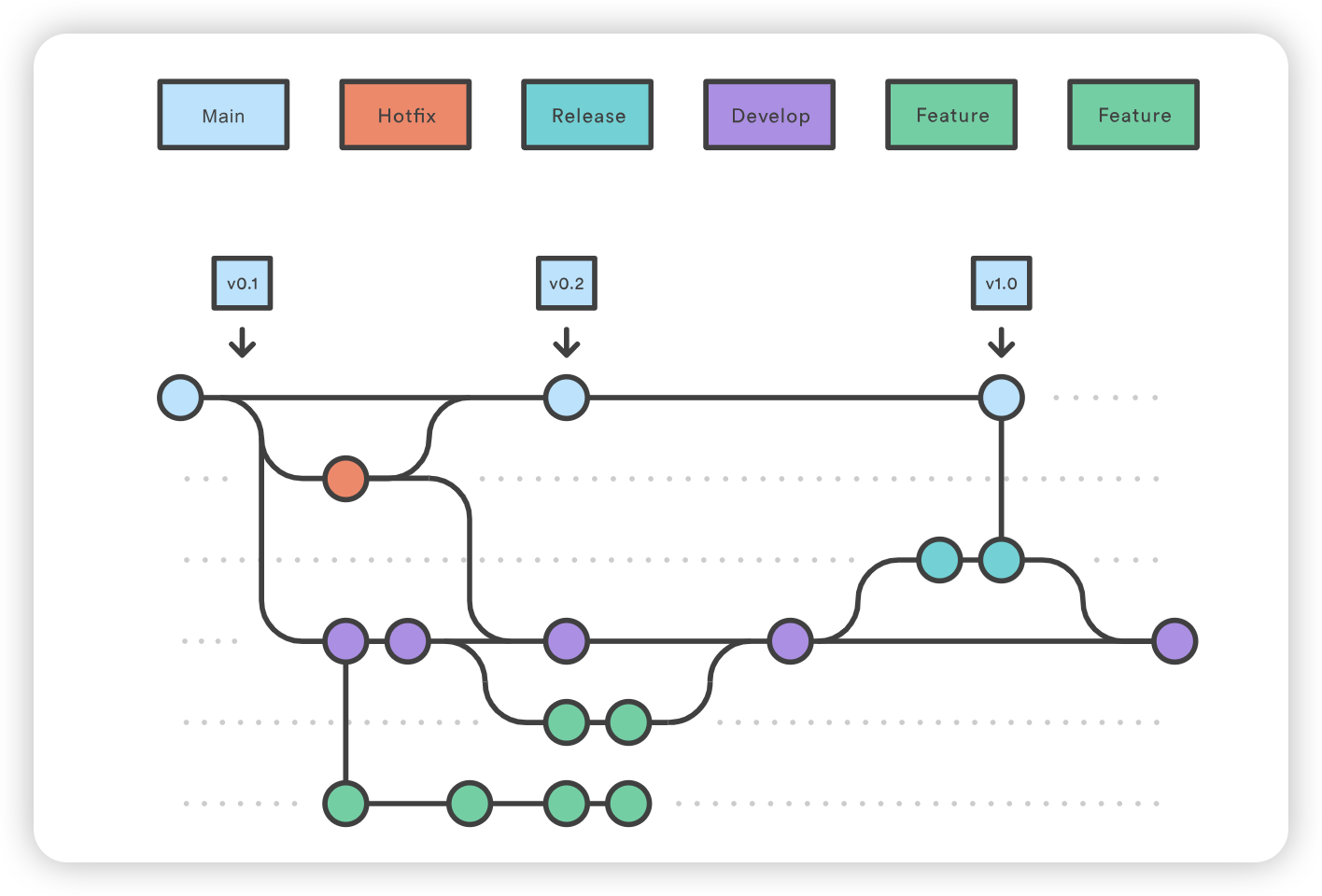
除功能分支和发布分支流程外,热修复示例如下:
1 2 3 4 5 6 7
git checkout main git checkout -b hotfix_branch # work is done commits are added to the hotfix_branch git checkout develop git merge hotfix_branch git checkout main git merge hotfix_branch
全局配置是针对特定用户的,这意味着它适用于操作系统用户。全局配置值存储在用户主目录下的一个文件中。在 unix 系统中为 ~ /.gitconfig,在 windows 系统中为 C:\Users\\.gitconfig
--system
系统级配置适用于整个机器。这包括操作系统上的所有用户和所有版本库。系统级配置文件位于系统根目录下的 gitconfig 文件中。在 unix 系统中为 $(prefix)/etc/gitconfig。在 Windows XP 上,该文件位于 C:\Documents and Settings\All Users\Application Data\Git\config 下;在 Windows Vista 及更新版本上,该文件位于 C:\ProgramData\Git\config 下。
git log --pretty=oneline 957fbc92b123030c389bf8b4b874522bdf2db72c add feature ce489262a1ee34340440e55a0b99ea6918e19e7a rename some classes 6b539f280d8b0ec4874671bae9c6bed80b788006 refactor some code for feature 646e7863348a427e1ed9163a9a96fa759112f102 add some copy to body
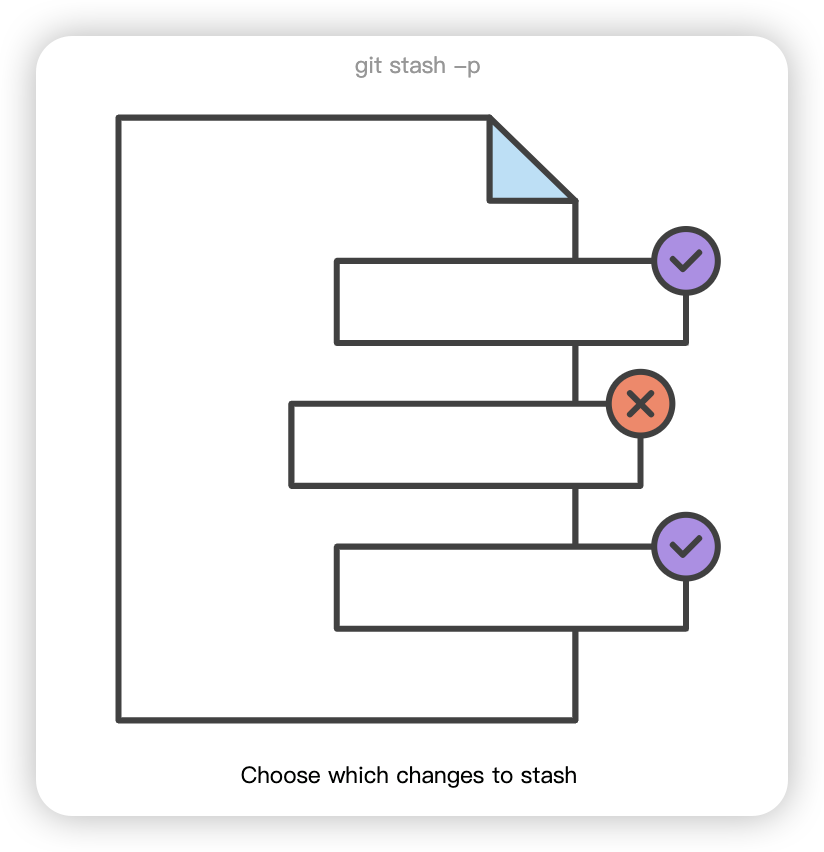
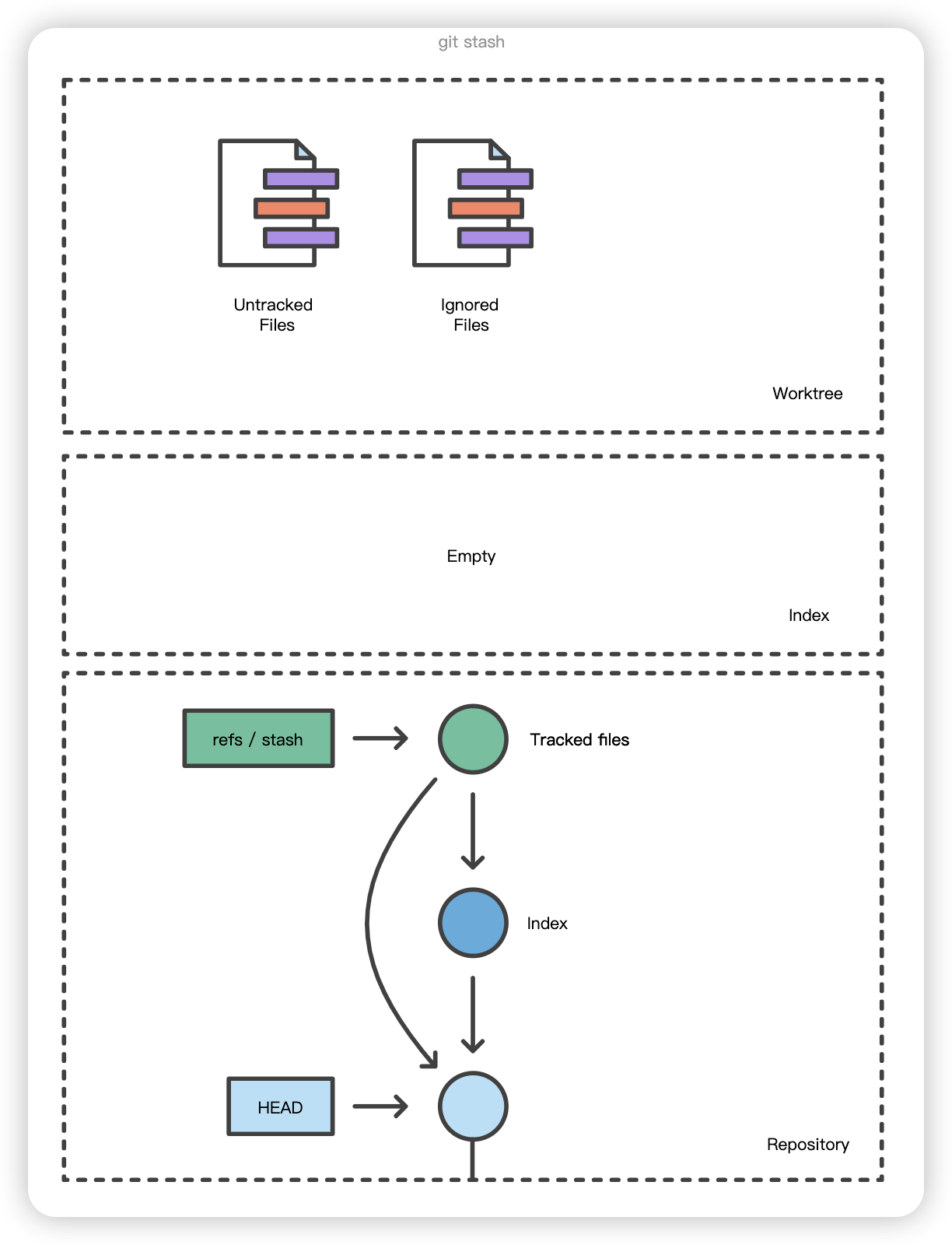
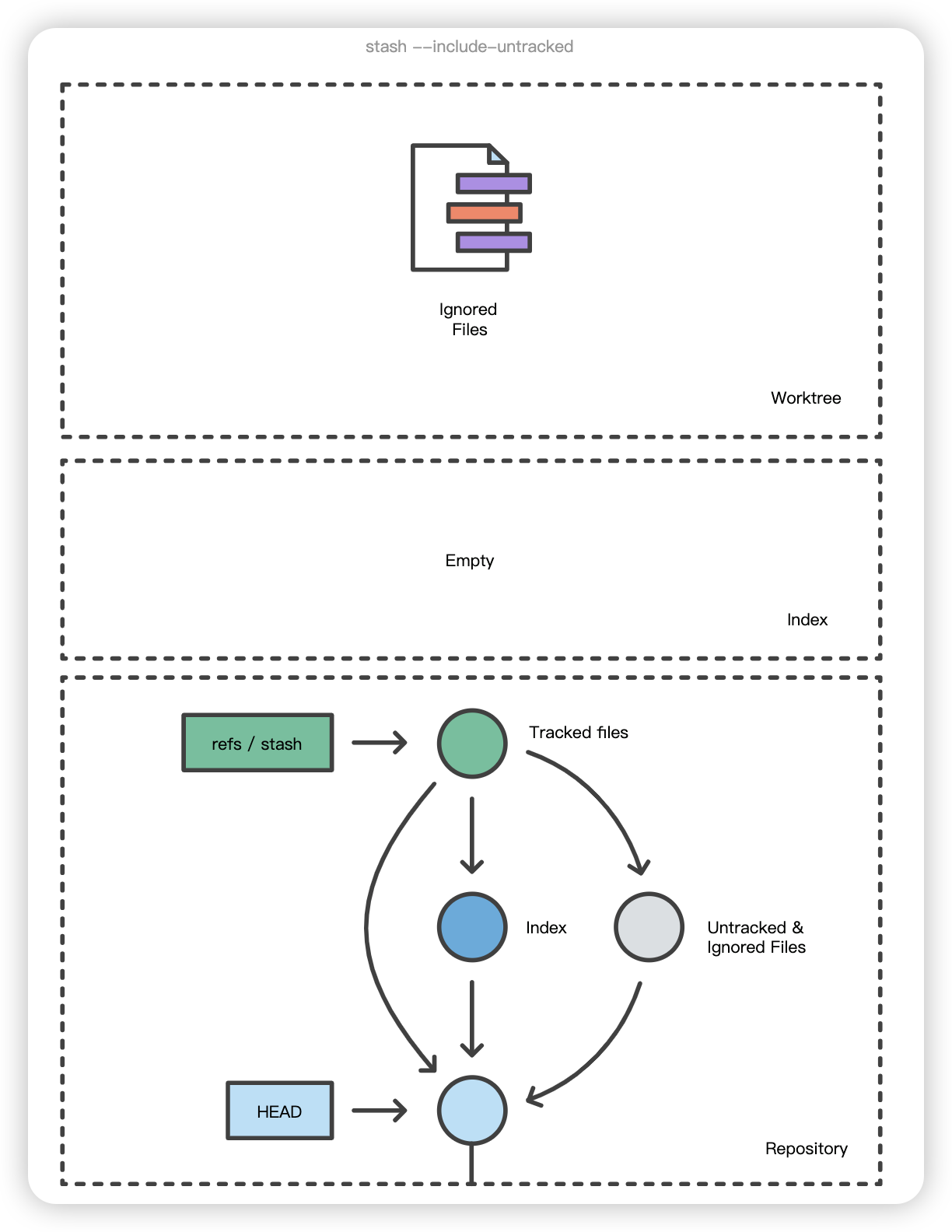
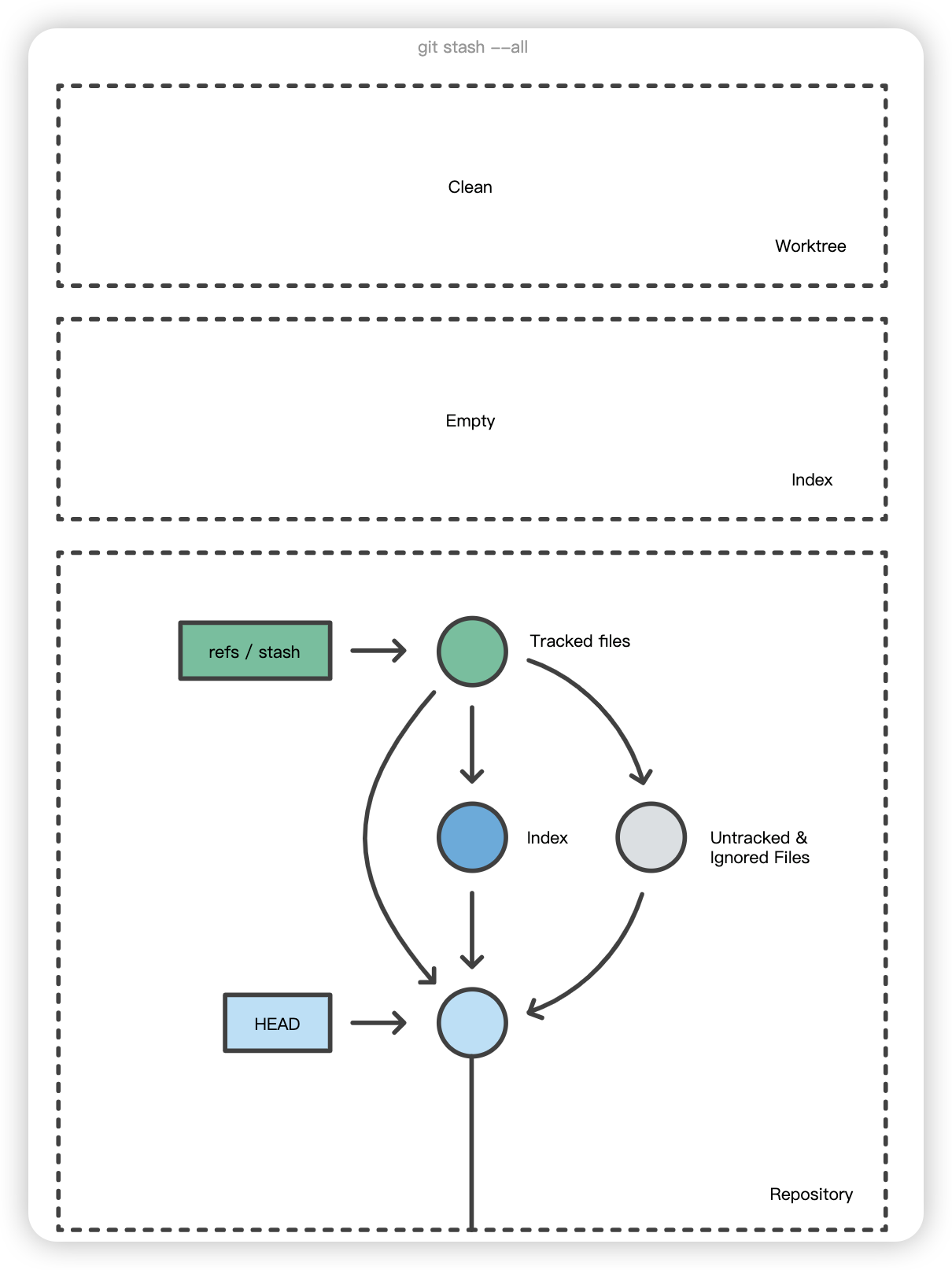
$ git stash list stash@{0}: WIP on main: 5002d47 our new homepage stash@{1}: WIP on main: 5002d47 our new homepage stash@{2}: WIP on main: 5002d47 our new homepage
为了提供更多的上下文信息,使用 git stash save "message "为储藏注释说明是个不错的做法:
1 2 3 4 5 6 7 8
$ git stash save "add style to our site" Saved working directory and index state On main: add style to our site HEAD is now at 5002d47 our new homepage
$ git stash list stash@{0}: On main: add style to our site stash@{1}: WIP on main: 5002d47 our new homepage stash@{2}: WIP on main: 5002d47 our new homepage
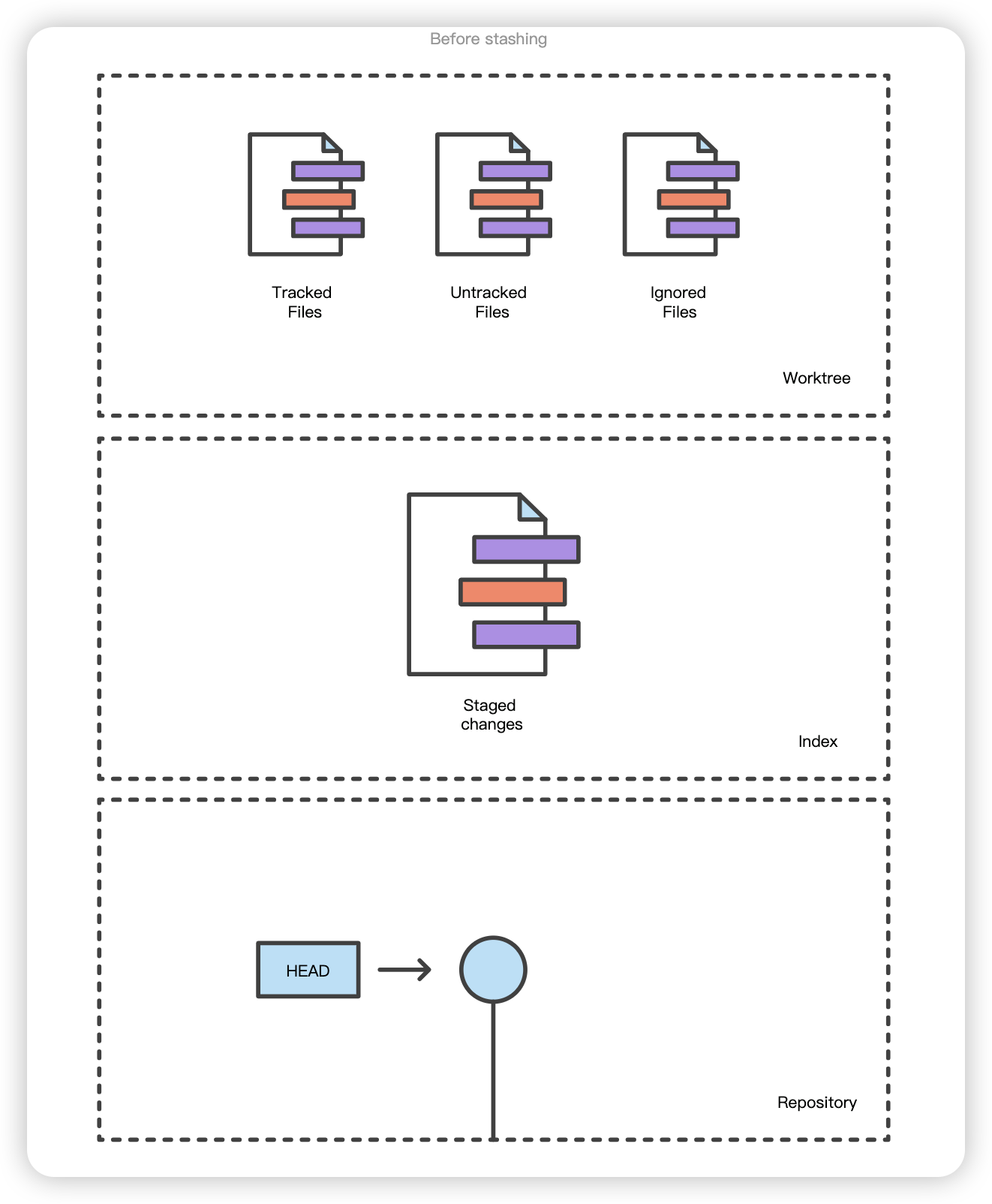
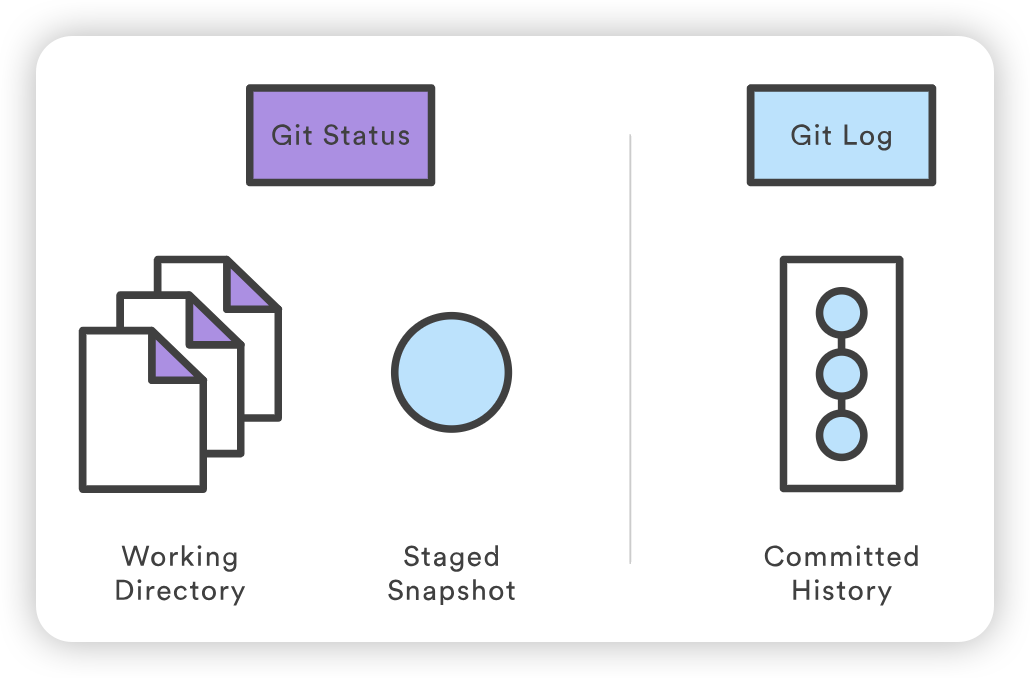
git status 命令是一个相对简单的命令。它只需显示 git add 和git commit的状态。状态信息还包括文件暂存/未暂存的相关说明。下面的示例输出显示了 git 状态调用的三个主要类别:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# On branch main # Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # #modified: hello.py # # Changes not staged for commit: # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # #modified: main.py # # Untracked files: # (use "git add <file>..." to include in what will be committed) # #hello.pyc
# Edit hello.py git status # hello.py is listed under "Changes not staged for commit" git add hello.py git status # hello.py is listed under "Changes to be committed" git commit git status # nothing to commit (working directory clean)
将 <tagname> 替换为创建标签时版本仓库状态的语义标识符。常见的模式是使用版本号,如 git tag v1.4。Git 支持两种不同类型的标签:注释标签和轻量级标签。前面的例子创建了一个轻量级标签。轻量级标签和注释标签存储的元数据量不同。最佳做法是将注释标签视为公共标签,将轻量级标签视为私有标签。注释标签存储额外的元数据,例如:标签名称、电子邮件和日期。这对于公开发布来说是非常重要的数据。轻量级标签本质上是提交的 “书签”,它们只是一个名称和指向提交的指针,可用于创建指向相关提交的快速链接。
附加说明注释的标签
注释标签(annotated tags)作为存储在 Git 数据库中完整对象。它们存储了额外的元数据,如:标签名称、电子邮件和日期。与提交和提交信息类似,注释标签也有标签信息。此外,为了安全起见,注释标签可以使用 GNU Privacy Guard(GPG)进行签名和验证。建议使用 git tag 的最佳做法是,优先使用注释标签,而不是轻量级标签,这样就能获得所有相关的元数据。
$ git blame README.md 82496ea3 (kevzettler 2018-02-28 13:37:02 -0800 1) # Git Blame example 82496ea3 (kevzettler 2018-02-28 13:37:02 -0800 2) 89feb84d (Albert So 2018-03-01 00:54:03 +0000 3) This repository is an example of a project with multiple contributors making commits. 82496ea3 (kevzettler 2018-02-28 13:37:02 -0800 4) 82496ea3 (kevzettler 2018-02-28 13:37:02 -0800 5) The repo use used elsewhere to demonstrate `git blame` 82496ea3 (kevzettler 2018-02-28 13:37:02 -0800 6) 89feb84d (Albert So 2018-03-01 00:54:03 +0000 7) Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod TEMPOR incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum 89feb84d (Albert So 2018-03-01 00:54:03 +0000 8) eb06faed (Juni Mukherjee 2018-03-01 19:53:23 +0000 9) Annotates each line in the given file with information from the revision which last modified the line. Optionally, start annotating from the given revision. eb06faed (Juni Mukherjee 2018-03-01 19:53:23 +0000 10) 548dabed (Juni Mukherjee 2018-03-01 19:55:15 +0000 11) Creating a line to support documentation needs for git blame. 548dabed (Juni Mukherjee 2018-03-01 19:55:15 +0000 12) 548dabed (Juni Mukherjee 2018-03-01 19:55:15 +0000 13) Also, it is important to have a few of these commits to clearly reflect the who, the what and the when. This will help Kev get good screenshots when he runs the git blame on this README.
$ git log -S"CSS3D and WebGL renderers." --pretty=format:'%h %an %ad %s' e339d3c85 Mario Schuettel Tue Oct 13 16:51:06 2015 +0200 reverted README.md to original content 509c2cc35 Daniel Tue Sep 8 13:56:14 2015 +0200 Updated README cb20237cc Mr.doob Mon Dec 31 00:22:36 2012 +0100 Removed DOMRenderer. Now with the CSS3DRenderer it has become irrelevant.
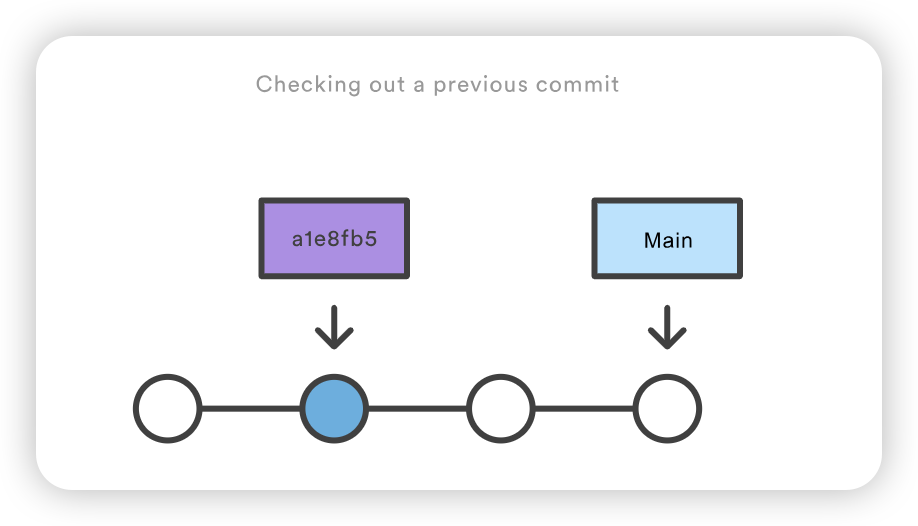
b7119f2 Continue doing crazy things 872fa7e Try something crazy a1e8fb5 Make some important changes to hello.txt 435b61d Create hello.txt 9773e52 Initial import
$ git clean -di Would remove the following items: untracked_dir/ untracked_file *** Commands *** 1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit 6: help What now>
What now> 6 clean - start cleaning filter by pattern - exclude items from deletion select by numbers - select items to be deleted by numbers ask each - confirm each deletion (like "rm -i") quit - stop cleaning help - this screen ? - helpfor prompt selection
*** Commands *** 1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit 6: help What now> 4 Remove untracked_dir/ [y/N]? N Remove untracked_file [y/N]? N
1
2: filter by pattern
将显示额外提示,输入用于过滤未跟踪文件列表的信息。
1 2 3 4 5 6 7 8
Would remove the following items: untracked_dir/ untracked_file *** Commands *** 1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit 6: help What now> 2 untracked_dir/ untracked_file Input ignore patterns>> *_file untracked_dir/
Would remove the following items: untracked_dir/ untracked_file *** Commands *** 1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit 6: help What now> 3 1: untracked_dir/ 2: untracked_file Select items to delete>> 2 1: untracked_dir/ * 2: untracked_file Select items to delete>> Would remove the following item: untracked_file *** Commands *** 1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit 6: help
$ echo'hello git reset' > reset_lifecycle_file $ git status On branch main Changes not staged for commit: (use "git add ..." to update what will be committed) (use "git checkout -- ..." to discard changes in working directory) modified: reset_lifecycle_file
在我们的演示版本库中,我们修改了 reset_lifecycle_file 并添加了一些内容。调用 git status 可以看到 Git 已经知道了文件的改动。这些改动目前是第一个树 “工作目录 “的一部分。git status 可以用来显示工作目录的改动。它们将以红色显示,并带有 “modified”前缀。
在这里,我们调用了 git add reset_lifecycle_file,将文件添加到了暂存索引中。现在调用 git status,reset_lifecycle_file 在 “Changes to be committed”下显示为绿色。需要注意的是,git status 并不能真实反映暂存索引。git status 命令输出显示的是提交历史和暂存索引之间的变化。让我们来看看暂存索引的内容。
$ git commit -am"update content of reset_lifecycle_file" [main dc67808] update content of reset_lifecycle_file 1 file changed, 1 insertion(+) $ git status On branch main nothing to commit, working tree clean
$ git status On branch main Changes to be committed: (use "git reset HEAD ..." to unstage)
new file: new_file
Changes not staged for commit: (use "git add ..." to update what will be committed) (use "git checkout -- ..." to discard changes in working directory)
modified: reset_lifecycle_file
在这里,我们调用了 git add reset_lifecycle_file,将文件添加到了暂存索引中。现在调用 git status,reset_lifecycle_file 在 “Changes to be committed “下显示为绿色。
需要注意的是,git status 并不能真实反映暂存索引。git status 命令输出显示的是提交历史和暂存索引之间的变化。让我们来看看暂存索引的内容。
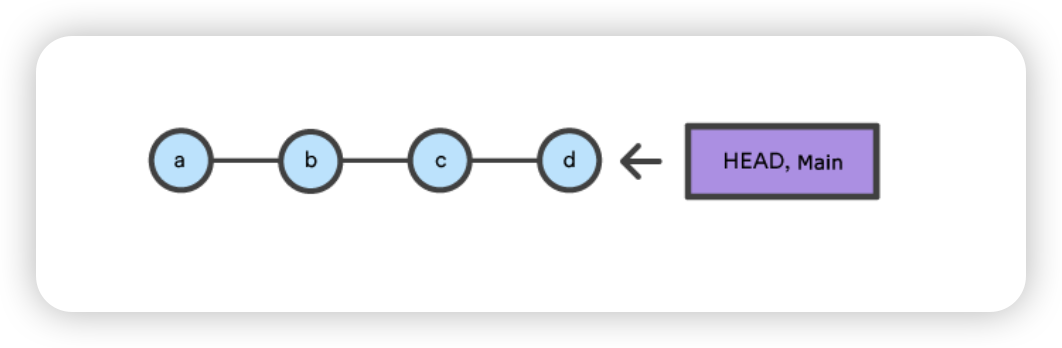
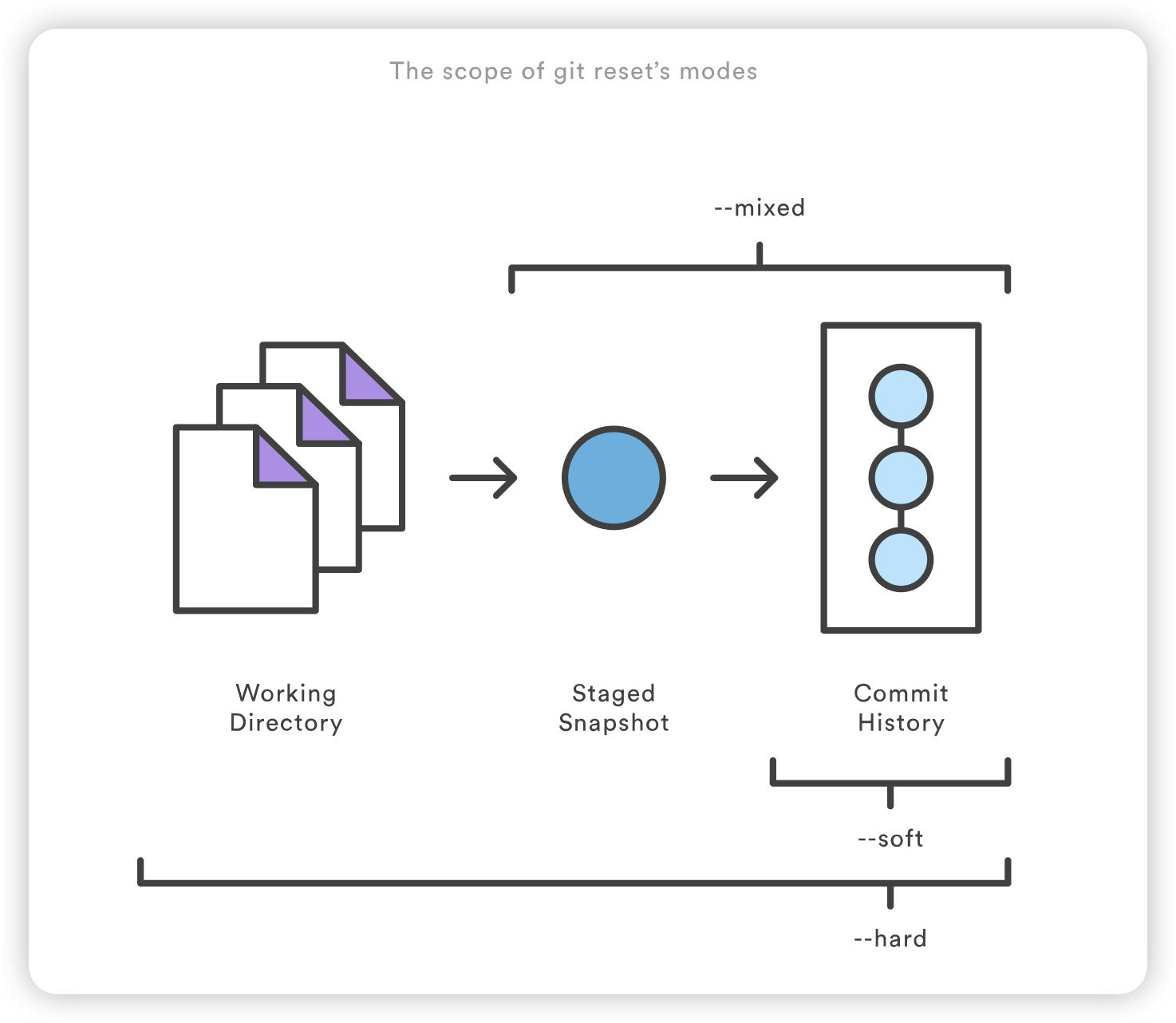
$ git reset --hard HEAD is now at dc67808 update content of reset_lifecycle_file $ git status On branch main nothing to commit, working tree clean $ git ls-files -s 100644 d7d77c1b04b5edd5acfc85de0b592449e5303770 0 reset_lifecycle_file
在这里,我们使用 --hard 选项执行了一次 “硬重置”。Git 的输出显示 HEAD 指向了最新提交 dc67808。
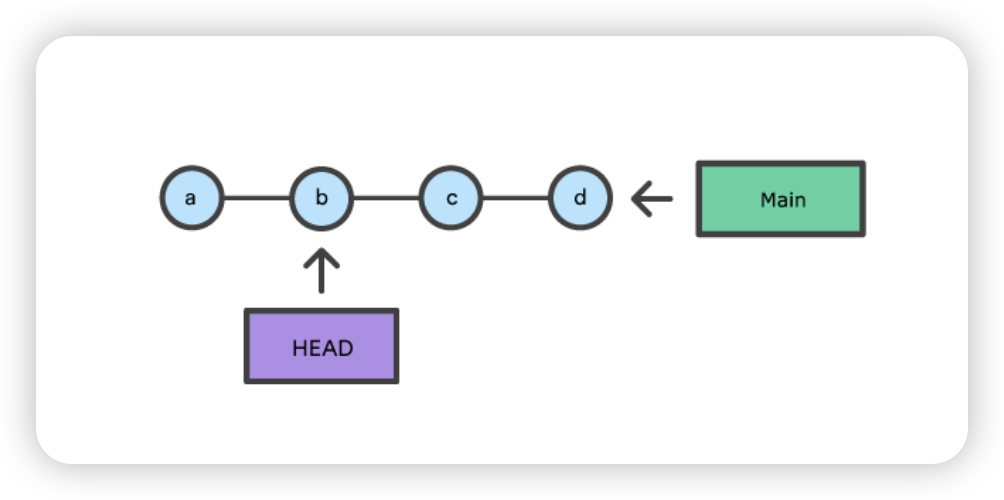
$ git reset --mixed $ git status On branch main Changes not staged for commit: (use "git add ..." to update what will be committed) (use "git checkout -- ..." to discard changes in working directory)
modified: reset_lifecycle_file
Untracked files: (use "git add ..." to include in what will be committed)
new_file
no changes added to commit (use "git add" and/or "git commit -a") $ git ls-files -s 100644 d7d77c1b04b5edd5acfc85de0b592449e5303770 0 reset_lifecycle_file
Author: bitbucket Date: Thu Nov 30 16:50:39 2017 -0800
initial commit
请记住,每个系统的提交历史 ID 都是唯一的。这意味着本示例中的提交 ID 将与您在个人计算机上看到的不同。本例中我们感兴趣的提交 ID 是 780411da3b47117270c0e3a8d5dcfd11d28d04a4。这是对应于 “初始提交 “的 ID。找到这个 ID 后,我们将把它作为soft reset的目标。
在回到过去之前,让我们先检查一下 repo 的当前状态。
1 2 3 4
$ git status && git ls-files -s On branch main nothing to commit, working tree clean 100644 67cc52710639e5da6b515416fd779d0741e3762e 0 reset_lifecycle_file
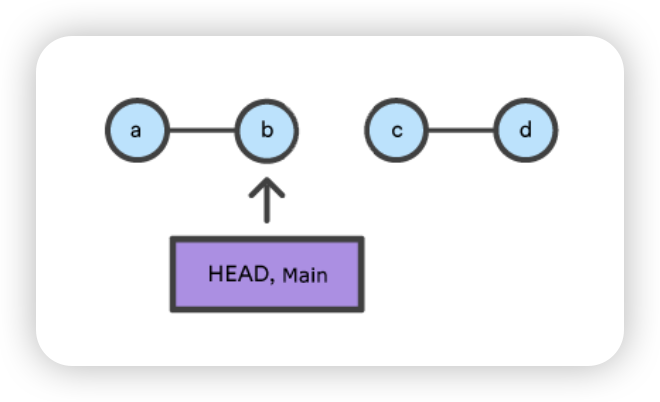
$git reset --soft 780411da3b47117270c0e3a8d5dcfd11d28d04a4 $ git status && git ls-files -s On branch main Changes to be committed: (use "git reset HEAD ..." to unstage)
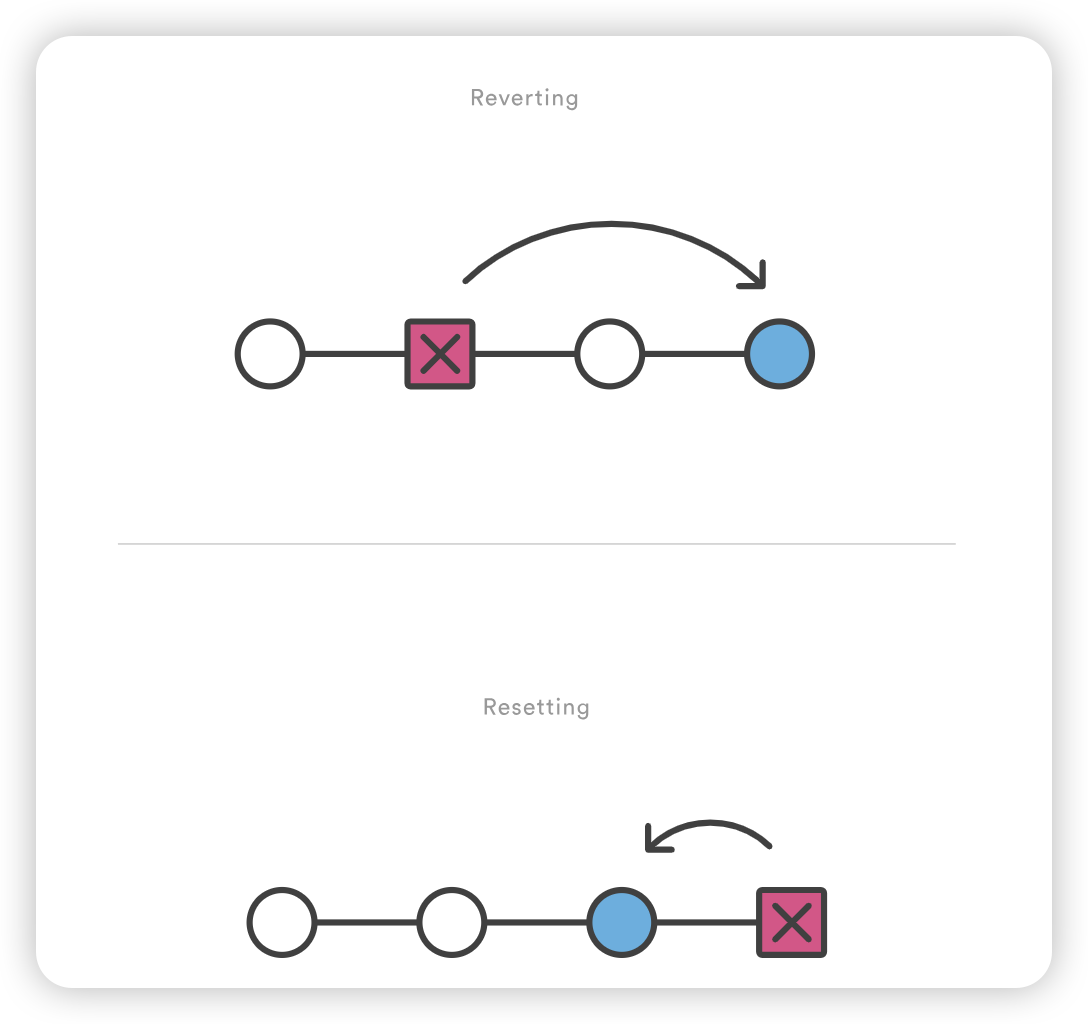
要修改旧提交或多个提交,可以使用 git rebase 将一系列提交合并为一个新的基本提交。在标准模式下,git rebase 可以让你真正改写历史–自动将当前工作分支中的提交应用到已通过的分支顶部。由于新的提交将替换旧的提交,因此不要在已公开推送的提交上使用 git rebase,否则会导致项目历史消失。
在这种或类似情况下,如果需要保留完整的项目历史,可以在 git rebase 中添加 -i 选项,以交互方式运行 rebase。这样,你就有机会在过程中修改单个提交,而不是移动所有提交。你可以在 git rebase 页面了解更多关于交互式rebase 和其他 rebase 命令的信息。
更改已提交的文件
在rebase过程中,edit 或 e 命令将暂停该提交上的rebase回放,并允许您使用 git commit --amend 命令进行其他修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Stopped at 5d025d1... formatting You can amend the commit now, with
Git rebase interactive 是指 git rebase 接受 – i 参数。这代表 “交互式”。如果不带任何参数,命令将以标准模式运行。在这两种情况下,假设我们都创建了一个独立的特性分支。
1 2 3 4
# Create a feature branch based off of main git checkout -b feature_branch main # Edit files git commit -a -m "Adds new feature"
标准模式下的 git rebase 会自动将当前工作分支中的提交应用到已传递分支的头部。
1
git rebase <base>
它会自动将当前分支重定向到<base>上,<base>可以是任何类型的提交引用(例如 ID、分支名、标签或 HEAD 的相对引用)。
使用 -i 标志运行 git rebase 会开始一个交互式的rebase会话。交互式rebase不会盲目地将所有提交移到新的基础上,而是让你有机会在过程中修改单个提交。这样,你就可以通过删除、拆分和修改现有的一系列提交来清理历史。这就像是 Git commit –amend。
1
git rebase --interactive <base>
此操作会将当前分支重定向到<base>,但使用的是交互式重定向会话。这将打开一个编辑器,你可以为每个要重定向的提交输入命令(如下所述)。这些命令决定了如何将单个提交转移到新的base。你还可以重新排列提交列表,改变提交本身的顺序。一旦你为每个提交指定了命令,Git 就会开始回放应用 rebase 命令的提交。rebase编辑命令如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
pick 2231360 some old commit pick ee2adc2 Adds new feature
# Rebase 2cf755d..ee2adc2 onto 2cf755d (9 commands) # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # d, drop = remove commit
其他 rebase 命令
正如改写历史页面所详述的,rebase 可用于修改旧提交、多次提交、已提交文件和多条信息。虽然这些都是最常见的应用,但 git rebase 还有额外的命令选项,在更复杂的应用中也很有用。
git rebase -- d 表示在回放过程中,该提交将从最终合并的提交块中丢弃。
git rebase -- p 表示保持提交原样。它不会修改提交信息或内容,在分支历史中仍是一个单独的提交。
git rebase -- x 在播放期间,在每个标记的提交上执行命令行 shell 脚本。一个有用的示例是在特定提交上运行代码库的测试套件,这可能有助于识别变基期间的回归。
o---o---o---o---o main \ o---o---o---o---o featureA \ o---o---o featureB
featureB 基于 featureA,但是,我们意识到 featureB 不依赖于 featureA 的任何更改,并且可以从 main 中分支出来。
1
git rebase --onto main featureA featureB
featureA 是<oldbase>,main 是<newbase>,featureB 是<newbase>的 HEAD 所指向的引用。结果如下
1 2 3 4 5 6
o---o---o featureB / o---o---o---o---o main \ o---o---o---o---o featureA
了解rebase的危险
使用 Git Rebase 时需要考虑的一个警告是,在 rebase 工作流程中,合并冲突可能会变得更加频繁。如果您有一个长期存在的分支偏离了主分支,就会发生这种情况。最终你会想要针对 main 进行 rebase,那时它可能包含许多新的提交,你的分支更改可能会与这些提交发生冲突。这一点很容易解决,只要频繁地针对主分支rebase,并进行更频繁的提交即可。在处理冲突时,可以向 git rebase 传递 –continue 和 –abort 命令行参数,以推进或重置rebase。
更严重的变基警告是交互式历史重写造成的提交丢失。在交互模式下运行 rebase 并执行 squash 或 drop 等子命令,会从分支的即时日志中删除提交。乍一看,这些提交好像永远消失了。使用 git reflog 可以恢复这些提交,并撤销整个rebase。有关使用 git reflog 查找丢失提交的更多信息,请访问我们的 Git reflog 文档页面。
Git Rebase 本身并没有严重危险。当执行交互式变基重写历史并强制将结果推送到由其他用户共享的远程分支时,真正的危险情况就会出现。这是一种应该避免的模式,因为它能够在其他远程用户拉取时覆盖他们的工作。
eff544f HEAD@{0}: commit: migrate existing content bf871fd HEAD@{1}: commit: Add Git Reflog outline 9a4491f HEAD@{2}: checkout: moving from main to git_reflog 9a4491f HEAD@{3}: checkout: moving from Git_Config to main 39b159a HEAD@{4}: commit: expand on git context 9b3aa71 HEAD@{5}: commit: more color clarification f34388b HEAD@{6}: commit: expand on color support 9962aed HEAD@{7}: commit: a git editor -> the Git editor
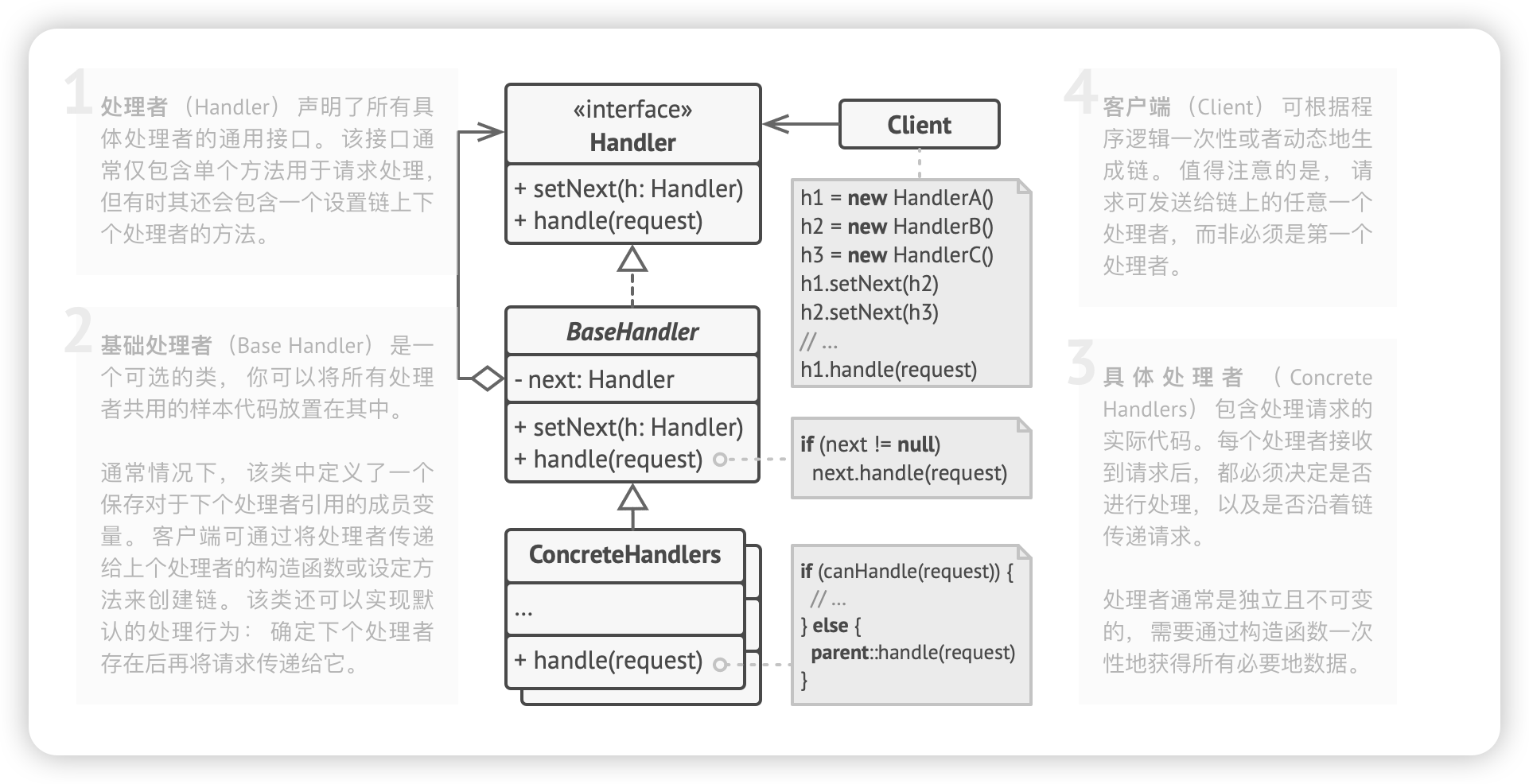
/** * The type of this request, used by each item in the chain to see if they should or can handle * this particular request. */ privatefinal RequestType requestType;
/** * The name of the request. */ privatefinal String name;
/** * Indicates if the request is handled or not. A request can only switch state from unhandled to * handled, there's no way to 'unhandle' a request. */ privateboolean handled;
privatevoidbuildRequestChain(){ handlers = Arrays.asList(new OrcCommander(), new OrcOfficer(), new OrcSoldier()); for (int i = 0; i < handlers.size() - 1; i++) { handlers.get(i).setNextHandler(handlers.get(i +1)); } }
/** * Handle request by the chain. */ publicvoidmakeRequest(Request req){ handlers.get(0).handle(req); }
}
测试:
1 2 3 4 5 6 7 8
publicstaticvoidmain(String[] args){
Request request = new Request(RequestType.DEFEND_CASTLE, "defend castle"); OrcKing orcKing = new OrcKing(); orcKing.makeRequest(request);
System.out.println(request.isHandled()); }
程序输出:
1 2 3 4
Orc commander handle the request defend castle Orc Officer handle the request defend castle Orc Soldier handle the request defend castle true
var facade = new DwarvenGoldmineFacade(); facade.startNewDay(); facade.digOutGold(); facade.endDay();
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
DwarvenTunnelDigger wakes up. DwarvenTunnelDigger goes to the mine. DwarvenGoldDigger wakes up. DwarvenGoldDigger goes to the mine. DwarvenCartOperator wakes up. DwarvenCartOperator goes to the mine. DwarvenTunnelDigger creates another promising tunnel. DwarvenGoldDigger digs for gold. DwarvenCartOperator moves gold chunks out of the mine. DwarvenTunnelDigger goes home. DwarvenTunnelDigger goes to sleep. DwarvenGoldDigger goes home. DwarvenGoldDigger goes to sleep. DwarvenCartOperator goes home. DwarvenCartOperator goes to sleep.