注释
单行注释 - 以#和空格开头的部分
多行注释 - 三个引号开头,三个引号结尾
1 2 3 """ print('hello,world') """
变量和类型 变量命名 在Python中,变量命名需要遵循以下这些必须遵守硬性规则和强烈建议遵守的非硬性规则。
硬性规则:
变量名由字母(广义的Unicode字符,不包括特殊字符)、数字和下划线构成,数字不能开头。
大小写敏感(大写的a和小写的A是两个不同的变量)。
不要跟关键字(有特殊含义的单词,后面会讲到)和系统保留字(如函数、模块等的名字)冲突。
PEP 8要求:
用小写字母拼写,多个单词用下划线连接。
受保护的实例属性用单个下划线开头(后面会讲到)。
私有的实例属性用两个下划线开头(后面会讲到)。
类型 计算机中的变量是实际存在的数据或者说是存储器中存储数据的一块内存空间,变量的值可以被读取和修改,这是所有计算和控制的基础。计算机能处理的数据有很多种类型,除了数值之外还可以处理文本、图形、音频、视频等各种各样的数据,那么不同的数据就需要定义不同的存储类型。Python中的数据类型很多,而且也允许我们自定义新的数据类型(这一点在后面会讲到),我们先介绍几种常用的数据类型。
整型:Python中可以处理任意大小的整数(Python 2.x中有int和long两种类型的整数,但这种区分对Python来说意义不大,因此在Python 3.x中整数只有int这一种了),而且支持二进制(如0b100,换算成十进制是4)、八进制(如0o100,换算成十进制是64)、十进制(100)和十六进制(0x100,换算成十进制是256)的表示法。浮点型:浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,浮点数除了数学写法(如123.456)之外还支持科学计数法(如1.23456e2)。字符串型:字符串是以单引号或双引号括起来的任意文本,比如'hello'和"hello",字符串还有原始字符串表示法、字节字符串表示法、Unicode字符串表示法,而且可以书写成多行的形式(用三个单引号或三个双引号开头,三个单引号或三个双引号结尾)。布尔型:布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来(例如3 < 5会产生布尔值True,而2 == 1会产生布尔值False)。复数型:形如3+5j,跟数学上的复数表示一样,唯一不同的是虚部的i换成了j。实际上,这个类型并不常用,大家了解一下就可以了。
在Python中可以使用type函数对变量的类型进行检查。
1 2 3 4 5 6 7 8 9 10 a = 100 b = 12.345 c = 1 + 5j d = 'hello, world' e = True print(type (a)) print(type (b)) print(type (c)) print(type (d)) print(type (e))
类型转换 可以使用Python中内置的函数对变量类型进行转换。
int():将一个数值或字符串转换成整数,可以指定进制。float():将一个字符串转换成浮点数。str():将指定的对象转换成字符串形式,可以指定编码。chr():将整数转换成该编码对应的字符串(一个字符)。ord():将字符串(一个字符)转换成对应的编码(整数)。
格式化输出 下面的代码通过键盘输入两个整数来实现对两个整数的算术运算。
1 2 3 4 5 6 7 8 9 a = int (input ('a = ' )) b = int (input ('b = ' )) print('%d + %d = %d' % (a, b, a + b)) print('%d - %d = %d' % (a, b, a - b)) print('%d * %d = %d' % (a, b, a * b)) print('%d / %d = %f' % (a, b, a / b)) print('%d // %d = %d' % (a, b, a // b)) print('%d %% %d = %d' % (a, b, a % b)) print('%d ** %d = %d' % (a, b, a ** b))
说明 :上面的print函数中输出的字符串使用了占位符语法,其中%d是整数的占位符,%f是小数的占位符,%%表示百分号(因为百分号代表了占位符,所以带占位符的字符串中要表示百分号必须写成%%),字符串之后的%后面跟的变量值会替换掉占位符然后输出到终端中,运行上面的程序,看看程序执行结果就明白啦。
除了这种格式化字符串的方式外,还可以用下面的方式来格式化字符串
1 2 3 a1 = float (input ('a1 = ' )) b1 = float (input ('a1 = ' )) print(f'{a1} + {b1} = {a1 + b1} ' )
分支结构 if语句的使用 虽然都是用 if 关键词定义判断,但与C,Java 等语言不同,Python 不使用 {}将if 语句控制的区域包含起来。Python 使用的是缩进方法。同时,也不需要用 ()将判断条件括起来。
一个完整的 if结构通常如下所示(注意:条件后的 :是必须要的,缩进值需要一样):
1 2 3 4 5 6 7 if <condition 1>: <statement 1> <statement 2> elif <condition 2>: <statements> else: <statements>
1 2 3 4 5 6 7 8 x = 0 if x > 0 : print "x is positive" elif x == 0 : print "x is zero" else : print "x is negative" x is zero
elif的个数没有限制,可以是1个或者多个,也可以没有。
else 最多只有1个,也可以没有。
可以使用 and ,or, not等关键词结合多个判断条件:
1 2 3 x = 10 y = -5 x > 0 and y < 0
这里使用这个简单的例子,假如想判断一个年份是不是闰年,按照闰年的定义,这里只需要判断这个年份是不是能被4整除,但是不能被100整除,或者正好被400整除:
1 2 3 4 5 6 7 8 9 year = 1900 if year % 400 == 0 : print "This is a leap year!" elif year % 4 == 0 and year % 100 != 0 : print "This is a leap year!" else : print "This is not a leap year." This is not a leap year.
循环结构 循环结构就是程序中控制某条或某些指令重复执行的结构。在Python中构造循环结构有两种做法,一种是for-in循环,一种是while循环。
for-in循环 1 2 for <variable> in <sequence>: <indented block of code>
如果明确的知道循环执行的次数或者要对一个容器进行迭代(后面会讲到),那么我们推荐使用for-in循环,例如下面代码中计算1~100求和的结果
1 2 3 4 sum = 0 for x in range (101 ): sum += x print(sum )
需要说明的是上面代码中的range(1, 101)可以用来构造一个从1到100的范围,当我们把这样一个范围放到for-in循环中,就可以通过前面的循环变量x依次取出从1到100的整数。当然,range的用法非常灵活,下面给出了一个例子:
range(101):可以用来产生0到100范围的整数,需要注意的是取不到101。range(1, 101):可以用来产生1到100范围的整数,相当于前面是闭区间后面是开区间。range(1, 101, 2):可以用来产生1到100的奇数,其中2是步长,即每次数值递增的值。range(100, 0, -2):可以用来产生100到1的偶数,其中-2是步长,即每次数字递减的值。
知道了这一点,我们可以用下面的代码来实现1~100之间的偶数求和。
1 2 3 4 sum = 0 for x in range (2 , 101 , 2 ): sum += x print(sum )
while循环 while 循环
1 2 while <condition>: <statesments>
Python 会循环执行<statesments>,直到<condition>不满足为止。
例如,计算数字0到1000000的和:
1 2 3 4 5 6 i = 0 total = 0 while i < 1000000 : total += i i += 1 print total
continue 语句 遇到 continue 的时候,程序会返回到循环的最开始重新执行。
例如在循环中忽略一些特定的值:
1 2 3 4 5 6 values = [7 , 6 , 4 , 7 , 19 , 2 , 1 ] for i in values: if i % 2 != 0 : continue print i/2
break 语句 遇到 break 的时候,程序会跳出循环,不管循环条件是不是满足
else语句 与 if 一样, while 和 for 循环后面也可以跟着 else 语句,不过要和break 一起连用。
当循环正常结束时,循环条件不满足, else 被执行;
当循环被 break 结束时,循环条件仍然满足, else 不执行。
不执行:
1 2 3 4 5 6 7 values = [7 , 6 , 4 , 7 , 19 , 2 , 1 ] for x in values: if x <= 10 : print 'Found:' , x break else : print 'All values greater than 10'
执行:
1 2 3 4 5 6 7 values = [11 , 12 , 13 , 100 ] for x in values: if x <= 10 : print 'Found:' , x break else : print 'All values greater than 10'
1 All values greater than 10
容器型数据类型 容器型数据类型包括:
类型
例子
列表(list)[1, 1.2, 'hello']
元组(Tuple)(10, 11, 12, 13, 14)
集合(set){1, 2, 3, 1}
字典(dict){'dogs': 5, 'pigs': 3}
Numpy数组array([1, 2, 3])
列表 在Python 中,列表是一个有序的序列。
列表用一对 [] 生成,中间的元素用 ,隔开,其中的元素不需要是同一类型,同时列表的长度也不固定。
1 2 3 l = [1 , 2.0 , 'hello' ] print l[1 , 2.0 , 'hello' ]
空列表可以用 [] 或者 list() 生成:
1 2 empty_list = [] empty_list
1 2 empty_list = list () empty_list
列表操作
与字符串类似,列表也支持以下的操作:
长度 用 len 查看列表长度:
加法和乘法
列表加法,相当于将两个列表按顺序连接:
1 2 3 a = [1 , 2 , 3 ] b = [3.2 , 'hello' ] a + b
列表与整数相乘,相当于将列表重复相加:
1 [1, 2.0, 'hello', 1, 2.0, 'hello']
索引和分片 列表和字符串一样可以通过索引和分片来查看它的元素。
索引:
1 2 a = [10 , 11 , 12 , 13 , 14 ] a[0 ]
反向索引:
分片:
与字符串不同的是,列表可以通过索引和分片来修改。
对于字符串,如果我们通过索引或者分片来修改,Python 会报错:
1 2 3 4 5 6 7 8 9 10 11 s = "hello world" s[0] = 'H' --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-10-844622ced67a> in <module>() 1 s = "hello world" 2 ----> 3 s[0] = 'H' TypeError: 'str' object does not support item assignment
而这种操作对于列表来说是可以的:
1 2 3 a = [10 , 11 , 12 , 13 , 14 ] a[0 ] = 100 print(a)
这种赋值也适用于分片,例如,将列表的第2,3两个元素换掉:
1 2 a[1 :3 ] = [1 , 2 ] print(a)
事实上,对于连续的分片(即步长为 1 ),Python 采用的是整段替换的方法,两者的元素个数并不需要相同,例如,将 [11,12] 替换为 [1,2,3,4]:
1 2 3 4 a = [10 , 11 , 12 , 13 , 14 ] a[1 :3 ] = [1 , 2 , 3 , 4 ] print a[10 , 1 , 2 , 3 , 4 , 13 , 14 ]
这意味着,可以用这种方法来删除列表中一个连续的分片:
1 2 3 4 5 6 a = [10 , 1 , 2 , 11 , 12 ] print a[1 :3 ]a[1 :3 ] = [] print a[1 , 2 ] [10 , 11 , 12 ]
对于不连续(间隔step不为1)的片段进行修改时,两者的元素数目必须一致:
1 2 3 a = [10 , 11 , 12 , 13 , 14 ] a[::2 ] = [1 , 2 , 3 ] a
否则会报错:
1 2 3 4 5 6 7 a[::2] = [] --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-16-7b6c4e43a9fa> in <module>() ----> 1 a[::2] = [] ValueError: attempt to assign sequence of size 0 to extended slice of size 3
添加或删除元素 向列表添加单个元素 l.append(ob) 将元素 ob 添加到列表 l 的最后。
1 2 3 4 a = [10 , 11 , 12 ] a.append(11 ) print(a) [10 , 11 , 12 , 11 ]
append每次只添加一个元素,并不会因为这个元素是序列而将其展开:
1 2 3 a.append([11 , 12 ]) print(a) [10 , 11 , 12 , 11 , [11 , 12 ]]
向列表添加序列 l.extend(lst) 将序列 lst 的元素依次添加到列表 l 的最后,作用相当于 l += lst。
1 2 3 a = [10 , 11 , 12 , 11 ] a.extend([1 , 2 ]) print(a)
插入元素 l.insert(idx, ob) 在索引 idx 处插入ob ,之后的元素依次后移。
1 2 3 4 a = [10 , 11 , 12 , 13 , 11 ] a.insert(3 , 'a' ) print(a)
1 [10, 11, 12, 'a', 13, 11]
删除元素 Python 提供了删除列表中元素的方法del。
删除列表中的第一个元素:
1 2 3 4 a = [1002 , 'a' , 'b' , 'c' ] del a[0 ]print(a) ['a' , 'b' , 'c' ]
删除第2到最后一个元素:
1 2 3 a = [1002 , 'a' , 'b' , 'c' ] del a[1 :]print(a)
删除间隔的元素:
1 2 3 a = ['a' , 1 , 'b' , 2 , 'c' ] del a[::2 ]print(a)
移除元素 l.remove(ob) 会将列表中第一个出现的 ob 删除,如果 ob 不在 l 中会报错。
1 2 3 4 5 a = [10 , 11 , 12 , 13 , 11 ] a.remove(11 ) print a[10 , 12 , 13 , 11 ]
弹出元素 l.pop(idx) 会将索引 idx 处的元素删除,并返回这个元素。
1 2 a = [10 , 11 , 12 , 13 , 11 ] a.pop(2 )
列表遍历 1 2 3 4 5 6 7 8 9 10 list1 = [1 , 3 , 5 , 7 , 9 ] for index in range (len (list1)): print(list1[index]) for elem in list1: print(elem) for index, elem in enumerate (list1): print(index, elem)
列表方法 测试从属关系 用 in 来看某个元素是否在某个序列(不仅仅是列表)中,用not in来判断是否不在某个序列中。
1 2 3 4 5 a = [10 , 11 , 12 , 13 , 14 ] print(10 in a) print(10 not in a) True False
也可以作用于字符串:
1 2 3 4 5 s = 'hello world' print('he' in s) print('world' not in s) True False
列表中可以包含各种对象,甚至可以包含列表:
1 2 a = [10 , 'eleven' , [12 , 13 ]] a[2 ]
a[2]是列表,可以对它再进行索引:
列表中某个元素个数count l.count(ob) 返回列表中元素 ob 出现的次数。
1 2 a = [11 , 12 , 13 , 12 , 11 ] a.count(11 )
列表中某个元素位置index l.index(ob) 返回列表中元素 ob 第一次出现的索引位置,如果 ob 不在 l 中会报错。
排序 l.sort() 会将列表中的元素按照一定的规则排序:
1 2 3 4 a = [10 , 1 , 11 , 13 , 11 , 2 ] a.sort() print(a) [1 , 2 , 10 , 11 , 11 , 13 ]
如果不想改变原来列表中的值,可以使用 sorted 函数:
1 2 3 4 5 6 a = [10 , 1 , 11 , 13 , 11 , 2 ] b = sorted (a) print(a) print(b) [10 , 1 , 11 , 13 , 11 , 2 ] [1 , 2 , 10 , 11 , 11 , 13 ]
列表反向 l.reverse() 会将列表中的元素从后向前排列。
1 2 3 4 a = [1 , 2 , 3 , 4 , 5 , 6 ] a.reverse() print(a) [6 , 5 , 4 , 3 , 2 , 1 ]
如果不想改变原来列表中的值,可以使用这样的方法:
1 2 3 4 5 6 a = [1 , 2 , 3 , 4 , 5 , 6 ] b = a[::-1 ] print(a) print(b) [1 , 2 , 3 , 4 , 5 , 6 ] [6 , 5 , 4 , 3 , 2 , 1 ]
元组 与列表相似,元组Tuple也是个有序序列,但是元组是不可变的,用()生成。
1 2 t = (10 , 11 , 12 , 13 , 14 ) t
可以索引,切片:
但是元组是不可变的:
1 2 3 4 5 6 7 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-4-da6c1cabf0b0> in <module>() 1 ----> 2 t[0] = 1 TypeError: 'tuple' object does not support item assignment
单个元素的元组生成 由于()在表达式中被应用,只含有单个元素的元组容易和表达式混淆,所以采用下列方式定义只有一个元素的元组:
1 2 3 4 5 a = (10 ,) print(a) print(type (a)) (10 ,) <type 'tuple' >
1 2 3 a = (10 ) print(type (a)) <type 'int' >
将列表转换为元组:
1 2 a = [10 , 11 , 12 , 13 , 14 ] tuple (a)
元组方法 由于元组是不可变的,所以只能有一些不可变的方法,例如计算元素个数 count 和元素位置 index ,用法与列表一样。
字符串 Python 中可以使用一对单引号’’或者双引号””生成字符串。
1 2 3 s = "hello, world" print shello, world
1 2 3 s = 'hello world' print shello world
1 2 3 4 hello, world! hello, python!
Python 用一对 """ 或者 ''' 来生成多行字符串:
1 2 3 4 5 6 7 strs = ''' hello, world! hello, python! ''' print(strs)
可以在字符串中使用(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;而\t也不是代表反斜杠和字符t,而是表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。可以运行下面的代码看看会输出什么。
1 2 3 s1 = '\'hello, world!\'' s2 = '\n\\hello, world!\\\n' print(s1, s2, end='' )
1 2 'hello, world!' \hello, world!\
我们可以通过在字符串的最前面加上字母r来表示原始字符
1 2 3 s1 = r'\'hello, world!\'' s2 = r'\n\\hello, world!\\\n' print(s1, s2, end='' )
1 \'hello, world!\' \n\\hello, world!\\\n
格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母f,我们可以使用下面的语法糖来简化上面的代码。
1 2 a, b = 5 , 10 print(f'{a} * {b} = {a * b} ' )
简单操作 加法:
1 2 s = 'hello ' + 'world' print(s)
字符串与数字相乘:
字符串长度:
使用in和not in来判断一个字符串是否包含另外一个字符串(成员运算)
1 2 3 s = 'hello,world' print('hello' in s) //True print('good' in s) //False
索引和切片 我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符(切片运算)
1 2 3 4 5 6 7 8 9 10 s = 'hello,world' print(s[2 ]) print(s[2 :5 ]) print(s[2 :]) print(s[2 ::2 ]) print(s[::2 ]) print(s[::-1 ]) print(s[-3 :-1 ])
字符串的遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // 第一种方式,for in strs = 'hello,world' for s in strs: print(s) // 第二种方式,内置函数range ()或xrange() for i in range (len (strs)): print(strs[i]) // 第三种方式,内置函数enumerate () for index, str in enumerate (strs): print(index,str ) // 第四种方式,内置函数iter () for str in iter (strs): print(str )
字符串方法 大小写转换 s.upper()方法返回一个将s中的字母全部大写的新字符串。
s.lower()方法返回一个将s中的字母全部小写的新字符串。
这两种方法也不会改变原来s的值:
1 2 3 s = "HELLO WORLD" print(s.lower()) print(s)
首字母大写 s.capitalize()方法返回一个将s中首字母大写的新字符串。
1 2 s = 'hello,world' print(s.capitalize()) //Hello,world
s.title()方法返回一个将s中每个首字母大写的新字符串。
1 2 print(s.title()) Hello,World
查找子串 s.index()从左到右查找子串,可以指定起始查找位置,默认是0
s.rindex() 则是从右向左查找
1 2 3 4 s = 'hello,world' print(s.index('l' )) print(s.index('l' ,3 )) print(s.rindex('l' ))
如果查找不到则会程序报错
1 2 3 4 Traceback (most recent call last): File "/Users/mac7/PycharmProjects/pythonBasic/helloworld.py", line 114, in <module> print(s.index('re')) ValueError: substring not found
s.find() 查找不到则会返回-1
1 2 print(s.find('l' )) print(s.find('oo' ))
格式化输出 1 2 3 4 5 6 7 8 9 10 11 12 13 print(s.center(50 , '*' )) print(s.rjust(50 , '-' )) print(s.ljust(50 , '-' )) n = '12345' print(n.zfill(10 )) n = '12345' print(n.zfill(5 )) // 12345
1 2 3 4 *******************hello,world******************** ---------------------------------------hello,world hello,world--------------------------------------- 0000012345
格式化字符串 Python 用字符串的format()方法来格式化字符串。
具体用法如下,字符串中花括号 {} 的部分会被format传入的参数替代,传入的值可以是字符串,也可以是数字或者别的对象。
1 2 a, b = 5 , 10 print('{} * {} = {}' .format (a, b, a * b))
可以用数字指定传入参数的相对位置:
1 '{2} {1} {0}' .format ('a' , 'b' , 'c' )
还可以指定传入参数的名称:
1 '{color} {n} {x}' .format (n=10 , x=1.5 , color='blue' )
可以在一起混用:
1 '{color} {0} {x} {1}' .format (10 , 'foo' , x = 1.5 , color='blue' )
Python 3.6以后,格式化字符串还有更为简洁的书写方式,就是在字符串前加上字母f,我们可以使用下面的语法糖来简化上面的代码。
1 2 a, b = 5 , 10 print(f'{a} * {b} = {a * b} ' )
去除多余空格 s.strip()返回一个将s两端的多余空格除去的新字符串。
s.lstrip()返回一个将s开头的多余空格除去的新字符串。
s.rstrip()返回一个将s结尾的多余空格除去的新字符串。
1 2 s = " hello world " s.strip()
s的值依然不会变化:
分割与连接 s.split()将s按照空格(包括多个空格,制表符\t,换行符\n等)分割,并返回所有分割得到的字符串。
1 2 3 4 line = "1 2 3 4 5" numbers = line.split() print numbers['1' , '2' , '3' , '4' , '5'
s.split(sep)以给定的sep为分隔符对s进行分割。
1 2 3 4 line = "1,2,3,4,5" numbers = line.split(',' ) print numbers['1' , '2' , '3' , '4' , '5' ]
源码定义如下:
1 2 3 4 5 6 7 8 9 10 11 def split (self, *args, **kwargs ): """ Return a list of the words in the string, using sep as the delimiter string. sep 参数一:指定的分割字符 The delimiter according which to split the string. None (the default value) means split according to any whitespace, and discard empty strings from the result. maxsplit 参数二:最大允许分割数量,不指定则默认-1 Maximum number of splits to do. -1 (the default value) means no limit.
1 2 3 line = "1,2,3,4,5,6" numbers = line.split("," ,maxsplit=3 ) print(numbers)
1 ['1', '2', '3', '4,5,6']
s.rsplit()则是从右向左拆分
1 2 s = "i love you" print(s.rsplit(" " , 1 ))
与分割相反,s.join(str_sequence)的作用是以s为连接符将字符串序列str_sequence中的元素连接起来,并返回连接后得到的新字符串:
1 2 3 4 strList = ["i" ,"love" ,"you" ] s = ' ' joinStr = s.join(strList) print(joinStr)
集合 之前看到的列表和字符串都是一种有序序列,而集合 set 是一种无序的序列。
因为集合是无序的,所以当集合中存在两个同样的元素的时候,Python只会保存其中的一个(唯一性);同时为了确保其中不包含同样的元素,集合中放入的元素只能是不可变的对象(确定性)。
定义集合 可以用set()函数来显示的生成空集合:
也可以使用一个列表来初始化一个集合:
1 2 a = set ([1 , 2 , 3 , 1 ]) print(a)
集合会自动去除重复元素 1。
可以看到,集合中的元素是用大括号{}包含起来的,这意味着可以用{}的形式来创建集合:
1 2 a = {1 , 2 , 3 , 1 } print(a)
但是创建空集合的时候只能用set来创建,因为在Python中{}创建的是一个空的字典:
成员运算 集合的成员变量在效率上是远远高于列表运算
1 2 3 set = {1 ,2 ,3 ,4 ,5 }print(1 in set ) print(7 not in set )
集合操作 假设有这样两个集合:
1 2 a = {1 , 2 , 3 , 4 } b = {3 , 4 , 5 , 6 }
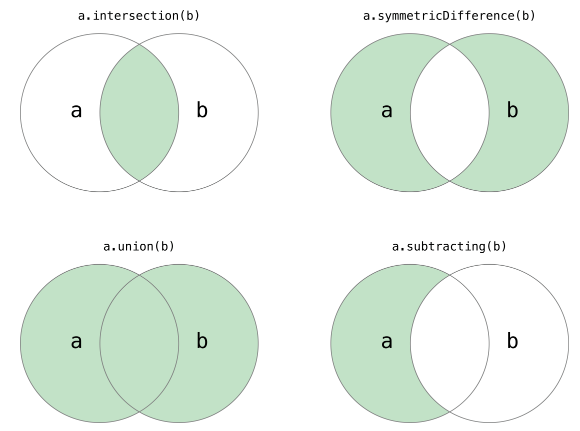
并 两个集合的并,返回包含两个集合所有元素的集合(去除重复)。
可以用方法 a.union(b) 或者操作 a | b 实现。
交 两个集合的交,返回包含两个集合共有元素的集合。
可以用方法 a.intersection(b) 或者操作 a & b 实现。
1 2 print(a & b) set([3, 4])
注意:一般使用print打印set的结果与表示方法并不一致。
差 a 和 b 的差集,返回只在 a 不在 b 的元素组成的集合。
可以用方法 a.difference(b) 或者操作 a - b 实现。
注意,a - b 与 b - a并不一样,b - a 返回的是返回 b 不在 a 的元素组成的集合:
对称差 a 和b 的对称差集,返回在 a 或在 b 中,但是不同时在 a 和 b 中的元素组成的集合。
可以用方法 a.symmetric_difference(b) 或者操作 a ^ b 实现(异或操作符)。
1 a.symmetric_difference(b)
1 b.symmetric_difference(a)
包含关系 假设现在有这样两个集合:
1 2 a = {1 , 2 , 3 } b = {1 , 2 }
要判断 b 是不是 a 的子集,可以用 b.issubset(a) 方法,或者更简单的用操作 b <= a :
与之对应,也可以用 a.issuperset(b) 或者 a >= b 来判断:
方法只能用来测试子集,但是操作符可以用来判断真子集:
自己不是自己的真子集:
集合方法 add 方法向集合添加单个元素跟列表的 append 方法类似,用来向集合添加单个元素。
将元素 a 加入集合 s 中。
1 2 3 t = {1 , 2 , 3 } t.add(5 ) print(t)
如果添加的是已有元素,集合不改变:
update 方法向集合添加多个元素跟列表的extend方法类似,用来向集合添加多个元素。
将seq中的元素添加到s中。
1 2 t.update([5 , 6 , 7 ]) print(t)
remove 方法移除单个元素从集合s中移除元素ob,如果不存在会报错。
1 2 3 4 5 6 7 t.remove(10) --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-31-3bc25c5e1ff4> in <module>() ----> 1 t.remove(10) KeyError: 10
pop方法弹出元素 由于集合没有顺序,不能像列表一样按照位置弹出元素,所以pop 方法删除并返回集合中任意一个元素,如果集合中没有元素会报错。
1 2 print(t) set ([3 , 5 , 6 , 7 ])
1 2 3 4 5 6 7 8 9 10 11 s = set() # 报错 s.pop() --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-34-9f9e06c962e6> in <module>() 1 s = set() 2 # 报错 ----> 3 s.pop() KeyError: 'pop from an empty set'
discard 方法 作用与 remove 一样,但是当元素在集合中不存在的时候不会报错。
不存在的元素不会报错:
difference_update方法 从a中去除所有属于b的元素:
清空集合 字典 字典 dictionary ,在一些编程语言中也称为 hash , map ,是一种由键值对组成的数据结构。
顾名思义,我们把键想象成字典中的单词,值想象成词对应的定义,那么——
一个词可以对应一个或者多个定义,但是这些定义只能通过这个词来进行查询。
初始化字典 1 2 3 4 5 6 b = {'one' : 'this is number 1' , 'two' : 'this is number 2' } items1 = dict (one=1 , two=2 , three=3 , four=4 ) items3 = {num: num ** 2 for num in range (1 , 10 )}
Python 使用 {} 或者 dict() 来创建一个空的字典:
基本操作 有了dict之后,可以用索引键值的方法向其中添加元素,也可以通过索引来查看元素的值:
插入键值 1 2 3 a["one" ] = "this is number 1" a["two" ] = "this is number 2" print(a)
1 {'one': 'this is number 1', 'two': 'this is number 2'}
查看键值 更新键值 1 2 a["one" ] = "this is number 1, too" a
1 {'one': 'this is number 1, too', 'two': 'this is number 2'}
遍历 1 2 3 4 5 6 7 8 9 10 11 12 dic = dict (one=1 , two=2 , three=3 , four=4 ) for key in dic: print(f'{key} : {dic[key]} ' ) for value in dic.values(): print(value) for key, value in dic.items(): print(key, value)
字典没有顺序 当我们 print 一个字典时,Python 并不一定按照插入键值的先后顺序进行显示,因为字典中的键本身不一定是有序的。
1 2 print a{'two' : 'this is number 2' , 'one' : 'this is number 1, too' }
1 2 print b{'two' : 'this is number 2' , 'one' : 'this is number 1' }
因此,Python 中不能用支持用数字索引按顺序查看字典中的值,而且数字本身也有可能成为键值,这样会引起混淆:
1 2 3 4 5 6 7 8 9 # 会报错 a[0] --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-9-cc39af2a359c> in <module>() 1 # 会报错 ----> 2 a[0] KeyError: 0
使用 dict 初始化字典 除了通常的定义方式,还可以通过 dict() 转化来生成字典:
1 2 3 4 5 6 7 inventory = dict ( [('foozelator' , 123 ), ('frombicator' , 18 ), ('spatzleblock' , 34 ), ('snitzelhogen' , 23 ) ]) inventory
1 {'foozelator': 123, 'frombicator': 18, 'snitzelhogen': 23, 'spatzleblock': 34}
利用索引直接更新键值对:
1 2 inventory['frombicator' ] += 1 inventory
1 {'foozelator': 123, 'frombicator': 19, 'snitzelhogen': 23, 'spatzleblock': 34}
适合做键的类型 在不可变类型中,整数和字符串是字典中最常用的类型;而浮点数通常不推荐用来做键,原因如下:
1 2 3 4 5 6 7 8 9 10 11 12 data = {} data[1.1 + 2.2 ] = 6.6 data[3.3 ] --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input -16 -a48e87d01daa> in <module>() 2 data[1.1 + 2.2 ] = 6.6 3 ----> 4 data[3.3] KeyError: 3.3
事实上,观察data的值就会发现,这个错误是由浮点数的精度问题所引起的:
1 {3.3000000000000003: 6.6}
有时候,也可以使用元组作为键值,例如,可以用元组做键来表示从第一个城市飞往第二个城市航班数的多少:
1 2 3 4 connections = {} connections[('New York' , 'Seattle' )] = 100 connections[('Austin' , 'New York' )] = 200 connections[('New York' , 'Austin' )] = 400
元组是有序的,因此 ('New York', 'Austin') 和 ('Austin', 'New York') 是两个不同的键:
1 2 3 4 print connections[('Austin' , 'New York' )]print connections[('New York' , 'Austin' )]200 400
字典方法 get 方法之前已经见过,用索引可以找到一个键对应的值,但是当字典中没有这个键的时候,Python会报错,这时候可以使用字典的 get 方法来处理这种情况,其用法如下:
1 d.get(key, default = None )
返回字典中键 key 对应的值,如果没有这个键,返回 default 指定的值(默认是 None )。
1 2 3 a = {} a["one" ] = "this is number 1" a["two" ] = "this is number 2"
索引不存在的键值会报错:
1 2 3 4 5 6 7 a["three"] --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-22-8a5f2913f00e> in <module>() ----> 1 a["three"] KeyError: 'three'
改用get方法:
1 2 print a.get("three" )None
指定默认值参数:
1 a.get("three" , "undefined" )
pop 方法删除元素pop() 方法可以用来弹出字典中某个键对应的值,同时也可以指定默认参数:
1 d.pop(key, default = None )
删除并返回字典中键 key 对应的值,如果没有这个键,返回 default 指定的值(默认是 None )。
1 {'one': 'this is number 1', 'two': 'this is number 2'}
弹出并返回值:
1 {'one': 'this is number 1'}
弹出不存在的键值:
1 a.pop("two" , 'not exist' )
与列表一样,del 函数可以用来删除字典中特定的键值对,例如:
可以用popItem() 方法删除最后一个元素
update方法更新字典之前已经知道,可以通过索引来插入、修改单个键值对,但是如果想对多个键值对进行操作,这种方法就显得比较麻烦,好在有 update 方法:
将字典newd中的内容更新到d中去。
1 2 3 4 5 6 person = {} person['first' ] = "Jmes" person['last' ] = "Maxwell" person['born' ] = 1831 print person{'born' : 1831 , 'last' : 'Maxwell' , 'first' : 'Jmes' }
把’first’改成’James’,同时插入’middle’的值’Clerk’:
1 2 3 4 person_modifications = {'first' : 'James' , 'middle' : 'Clerk' } person.update(person_modifications) print person{'middle' : 'Clerk' , 'born' : 1831 , 'last' : 'Maxwell' , 'first' : 'James' }
类似的方法还有a.setdefault()
If key is in the dictionary, return its value.If not, insert key with a value of default and return default. default defaults to None.
in查询字典中是否有该键1 barn = {'cows' : 1 , 'dogs' : 5 , 'cats' : 3 }
in 可以用来判断字典中是否有某个特定的键:
字典键值互换 1 2 3 a = {'one' : 1 , 'two' : 2 , 'three' : 3 } b = dict (zip (a.values(),a.keys())) print(b)
1 {1: 'one', 2: 'two', 3: 'three'}
函数 定义函数 函数function ,通常接受输入参数,并有返回值。
它负责完成某项特定任务,而且相较于其他代码,具备相对的独立性。
1 2 3 4 def add (x, y ): """Add two numbers""" a = x + y return a
函数通常有一下几个特征:
使用 def 关键词来定义一个函数。
def 后面是函数的名称,括号中是函数的参数,不同的参数用 , 隔开, def foo(): 的形式是必须要有的,参数可以为空;使用缩进来划分函数的内容;
docstring 用 """ 包含的字符串,用来解释函数的用途,可省略;return 返回特定的值,如果省略,返回 None 。
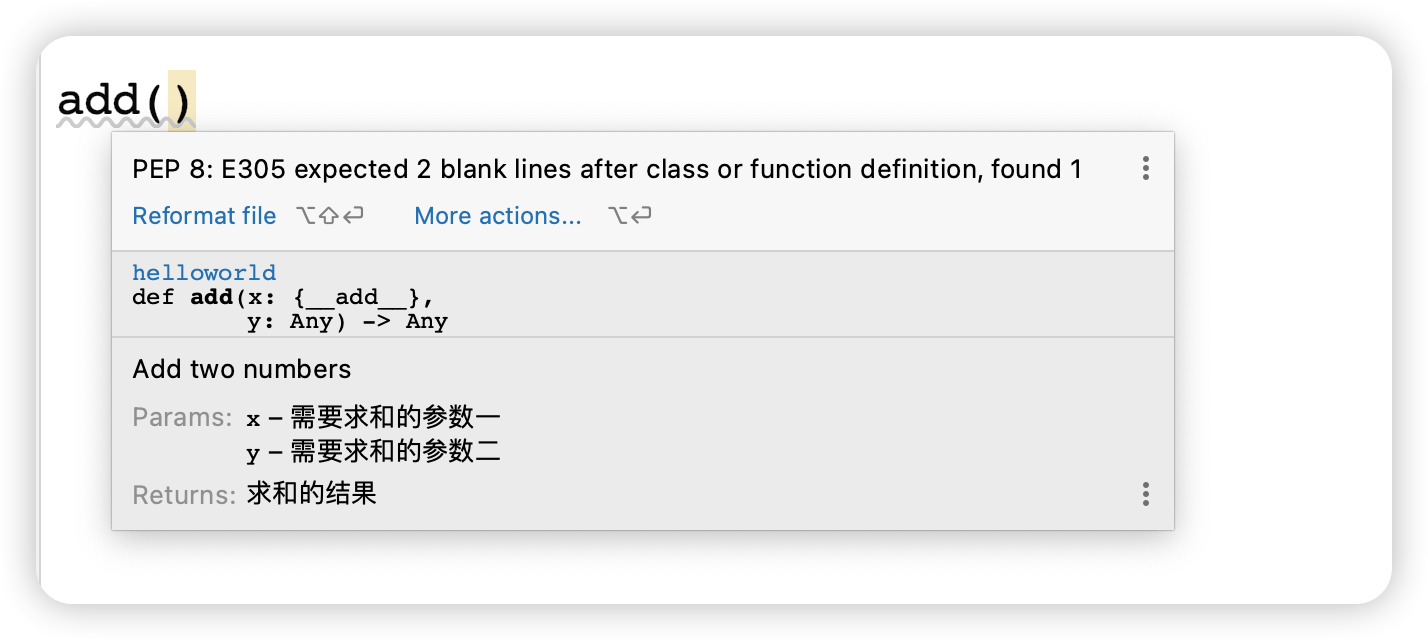
函数的文档注释:
1 2 3 4 5 6 7 8 9 10 def add (x, y ): """ Add two numbers :param x: 需要求和的参数一 :param y: 需要求和的参数二 :return: 求和的结果 """ a = x + y return a
效果如下:
使用函数 使用函数时,只需要将参数换成特定的值传给函数。
Python 并没有限定参数的类型,因此可以使用不同的参数类型:
1 2 print add(2 , 3 ) print add('foo' , 'bar' )
在这个例子中,如果传入的两个参数不可以相加,那么Python 会将报错:
1 2 3 4 5 6 7 8 9 10 11 12 13 print add(2 , "foo" )--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input -3 -6 f8dcf7eb280> in <module>() ----> 1 print add(2, "foo") <ipython-input -1 -e831943cfaf2> in add(x, y) 1 def add (x, y ): 2 """Add two numbers""" ----> 3 a = x + y 4 return a TypeError: unsupported operand type (s) for +: 'int' and 'str'
如果传入的参数数目与实际不符合,也会报错:
1 2 3 4 5 6 7 print add(1 , 2 , 3 )--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input -4 -ed7bae31fc7d> in <module>() ----> 1 print add(1, 2, 3) TypeError: add() takes exactly 2 arguments (3 given)
1 2 3 4 5 6 7 print add(1 )--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input -5 -a954233d3b0d> in <module>() ----> 1 print add(1) TypeError: add() takes exactly 2 arguments (1 given)
传入参数时,Python提供了两种选项,第一种是上面使用的按照位置传入参数,另一种则是使用关键词模式,显式地指定参数的值:
1 2 3 4 print add(x=2 , y=3 )print add(y="foo" , x="bar" )5 barfoo
可以混合这两种模式:
设定参数默认值 可以在函数定义的时候给参数设定默认值,例如:
1 2 def quad (x, a=1 , b=0 , c=0 ): return a*x**2 + b*x + c
可以省略有默认值的参数:
可以修改参数的默认值:
1 2 print quad(2.0 , b=3 )10.0
1 2 print quad(2.0 , 2 , c=4 )12.0
这里混合了位置和指定两种参数传入方式,第二个2是传给 a 的。
注意,在使用混合语法时,要注意不能给同一个值赋值多次,否则会报错,例如:
1 2 3 4 5 6 7 print quad(2.0, 2, a=2) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-12-101d0c090bbb> in <module>() ----> 1 print quad(2.0, 2, a=2) TypeError: quad() got multiple values for keyword argument 'a'
作用域 A scope is a textual region of a Python program where a namespace is directly accessible. “Directly accessible” here means that an unqualified reference to a name attempts to find the name in the namespace.
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种,分别是:
有四种作用域:
L(Local) :最内层,包含局部变量,比如一个函数/方法内部。E(Enclosing) :包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。G(Global) :当前脚本的最外层,比如当前模块的全局变量。B(Built-in) : 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B 。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
1 2 3 4 5 g_count = 0 def outer (): o_count = 1 def inner (): i_count = 2
内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在Python3.0中,可以使用以下的代码来查看到底预定义了哪些变量:
1 2 >>> import builtins >>> dir(builtins)
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
global 和 nonlocal关键字 当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了。
global声明使用全局变量或者将一个局部变量放到全局变量中
1 2 3 4 5 6 7 8 num = 1 def fun1 (): global num print(num) num = 123 print(num) fun1() print(num)
nonlocal声明使用嵌套作用域变量(不使用局部变量)
1 2 3 4 5 6 7 8 9 def outer (): num = 10 def inner (): nonlocal num num = 100 print(num) inner() print(num)
用模块管理函数 对于任何一种编程语言来说,给变量、函数这样的标识符起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个.py文件中定义了两个同名函数,由于Python没有函数重载的概念,那么后面的定义会覆盖之前的定义,也就意味着两个函数同名函数实际上只有一个是存在的。
1 2 3 4 5 6 7 8 9 10 def foo (): print('hello, world!' ) def foo (): print('goodbye, world!' ) foo()
当然上面的这种情况我们很容易就能避免,但是如果项目是由多人协作进行团队开发的时候,团队中可能有多个程序员都定义了名为foo的函数,那么怎么解决这种命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
1 2 def foo (): print('hello, world!' )
module2.py
1 2 def foo (): print('goodbye, world!' )
test.py
1 2 3 4 5 6 7 8 9 10 11 from module1 import foofoo() from module2 import foofoo()
也可以按照如下所示的方式来区分到底要使用哪一个foo函数。
test.py
1 2 3 4 5 import module1 as m1import module2 as m2m1.foo() m2.foo()
但是如果将代码写成了下面的样子,那么程序中调用的是最后导入的那个foo,因为后导入的foo覆盖了之前导入的foo。
test.py
1 2 3 4 5 from module1 import foo from module2 import foo # 输出goodbye, world! foo()
test.py
1 2 3 4 5 6 from module2 import foofrom module1 import foofoo()
需要说明的是,如果我们导入的模块除了定义函数之外还有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是”main “。
module3.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def foo (): pass def bar (): pass if __name__ == '__main__' : print('call foo()' ) foo() print('call bar()' ) bar()
test.py
接收不定参数 使用如下方法,可以使函数接受不定数目的参数:
1 2 3 4 5 def add (x, *args ): total = x for arg in args: total += arg return total
这里,*args 表示参数数目不定,可以看成一个元组,把第一个参数后面的参数当作元组中的元素。
1 2 3 4 print(add(1 , 2 , 3 , 4 )) print(add(1 , 2 )) 10 3
关键字参数 这样定义的函数不能使用关键词传入参数,要使用关键词,可以这样:
1 2 3 4 5 6 def add (x, **kwargs ): total = x for arg, value in kwargs.items(): print("adding " , arg) total += value return total
这里, **kwargs 表示参数数目不定,相当于一个字典,关键词和值对应于键值对。
1 print(add(10 , y=11 , z=12 , w=13 ))
1 2 3 4 adding y adding z adding w 46
再看这个例子,可以接收任意数目的位置参数和键值对参数:
1 2 3 4 5 def foo (*args, **kwargs ): print(args, kwargs) foo(2 , 3 , x='bar' , z=10 ) (2 , 3 ) {'x' : 'bar' , 'z' : 10 }
不过要按顺序传入参数,先传入位置参数 args ,在传入关键词参数 kwargs 。
命名关键字参数 如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。
1 2 3 4 def person (name, age, *, city, job ) print (name, age, city, job ) # 调用 person ('city' , 22 , city='Beijing' , job='IT'
输出:
和关键字参数**kw不同,命名关键字参数需要一个特殊的分隔符*,*后面的参数被视为命名关键字参数。
返回多个值 函数可以返回多个值:
1 2 3 4 5 6 7 8 9 10 from math import atan2def to_polar (x, y ): r = (x**2 + y**2 ) ** 0.5 theta = atan2(y, x) return r, theta r, theta = to_polar(3 , 4 ) print(r, theta) 5.0 0.927295218002
事实上,Python 将返回的两个值变成了元组:
1 2 print(to_polar(3 , 4 )) (5.0 , 0.9272952180016122 )
因为这个元组中有两个值,所以可以使用
1 r, theta = to_polar(3, 4)
给两个值赋值。
列表也有相似的功能:
1 2 a, b, c = [1 , 2 , 3 ] print(a, b, c)
事实上,不仅仅返回值可以用元组表示,也可以将参数用元组以这种方式传入:
1 2 3 4 5 6 7 def add (x, y ): """Add two numbers""" a = x + y return a z = (2 , 3 ) print add(*z)
这里的*必不可少。
事实上,还可以通过字典传入参数来执行函数:
1 2 3 4 5 6 7 def add (x, y ): """Add two numbers""" a = x + y return a w = {'x' : 2 , 'y' : 3 } print add(**w)
map 方法生成序列 可以通过 map 的方式利用函数来生成序列:
1 2 3 4 5 def sqr (x ): return x ** 2 a = [2 ,3 ,4 ] print map (sqr, a)
map方法返回一个迭代器:
1 print(list (map (sqr, a)))
其用法为:
将函数 aFun 应用到序列 aSeq 上的每一个元素上,返回一个迭代器,不管这个序列原来是什么类型。
事实上,根据函数参数的多少,map 可以接受多组序列,将其对应的元素作为参数传入函数:
1 2 3 4 5 6 7 def add (x, y ): return x + y a = (2 ,3 ,4 ) b = [10 ,5 ,3 ] print(list (map (add, a, b)))
一等函数 Python中的函数是一等函数
函数可以作为函数的参数
函数可以作为函数的返回值
函数可以赋值给变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def calculate (init_value, fn, *args, **kwargs ): total = init_value for arg in args: total = fn(total, arg) for kwarg in kwargs.values(): total = fn(total, kwarg) return total def add (a, b ): return a + b def multipication (a, b ): return a * b print(calculate(0 , add, 1 , 2 , 3 , 4 )) print(calculate(1 , multipication, 1 , 2 , 3 , 4 ))
Lambda函数 关键字lambda表示匿名函数,冒号前面的表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
1 2 print(calculate(0 , lambda a, b: a + b, 1 , 2 , 3 , 4 )) print(calculate(1 , lambda a, b: a * b, 1 , 2 , 3 , 4 ))
模块和包 模块 Python会将所有 .py 结尾的文件认定为Python代码文件,在 Python 中,一个 .py 文件就称之为一个模块(Module)。 考虑下面的脚本 ex1.py :
1 2 3 4 5 6 7 8 9 10 11 12 %%writefile ex1.py PI = 3.1416 def sum (lst ): tot = lst[0 ] for value in lst[1 :]: tot = tot + value return tot w = [0 , 1 , 2 , 3 ] print(sum (w), PI)
可以执行它:
这个脚本可以当作一个模块,可以使用import 关键词加载并执行它(这里要求ex1.py在当前工作目录):
1 <module 'ex1' from 'ex1.py'>
在导入时,Python 会执行一遍模块中的所有内容。
ex1.py 中所有的变量都被载入了当前环境中,不过要使用
的方法来查看或者修改这些变量:
1 2 3 ex1.PI = 3.141592653 print(ex1.PI) 3.141592653
还可以用
调用模块里面的函数:
1 2 print(ex1.sum ([2 , 3 , 4 ])) 9
为了提高效率,Python 只会载入模块一次,已经载入的模块再次载入时,Python并不会真正执行载入操作,哪怕模块的内容已经改变。
例如,这里重新导入 ex1 时,并不会执行 ex1.py 中的 print 语句:
需要重新导入模块时,可以使用reload强制重新载入它,例如:
1 <module 'ex1' from 'ex1.pyc'>
删除之前生成的文件:
1 2 import osos.remove('ex1.py' )
__name__ 属性有时候我们想将一个 .py 文件既当作脚本,又能当作模块用,这个时候可以使用 __name__ 这个属性。
只有当文件被当作脚本执行的时候,__name__的值才会是 __main__,所以我们可以:
ex2.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 PI = 3.1416 def sum (lst ): """ Sum the values in a list """ tot = 0 for value in lst: tot = tot + value return tot def add (x, y ): " Add two values." a = x + y return a def test (): w = [0 ,1 ,2 ,3 ] assert (sum (w) == 6 ) print 'test passed.' if __name__ == '__main__' : test() Writing ex2.py
运行文件:
1 2 %run ex2.py test passed.
当作模块导入, test() 不会执行:
但是可以使用其中的变量:
使用别名:
其他导入方法 可以从模块中导入变量:
使用 from 后,可以直接使用add , PI:
或者使用 * 导入所有变量:
1 2 from ex2 import *add(3 , 4.5 )
这种导入方法不是很提倡,因为如果你不确定导入的都有哪些,可能覆盖一些已有的函数。
删除文件:
1 2 import osos.remove('ex2.py' )
包 假设我们有这样的一个文件夹:
foo/
__init__.pybar.py (defines func)baz.py (defines zap)
这意味着 foo 是一个包,我们可以这样导入其中的内容:
1 2 from foo.bar import funcfrom foo.baz import zap
bar 和 baz 都是 foo 文件夹下的 .py 文件。
导入包要求:
文件夹 foo 在Python 的搜索路径中
__init__.py 表示 foo 是一个包,它可以是个空文件。
解决命名冲突 方式一:导入函数的时候,对函数进行别名
1 2 3 4 5 6 from foo.person import eat as person_eatfrom foo.animal import eat as animal_eatperson_eat() animal_eat()
方式二:使用完全限定名(qualified name)–>[包名.]模块名.函数名
1 2 3 4 5 6 import foo.personimport foo.animalfoo.person.eat() foo.animal.eat()
常用的标准库
re 正则表达式
copy 复制
math, cmath 数学
decimal, fraction
sqlite3 数据库
os, os.path 文件系统
gzip, bz2, zipfile, tarfile 压缩文件
csv, netrc 各种文件格式
xml
htmllib
ftplib, socket
cmd 命令行
pdb
profile, cProfile, timeit
collections, heapq, bisect 数据结构
mmap
threading, Queue 并行
multiprocessing
subprocess
pickle, cPickle
struct
PYTHONPATH设置 Python的搜索路径可以通过环境变量PYTHONPATH设置,环境变量的设置方法依操作系统的不同而不同,具体方法可以网上搜索。
面向对象 Python 就是一门面向对象的语言,
如果你学过 Java ,就知道 Java 的编程思想就是:万事万物皆对象。Python 也不例外,在解决实际问题的过程中,可以把构成问题事务分解成各个对象。
面向对象都有两个基本的概念,分别是类和对象。
用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
通过类定义的数据结构实例
面向对象的三大特性 面向对象的编程语言,也有三大特性,继承,多态和封装性。
即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。
例如:一个 Dog 类型的对象派生自 Animal 类,这是模拟”是一个(is-a)”关系(例图,Dog 是一个 Animal )。
它是指对不同类型的变量进行相同的操作,它会根据对象(或类)类型的不同而表现出不同的行为。
“封装”就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体(即类);封装的目的是增强安全性和简化编程,使用者不必了解具体的实现细节,而只是要通过外部接口,一特定的访问权限来使用类的成员。
定义类 在Python中可以使用class关键字定义类,类的命名采用驼峰命名法 ,然后在类中通过之前学习过的函数来定义方法,这样就可以将对象的动态特征描述出来,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Student (object def __init__ (self, name, age ): self.name = name self.age = age def eat (self ): print(f'{self.name} 正在吃饭.' ) def study (self ): print(f'{self.name} 正在学习.' ) def watch_movie (self ): if self.age < 18 : print('%s只能观看《熊出没》.' % self.name) else : print('%s正在观看岛国爱情大电影.' % self.name)
创建和使用对象 1 2 3 s = Student('张三' , 18 ) s.eat() s.study()
静态方法和类方法 Python 的类方法和静态方法很相似,它们都推荐使用类来调用(其实也可使用对象来调用)。
类方法和静态方法的区别在于,Python会自动绑定类方法的第一个参数,类方法的第一个参数(通常建议参数名为 cls)会自动绑定到类本身;但对于静态方法则不会自动绑定。
使用 @classmethod 修饰的方法就是类方法;使用 @staticmethod 修饰的方法就是静态方法。
1 2 3 4 5 6 7 8 9 class Bird : @classmethod def fly (cls ): print('类方法fly: ' , cls) @staticmethod def info (p ): print('静态方法info: ' , p)
调用类方法,Bird类会自动绑定到第一个参数
调用静态方法,不会自动绑定,因此程序必须手动绑定第一个参数
创建Bird对象
使用对象调用fly()类方法,其实依然还是使用类调用, 因此第一个参数依然被自动绑定到Bird类
使用对象调用info()静态方法,其实依然还是使用类调用,因此程序必须为第一个参数执行绑定
继承 首先我们来看下类的继承的基本语法:
1 2 3 4 5 6 class ClassName (BaseClassName ): <statement-1 > . . . <statement-N>
在定义类的时候,可以在括号里写继承的类,如果不用继承类的时候,也要写继承 object 类,因为在 Python 中 object 类是一切类的父类。
当然上面的是单继承,Python 也是支持多继承的,具体的语法如下:
1 2 3 4 5 6 class ClassName (Base1,Base2,Base3 ): <statement-1 > . . . <statement-N>
多继承有一点需要注意的:若是父类中有相同的方法名,而在子类使用时未指定,python 在圆括号中父类的顺序,从左至右搜索 , 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
继承的子类的好处:
会继承父类的属性和方法
可以自己定义,覆盖父类的属性和方法
定义父类
1 2 3 4 5 6 7 8 9 10 11 class Person : def __init__ (self, name, gender ): self.name = name self.gender = gender def eat (self ): print(f'{self.name} 正在吃饭' ) def play (self ): print(f'{self.name} 正在玩' )
继承父类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Student (Person ): def __init__ (self, name, gender, grade ): super ().__init__(name, gender) self.grade = grade def study (self ): print(f'{self.name} 正在学习' ) s = Student("张三" , True , 80 ) s.eat() s.play() s.study()
子类的类型判断 对于 class 的继承关系来说,有些时候我们需要判断 class 的类型,该怎么办呢?
可以使用 isinstance() 函数,
一个例子就能看懂 isinstance() 函数的用法了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class User1 (object pass class User2 (User1 ): pass class User3 (User2 ): pass if __name__ == '__main__' : user1 = User1() user2 = User2() user3 = User3() print(isinstance (user3, User2)) print(isinstance (user3, User1)) print(isinstance (user3, User3)) print(isinstance ('两点水' , str )) print(isinstance (347073565 , int )) print(isinstance (347073565 , str ))
输出的结果如下:
1 2 3 4 5 6 True True True True True False
文件和异常 在Python中实现文件的读写操作其实非常简单,通过Python内置的open函数,我们可以指定文件名、操作模式、编码信息等来获得操作文件的对象,接下来就可以对文件进行读写操作了。这里所说的操作模式是指要打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加),具体的如下表所示。
读写文本文件 读取文本文件时,需要在使用open函数时指定好带路径的文件名(可以使用相对路径或绝对路径)并将文件模式设置为'r'(如果不指定,默认值也是'r'),然后通过encoding参数指定编码(如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码),如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取失败。下面的例子演示了如何读取一个纯文本文件。
1 2 3 4 5 6 7 8 def main (): f = open ('未选择的路.txt' , 'r' , encoding='utf-8' ) print(f.read()) f.close() if __name__ == '__main__' : main()
请注意上面的代码,如果open函数指定的文件并不存在或者无法打开,那么将引发异常状况导致程序崩溃。为了让代码有一定的健壮性和容错性,我们可以使用Python的异常机制对可能在运行时发生状况的代码进行适当的处理,如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def main (): f = None try : f = open ('未选择的路.txt' , 'r' , encoding='utf-8' ) print(f.read()) except FileNotFoundError: print('无法打开指定的文件!' ) except LookupError: print('指定了未知的编码!' ) except UnicodeDecodeError: print('读取文件时解码错误!' ) finally : if f: f.close() if __name__ == '__main__' : main()
在Python中,我们可以将那些在运行时可能会出现状况的代码放在try代码块中,在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。例如在上面读取文件的过程中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定方式解码会引发UnicodeDecodeError,我们在try后面跟上了三个except分别处理这三种不同的异常状况。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常),因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源,代码如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def main (): try : with open ('未选择的路.txt' , 'r' , encoding='utf-8' ) as f: print(f.read()) except FileNotFoundError: print('无法打开指定的文件!' ) except LookupError: print('指定了未知的编码!' ) except UnicodeDecodeError: print('读取文件时解码错误!' ) if __name__ == '__main__' : main()
写文件 使用 w 模式时,如果文件不存在会被创建,如果文件已经存在, w 模式会覆盖之前写的所有内容:
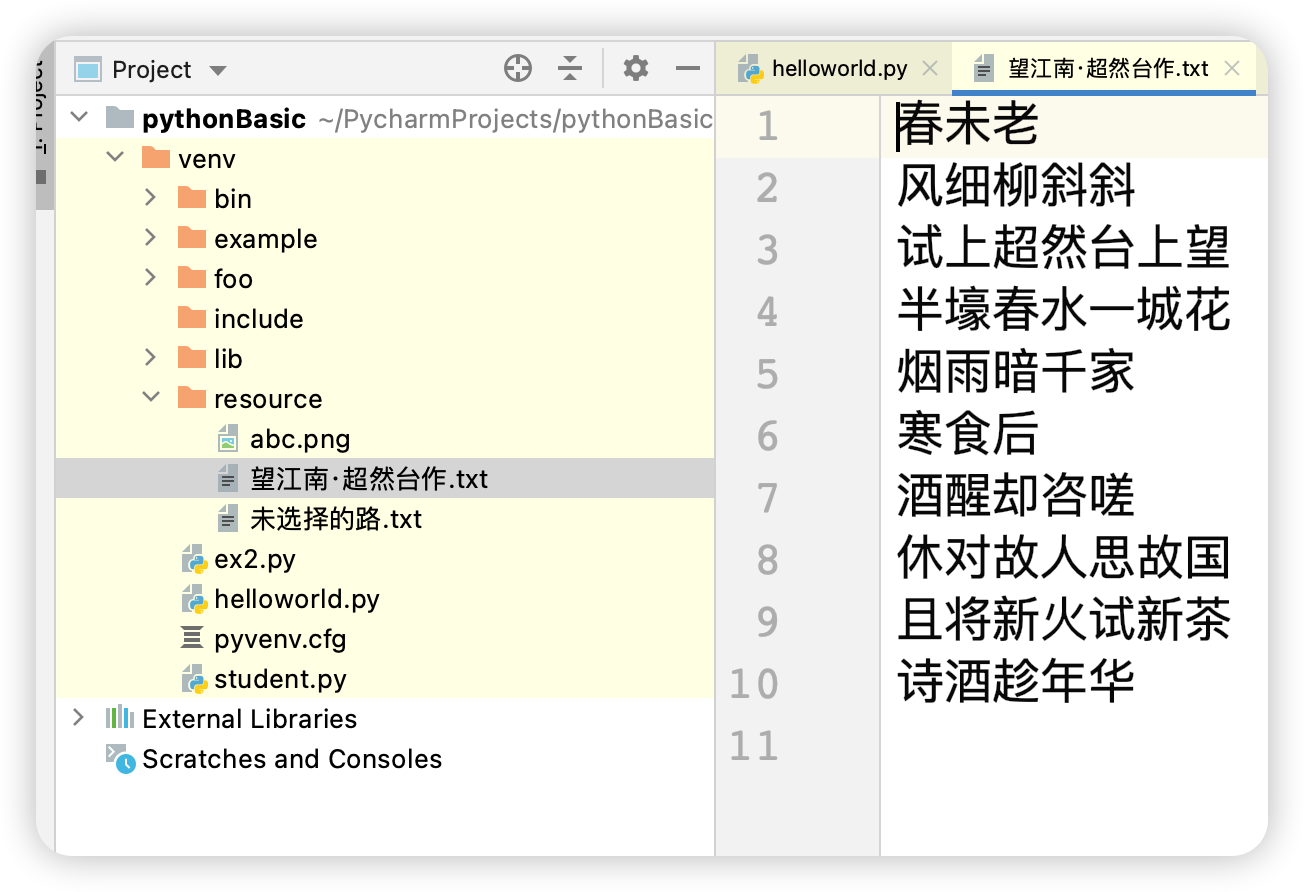
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def main (): file = open ('venv/resource/望江南·超然台作.txt' , mode='w' , encoding='utf-8' ) try : file.write('春未老\r\n' ) file.write('风细柳斜斜\r\n' ) file.write('试上超然台上望\r\n' ) file.write('半壕春水一城花\r\n' ) file.write('烟雨暗千家\r\n' ) file.write('寒食后\r\n' ) file.write('酒醒却咨嗟\r\n' ) file.write('休对故人思故国\r\n' ) file.write('且将新火试新茶\r\n' ) file.write('诗酒趁年华\r\n' ) finally : file.close() if __name__ == '__main__' : main()
除了写入模式,还有追加模式 a ,追加模式不会覆盖之前已经写入的内容,而是在之后继续写入:
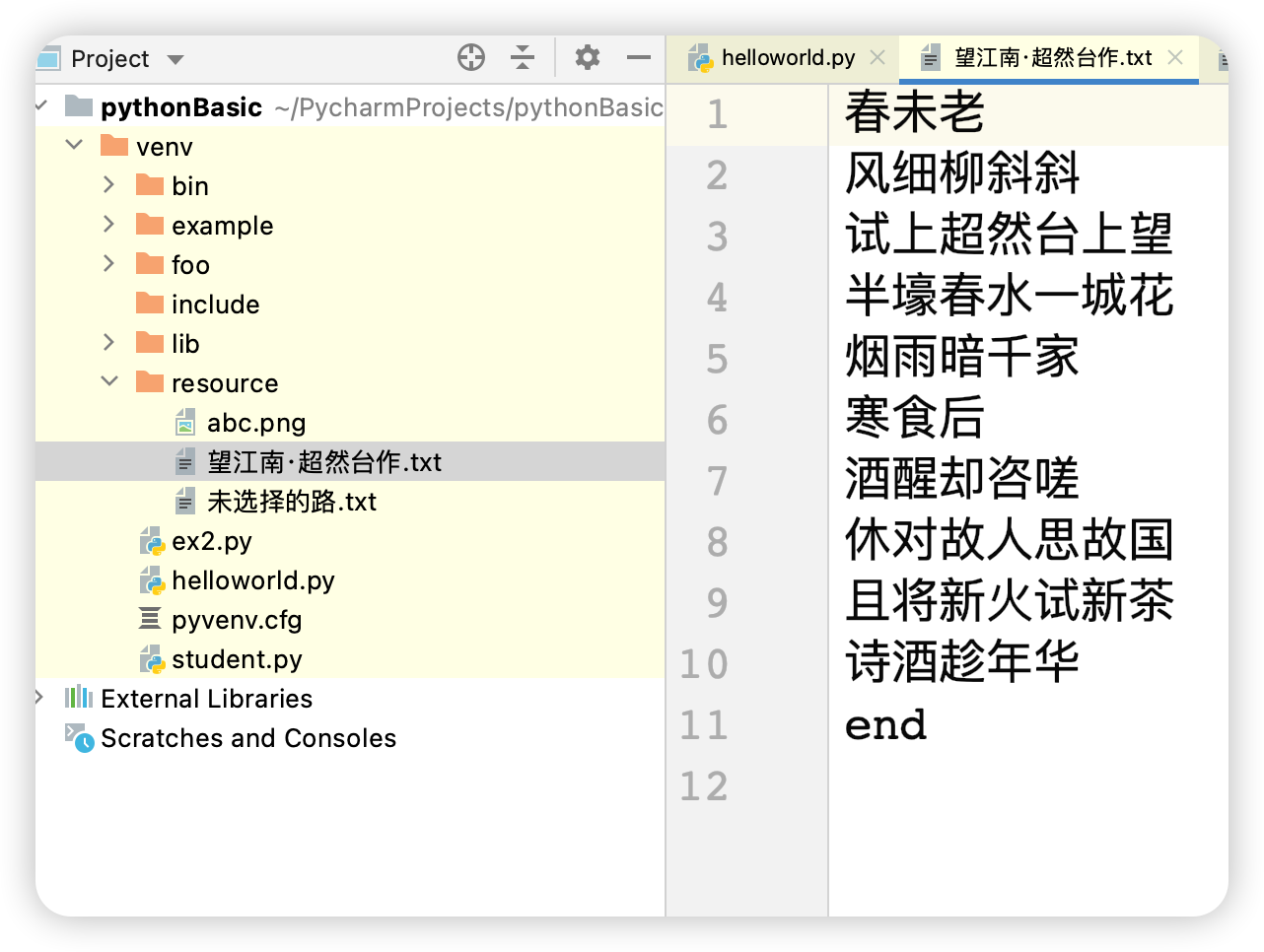
1 2 3 4 5 6 7 8 9 10 def main (): file = open ('venv/resource/望江南·超然台作.txt' , mode='a' , encoding='utf-8' ) try : file.write('end\r\n' ) finally : file.close() if __name__ == '__main__' : main()
二进制文件 读写二进制文件 知道了如何读写文本文件要读写二进制文件也就很简单了,下面的代码实现了复制图片文件的功能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def main (): try : with open ('guido.jpg' , 'rb' ) as fs1: data = fs1.read() print(type (data)) with open ('吉多.jpg' , 'wb' ) as fs2: fs2.write(data) except FileNotFoundError as e: print('指定的文件无法打开.' ) except IOError as e: print('读写文件时出现错误.' ) print('程序执行结束.' ) if __name__ == '__main__' : main()