Linux教程(一)
基础信息
其实整个指令下达的方式很简单,你只要记得几个重要的概念就可以了。举例来说,你可以这样下达指令的:
1 | [dmtsai@study ~]$ command [-options] parameter1 parameter2 |
上述指令详细说明如下:
一行指令中第一个输入的部分绝对是“指令(
command)”或“可执行文件案(例如批次 脚本,script)”command为指令的名称,例如变换工作目录的指令为cd等等;中刮号[]并不存在于实际的指令中,而加入选项设置时,通常选项前会带
-号,例如-h;有时候会使用选项的完整全名,则选项前带有
--符号,例如 –help;parameter1parameter2..为依附在选项后面的参数,或者是command的参数;指令,选项,参数等这几个咚咚中间以空格来区分,不论空几格shell都视为一格。所以空格是很重要的特殊字符!;
按下[
Enter]按键后,该指令就立即执行。[Enter]按键代表着一行指令的开始启动。指令太长的时候,可以使用反斜线(
\)来跳脱[Enter]符号,使指令连续到下一行。注意!反斜线后就立刻接特殊字符,才能跳脱!其他:
i. 在 Linux 系统中,英文大小写字母是不一样的。举例来说,cd与CD并不同。
注意到上面的说明当中,“第一个被输入的数据绝对是指令或者是可执行的文件”! 这个是很 重要的概念喔!还有,按下[Enter]键表示要开始执行此一命令的意思。
基础指令的操作
下面我们立刻来操作几个简单的指令看看!
- 显示日期与时间的指令: date
- 显示日历的指令: cal
- 简单好用的计算机: bc
重要的几个热键[Tab], [ctrl]-c, [ctrl]-d
[Tab]按键
在各种Unix-Like的 Shell当中, 这个[Tab]按键算是Linux的Bash shell最棒的功能之一了!他具有“命令补全”与“文件补齐”的功能喔!
[Ctrl]-c 按键
如果你在Linux下面输入了错误的指令或参数,有的时候这个指令或程序会在系统下面“跑不 停”这个时候怎么办?别担心, 如果你想让当前的程序“停掉”的话,可以输入:[Ctrl]与c按键 (先按着[Ctrl]不放,且再按下c按键,是组合按键), 那就是中断目前程序的按键啦!
[Ctrl]-d 按键
那么[Ctrl]-d是什么呢?就是[Ctrl]与d按键的组合啊!这个组合按键通常代表着: “键盘输入结 束(End Of File, EOF 或 End Of Input)”的意思! 另外,他也可以用来取代exit的输入呢!例 如你想要直接离开命令行,可以直接按下[Ctrl]-d就能够直接离开了(相当于输入exit啊!)。
[shift]+{[PageUP]|[Page Down]}按键
如果你在纯文本的画面中执行某些指令,这个指令的输出讯息相当长啊!所以导致前面的部 份已经不在目前的屏幕画面中, 所以你想要回头去瞧一瞧输出的讯息,那怎办?其实,你可 以使用 [Shift]+[Page Up] 来往前翻页,也能够使用 [Shift]+[Page Down] 来往后翻页! 这两个 组合键也是可以稍微记忆一下,在你要稍微往前翻画面时,相当有帮助!
Linux 的文件权限与目录配置
Linux一般将文件可存取的身份分为三个类 别,分别是 owner/group/others,且三种身份各有 read/write/execute 等权限。
Linux文件属性
嗯!既然要让你了解Linux的文件属性,那么有个重要的也是常用的指令就必须要先跟你说 啰!那一个?就是“ ls ”这一个察看文件的指令啰!在你以dmtsai登陆系统,然后使用 su - 切 换身份成为root后, 下达“ ls -al ”看看
1 | [dmtsai@study ~]$ su - # 先来切换一下身份看看 |
文件属性的示意图
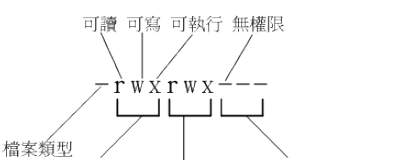
第一个字符代表这个文件是“目录、文件或链接文件等等”:
各个文件类型及其字符表示为:
| 表示字符 | 文件类型 |
|---|---|
d |
目录 |
- |
文件 |
l |
符号链接等 |
b |
可供储存的接口设备 |
c |
串行端口设备,如键盘、鼠标等 |
接下来的字符中,以三个为一组,且均为 rwx 的三个参数的组合。其中, r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)。 要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号 - 而已。
- 第一组为“文件拥有者可具备的权限”,以“initial-setup-ks.cfg”那个文件为例, 该文件 的拥有者可以读写,但不可执行;
- 第二组为“加入此群组之帐号的权限”;
- 第三组为“非本人且没有加入本群组之其他帐号的权限”。
每个文件的属性由左边第一部分的 10 个字符来确定(如下图)。

从左至右用 0-9 这些数字来表示。
第 0 位确定文件类型,第 1-3 位确定属主(该文件的所有者)拥有该文件的权限。
第4-6位确定属组(所有者的同组用户)拥有该文件的权限,第7-9位确定其他用户拥有该文件的权限。
其中,第 1、4、7 位表示读权限,如果用 r 字符表示,则有读权限,如果用 - 字符表示,则没有读权限;
第 2、5、8 位表示写权限,如果用 w 字符表示,则有写权限,如果用 - 字符表示没有写权限;第 3、6、9 位表示可执行权限,如果用 x 字符表示,则有执行权限,如果用 - 字符表示,则没有执行权限。
第五栏为这个文件的容量大小,默认单位为Bytes;
第六栏为这个文件的创建日期或者是最近的修改日期:
例题:如果我的目录为下面的样式,请问testgroup这个群组的成员与其他人 (others)是否可以进入本目录?
1 | drwxr-xr-- 1 test1 testgroup 5238 Jun 19 10:25 groups/ |
答:
- 文件拥有者test1[rwx]可以在本目录中进行任何工作;
- 而testgroup这个群组[r-x]的帐号,例如test2, test3亦可以进入本目录进行工作,但是不能 在本目录下进行写入的动作;
- 至于other的权限中[r–]虽然有r ,但是由于没有x的权限,因此others的使用者,并不能进 入此目录!
如何改变文件属性与权限
我们先介绍几个常用于群组、拥有者、各种身份的 权限之修改的指令,如下所示:
chgrp:改变文件所属群组chown:改变文件拥有者chmod:改变文件的权限, SUID, SGID, SBIT等等的特性
改变所属群组, chgrp
改变一个文件的群组真是很简单的,直接以chgrp来改变即可,咦!这个指令就是change group的缩写嘛!这样就很好记了吧! ^_^。不过,请记得,要被改变的群组名称必须要 在/etc/group文件内存在才行,否则就会显示错误!
假设你已经是root的身份了,那么在你的主文件夹内有一个名为 initial-setup-ks.cfg 的文件, 如何将该文件的群组改变一下呢?假设你已经知道在/etc/group里面已经存在一个名为users的 群组, 但是testing这个群组名字就不存在/etc/group当中了,此时改变群组成为users与 testing分别会有什么现象发生呢?
1 | [root@study ~]# chgrp [-R] dirname/filename ... |
发现了吗?文件的群组被改成users了,但是要改成testing的时候, 就会发生错误~注意喔!
改变文件拥有者, chown
如何改变一个文件的拥有者呢?很简单呀!既然改变群组是change group,那么改变拥有者 就是change owner啰!BINGO!那就是chown这个指令的用途,要注意的是, 使用者必须是已经存在系统中的帐号,也就是在/etc/passwd 这个文件中有纪录的使用者名称才能改变。
chown的用途还蛮多的,他还可以顺便直接修改群组的名称呢!此外,如果要连目录下的所有次目录或文件同时更改文件拥有者的话,直接加上 -R 的选项即可!我们来看看语法与范例:
1 | [root@study ~]# chown [-R] 帐号名称 文件或目录 |
改变文件权限, chmod
数字类型改变文件权限
我们可以用数字来代表各个权限,各个权限对应的数字为:
1 | r:4 |
每种身份各自的三个权限分数是需要累加的,例如当权限为 rwxrwx--- 时,对应的分数为:
1 | user = rwx = 4+2+1 = 7 |
得到的文件权限数字也就为 770, 修改权限时就可以使用这个数字完成:
1 | $ chmod [-R] 770 文件或目录 |
在实际的系统运行中 最常发生的一个问题就是,常常我们以vim编辑一个shell的文字批处理文件后,他的权限 通常是 -rw-rw-r– 也就是664, 如果要将该文件变成可可执行文件,并且不要让其他人修 改此一文件的话, 那么就需要-rwxr-xr-x这样的权限,此时就得要下达:“ chmod 755 test.sh ”的指令啰!
另外,如果有些文件你不希望被其他人看到,那么应该将文件的权限设置为例如:“-rwxr- —-”,那就下达“ chmod 740 filename ”吧!
符号类型改变文件权限
还有一个改变权限的方法呦!从之前的介绍中我们可以发现,基本上就九个权限分别是 (1)user (2)group (3)others三种身份啦!那么我们就可以借由u, g, o来代表三种 身份的权限!此外, a 则代表 all 亦即全部的身份!那么读写的权限就可以写成r, w, x
啰!也就是可以使用下面的方式来看:
1 | | chmod | u g o a | +(加入) -(除去) =(设置) | r w x | 文件或目录 | |
符号类型改变文件权限需要遵循一定的语法规则,分别需要了解的有 身份表示符, 操作表示符 和 权限表示符.
身份表示符:
| 表示符 | 代表的身份 |
|---|---|
u |
文件的拥有者 |
g |
文件的拥有者所在用户组 |
o |
其他人 |
a |
所有用户 |
操作表示符:
| 表示符 | 代表的操作 |
|---|---|
+ |
添加权限 |
- |
去除权限 |
= |
设定权限 |
权限表示符 就是 r, w 和 x.
来实作一下吧!假如我们要“设置”一个文件的权限成为“-rwxr-xr-x”时,基本上就是:
- user (u):具有可读、可写、可执行的权限;
- group 与 others (g/o):具有可读与执行的权限。 所以就是
1 | [root@study ~]# chmod u=rwx,go=rx .bashrc |
那么假如是“ -rwxr-xr– ”这样的权限呢?可以使用“ chmod u=rwx,g=rx,o=r filename ”来设 置。此外,如果我不知道原先的文件属性,而我只想要增加.bashrc这个文件的每个人均可写入的权限, 那么我就可以使用:
1 | [root@study ~]# ls -al .bashrc |
比如说下面的这条指令让拥有者具有所有权限,而为用户组和其他人添加执行权限:
1 | chmod u=rwx,go+x .vimrc |
需要注意的是: u=rwx,go+x 之间没有空格。
目录与文件之权限意义
权限对文件的重要性
文件是实际含有数据的地方,包括一般文本文件、数据库内容档、二进制可可执行文件 (binary program)等等。 因此,权限对于文件来说,他的意义是这样的:
- r (read):可读取此一文件的实际内容,如读取文本文件的文字内容等;
- w (write):可以编辑、新增或者是修改该文件的内容(但不含删除该文件);
- x (eXecute):该文件具有可以被系统执行的权限。
那个可读(r)代表读取文件内容是还好了解,那么可执行(x)呢?这里你就必须要小心啦! 因为在Windows下面一个文件是否具有执行的能力是借由“ 扩展名 ”来判断的, 例如:.exe, .bat, .com 等等,但是在Linux下面,我们的文件是否能被执行,则是借由是否具有“x”这个权 限来决定的!跟文件名是没有绝对的关系的!
至于最后一个w这个权限呢?当你对一个文件具有w权限时,你可以具有写入/编辑/新增/修改 文件的内容的权限, 但并不具备有删除该文件本身的权限!对于文件的rwx来说, 主要都是 针对“文件的内容”而言,与文件文件名的存在与否没有关系喔!因为文件记录的是实际的数据嘛!
权限对目录的重要性
如果是针对目录时,那个 r, w, x 对目录是什么意 义呢?
r (read contents in directory):
表示具有读取目录结构清单的权限,所以当你具有读取(r)一个目录的权限时,表示你 可以查询该目录下的文件名数据。 所以你就可以利用 ls 这个指令将该目录的内容列表显 示出来!
w (modify contents of directory):
这个可写入的权限对目录来说,是很了不起的! 因为他表示你具有异动该目录结构清单 的权限,也就是下面这些权限:- 创建新的文件与目录;
- 删除已经存在的文件与目录(不论该文件的权限为何!) 将已存在的文件或目录进行更名;
- 搬移该目录内的文件、目录位置。 总之,目录的w权限就与该目录下面的文件名异 动有关就对了啦!
x (access directory):
咦!目录的执行权限有啥用途啊?目录只是记录文件名而已,总不能拿来执行吧?没 错!目录不可以被执行,目录的x代表的是使用者能否进入该目录成为工作目录的用途! 所谓的工作目录(work directory)就是你目前所在的目录啦!举例来说,当你登陆Linux
同一个权限对于 文件 和 目录 来说,含义是不一样的,这里来了解一下。
| 权限 | 文件 | 目录 |
|---|---|---|
r |
可以读取文件内容 | 可以读取目录结构列表 |
w |
可以编辑修改文件内容 | 可以改动目录结构列表 |
x |
可以被系统执行 | 用户可以进入目录 (cd) |
这里需要注意的一个权限是: 可以改动目录结构列表, 这意味着可以:
- 建立新的文件与目录
- 删除已经存在的文件与目录
- 将已存在的文件或目录进行更名
- 搬移该目录内的文件、目录位置
所以 w 这个权限还是慎重使用好了。
Linux目录配置
由于 linux distribution 太多,所以有了 FHS(Filesystem Hierarchy Standard)标准。
该标准主要目的是:让使用者可以了解到已安装软件通常放置于哪个目录下, FHS 的重点在于每个特定的目录下应该要放上面样子的数据。
FHS 是根据过去的经验一直在持续的改版,依据文件系统使用的频繁与是否允许使用者随意更动, 而将目录定义成为四种交互作用的形态。
| - | 可分享的(shareable) | 不可分享的(unshareable) |
|---|---|---|
| 不变得(static) | /usr(软件放置处) |
/etc (配置文件) |
| - | /opt(第三方软件) |
/boot (开机与核心) |
| 可变动的(variable) | /var/mail (使用者邮箱) |
/var/run (程序相关) |
| - | /var/spool/news (新闻组) |
/var/lock (程序相关) |
上表中是一些代表性的目录,而下面放置的数据后面会讲到,这里主要了解什么是那四个类型?
- 可分享的:可以分享给其他系统挂载使用的目录,所以包括可执行文件与使用者的邮件 等数据, 是能够分享给网络上其他主机挂载用的目录;
- 不可分享的:自己机器上面运行的设备文件或者是与程序有关的socket文件等, 由于仅 与自身机器有关,所以当然就不适合分享给其他主机了。
- 不变的:有些数据是不会经常变动的,跟随着distribution而不变动。 例如函数库、文件说明文档、系统管理员所管理的主机服务配置文件等等;
- 可变动的:经常改变的数据,例如登录文件、一般用户可自行收受的新闻群组等。
事实上 FHS 针对目录树架构仅定义出三层目录下应该放置什么数据:
/: root 根目录,与开机系统有关/usr:unix software resource 与软件安装/执行有关/var:variable 与系统运作过程有关
根目录 / 的意义与内容
根目录是整个系统最重要的一个目录,因为不但所有的目录都是由根目录衍生出来的,同时 根目录也与开机/还原/系统修复等动作有关。 由于系统开机时需要特定的开机软件、核心文 件、开机所需程序、函数库等等文件数据,若系统出现错误时,根目录也必须要包含有能够 修复文件系统的程序才行。 因为根目录是这么的重要,所以在FHS的要求方面,他希望根目 录不要放在非常大的分区内, 因为越大的分区你会放入越多的数据,如此一来根目录所在分 区就可能会有较多发生错误的机会。
因此 FHS 标准建议是:根目录所在分区槽应该越小越好,且应用程序所安装的软件最好不要与根目录放在同一个分区槽内, 报纸根目录越小越好。如此不但效能较佳,根目录所在的文件系统也较不容易发生问题
因此 FHS 定义出根目录下应该要有以下目录存在,即使没有实体目录,也希望至少有连接文件存在。
第一部分:FHS 要求必须要存在的目录
/bin系统有很多放置执行文件的目录,单 /bin 比较特殊。 因为放置的是在单人维护模式下还能够被操作的指令。
/bin 下的指令可以被 root 与一般账户所使用,主要有 cat、chmod、chown、date、mv、mkdir、cp、bash 等常用命令
/boot主要放置开机会使用到的文件,包括 linux 核心文件以及开机选单与开机锁需配置文件等。
Linux kernel 常用额文件名为 vmlinuz ,如果使用 grub2 开机管理程序,则还会存在 /boot/grub2 这个目录
/dev任何装置与接口设备都是以文件形态存在这个目录当中。只要透过存取这个目录下的某个文件, 就等于存取某个装置,比较重要的文件有 /dev/null、/dev/zero、/dev/tty、/dev/loop、/dev/sd 等
/etc系统主要的配置文件几乎都放在这个目录中,例如人员的账户密码文件、各种服务的启动文件等, 一般来说,这个目录下的各文件属性是可以让一般使用者查阅的,但是只有 root 有权利修改。 FHS 建议不要放置可执行文件 (binary) 在这个目录中。
比较重要的有 /etc/modprobe.d、/etc/passwd、/etc/fstab、/etc/issue 等。
另外 FHS 还规范几个重要的目录页最好咋 /etc 目录下:
/etc/opt/:必要,放置第三方协力软件 /opt 的相关配置文件/etc/xqq/:建议,与 x window 有关的各种配置文件,尤其是 xorg.conf 这 x server 的配置文件/etc/sgml:建议,与 SGML 格式有管的各项配置文件/etc/xm:建议,与 XML 格式有关的各项配置文件
/lib系统的函式库非常的多,而 lib 下放的是在 开机时会用到的函数库,以及在 /bin 和 /sbin 下的指令会呼叫的函数库。
另外 FHS 还要求 /lib/modules 目录存在,主要放可抽换式的核心先关模块(驱动程序)
/media放的是可移除的设备,例如 软盘、光盘、 DVD 等都暂时挂载于此。
常见的有 /media/floppy、/media/cdrom 等
/mnt如果暂时挂载某些额外的设备,一般建议可以放到这个目录中,在很早的时候该目录用途与 /mnt 相同, 只是有了 /media 后,这个目录就用来暂时挂载用了
opt放第三方协力软件的目录。比如 KDE 这个桌面管理系统是一个独立的计划,不过他可以安装到 linux 系统中, 因此 KDE 就建议放置到该目录下了。
如果你想要自行安装额外的软件(非原本 distribution 提供的),那么也建议放这里, 不过,以前的 linux 系统中,还是习惯放在 /usr/local 目录下
run早期的 FHS 规定系统开机后所产生的各项信息应该放置到 /var/run 目录下, 新版的则规范到 /run 目录下了,由于 /run 可以用来内存仿真,因此效能上会好很多
/sbinLinux 有非常多的指令是用来设置系统环境的,这些指令只有 root才能够利用来设置系统, 其他用户只能用来「查询」。放在 /sbin 下的为开机过程中所需要的,包括了开机、修复、还原系统所需要的指令。
至于某些服务器软件程序,一般放置到 /usr/sbin 中。 至于本机自行安装的软件产生的系统执行文件(system binary)则放到 /usr/local/sbin 中了。
常见的指令包括:fdisk、fsck、ifconfig、mkfs 等
/srvsrc 可以视为 「service」的缩写,是一些网络服务启动之后,这些服务所需要取用的数据目录。 常见的服务如 www、ftp 等。例如:www 服务器需要的网页资源就可以放在 /srv/www 里面。
不过,系统的服务数据如果尚未要提供给英特网上任何人浏览的话,预设还是建议放在 /var/lib 下
/tmp一般用户或则是正在执行的程序暂时放文件的地方。该目录是任何人都可以存取的,所以需要定期清理一下。 因此 FHS 甚至建议在开机时,应该删除该目录下的文件
/usr:属于第二层 FHS 规范,后续介绍/var:属于第二层 FHS 规范,主要放置变动性的数据,后续介绍
第二部分:FHS 建议可以存在的目录
/home系统默认的用户目录。在你新增一个一般使用者账户时,默认的用户家目录都会规范到这里来。 比较重要的是,家的木有两种代号:
- ~:代表目前这个用户的家目录
- ~mrcode:则代表 mrcode 的家目录
/lib<qual>用来存放于 /lib 不同的格式的二进制函数库,例如支持 64 位的 /lib64 函数库/root系统管理员 root 的家目录。之所以放这里,是因为如果进入单人维护模式而仅挂载根目录时,该目录就能够拥有 root 的家目录, 所以会希望 root 的家目录与根目录放同一个分区槽中
事实上 FHS 针对目录所定义的标准就仅有上面的规范,不过还有其他的目录一需要了解下, 也是 linux 当中几个非常重要的目录:
/lost+found这个目录使用标准的 ext2/3/4 文件系统格式才会产生的一个目录,目的是当文件系统发生错误时, 将一些遗失的片段放到这个目录下。
不过如果使用的是 xfs 文件系统的话,就不会存在这个目录了
/proc这个目录本身是一个「虚拟文件系统(virtual filesystem),放的数据都在内存当中, 例如系统核心、进程信息(process)、周边装置的状态以及网络状态等。
因为这个目录下的数据都是内存当中,使用本身不占任何硬盘空间。比较重要的文件:
1
2
3
4
5
6
7/proc
cpuinfo
dma
interrupts
ioports
net/*
/sys与 proc 非常类似,也是一个虚拟的文件系统,主要也是记录核心与系统硬件信息较相关的信息。 包括目前已加载的核心模块与核心侦测到的硬件装置信息等。同样不占用硬盘容量
/usr 的意义与内容
根据 FHS 的基本定义, /usr 里面放置的数据属于可以分享的与不可变动的, 如果你知道如何透过网络进行分区槽的挂载(例如在服务器篇会谈到的 NFS 服务器), 那么 /usr 确实可以分享给局域网内的其他主机来使用
/usr 不是 user 的缩写,而是 Unix Software Resource 的缩写(Unix 操作系统软件资源), FHS 建议所有软件开发者,应该将他们的数据合理的分辨放置到这个目录下的次目录,而不要自行建立该软件自己独立的目录。
因为所有系统默认的软件(distribution 发布者提供的软件)都会放置到 /usr 下, 因此该目录类似 windows 「c:/windows 和 c:/Program files」这两个目录的综合体。
一般来说 /usr 的此目录建议有以下:
第一部分:FHS 要求必须要存在的目录
/usr/bin/所有一般用户能够使用的指令都放在这里。 CentOS7 新版已经将全部的用户指令放在这里, 而使用连接文件的方式将 /bin 连接到这里。也就是说 /usr/bin 与 /bin 是一样的了。 而且 FHS 要求在此目录下不应该有子目录
/usr/lib/基本上 与 /lib 功能相同,使用 /lib 就是连接到此目录的
/usr/local/系统管理员在本机自行安装自己下载的软件(非 distribution 默认提供),建议安装到此目录。 比如,distribution 提供的软件较旧,想安装新的但是又不想移除旧版本的,就可以将新版安装到这里。
该目录下也是具有 bin、etc、include、lib 的次目录
/usr/sbin非系统正常运作所需要的系统指令。最长久的就是某些网络服务器软件的指令(daemon)。 不过功能基本与 /sbin 差不多,因此 /sbin 也是连接到此目录的
/usr/share/主要放置只读架构的数据文件和共享文件。在该目录下的数据几乎是不分硬件架构均可读取的数据, 因为几乎上都是文本文件。常见的还有以下次目录
/usr/share/man:联机帮助文件/usr/share/doc:软件杂项的文件说明/usr/share/zoneinfo与时区有关的时区文件
第二部分:FHS 建议可以存在的目录
/usr/games/:与游戏比较相关的数据/usr/include:c/c++ 等程序语言的档头(header)与包含档(include)放置处,当我们以 tarball 方式 (tar.gz 的方式安装软件)安装某些数据时,会使用到里头的许多包含档
/usr/libexe某些不被一般使用者惯用的执行档或脚本,例如大部分的 x 窗口下的操作指令
/usr/lib<qual>与
/lib<qual>功能相同,连接过来的/usr/src一般源码建议放这里,src 有 source 的意思。 至于核心源码则建议放到 /usr/src/linux 目录下
/var 的意义与内容
如果 /usr 是安装时会占用较大硬盘容量的目录,那么 /var 则是在运行后才会渐渐占用容量的。 主要放置的是针对常态性变动的文件,包括 cache、登录文件(log file)以及某些软件所产生的文件, 包括程序文件(lock file,run file),或则例如 mysql 数据库的文件等, 常见的目录有
第一部分:FHS 要求必须要存在的目录
/var/cache:应用程序运行中使用的缓存文件/var/lib:程序本身执行过程中,需要用到的数据文件存放处。在此目录下各自的软件应该要有各自的目录, 比如:mysql 数据库放到 /var/lib/mysql 而 rpm 的数据库则放到 /var/lib/rpm
/var/lock某些装置或是文件资源一次只能被一个程序使用,所以这里存放的是加锁的标识, 目前此目录已经挪到 /run/lock 中了
/var/mail:个人电子邮件信箱目录,不过也被放置到了 /var/spool/mail 中了,通常两个目录互为连接文件/var/run某些程序或则是服务启动后,会将他们的 PID 放置在这个目录下,与 /run 相同,也连接到 /run 下了。 至于 PID 后续讲解
/var/spool通常放置一些对了数据,这些数据被使用后通常都会被删除。 比如:系统受到新信会放到 /var/spool/mail 中,但使用者手下该信件后该封信原则上就会被删除。 信件如果展示寄不出去,则会放到 /var/spool/mqueue 中。等待被送出后会被删除。
如果是工作排程数据(crontab)就会被放到 /var/spool/cron 目录中
建议在读完整个基础篇之后,可以挑战 FHS 官网英文文件,会让你对于 linux 操作系统的目录有更深入的了解
针对 FHS 各家 distribution 的异同,与 CentOS 7 的变化
由于 FHS 仅是定义出上层 / 与次层 /var 的目录内容应该放置的文件或目录, 其他的就由开发者自行配置了。
如: CentOS 网络设置数据放在 /etc/sysconfig/network-scripts 下。 但是 SuSE 的则放在 /etc/sysconfig/netwok 目录下,所以名称不一致,但是记住大致的 FHS 标准,差异性其实不大
centOS7 相对于老版做了改进,将许多原本应该要在 / 目录中的数据全部挪到 /usr 里面去,然后进行连接设置。 包括以下这些:
- /bin -> /usr/bin
- /sbin -> /usr/sbin
- /lib -> /usr/lib
- /lib64 -> /usr/lib64
- /var/lock -> /run/lock
- /var/run -> /run
目录树(directory tree)
在Linux下面,所有的文件与目录都是由根目录开始的!那是所有目录与文件的源头~ 然后再一个一个的分支下来,有点像是树枝状啊~因此,我们也称这种目录配置方式为:“目录树(directory tree)” 。主要特性如下:
- 目录树的起始点为根目录
/ - 每个目录可以使用本地端的分区(partition)文件系统,也可以使用网络上的文件系统。举例来说,就是可以利用 Network File System(NFS)服务器挂载某些特定的目录
- 每一个文件在此目录树种的文件名(包含完整路径)都是独一无二的
可以使用命令 ls -l / 来查看根目录下又哪些文件与数据。 下图将较为重要的文件数据列出来,那么目录树架构如下图这样。
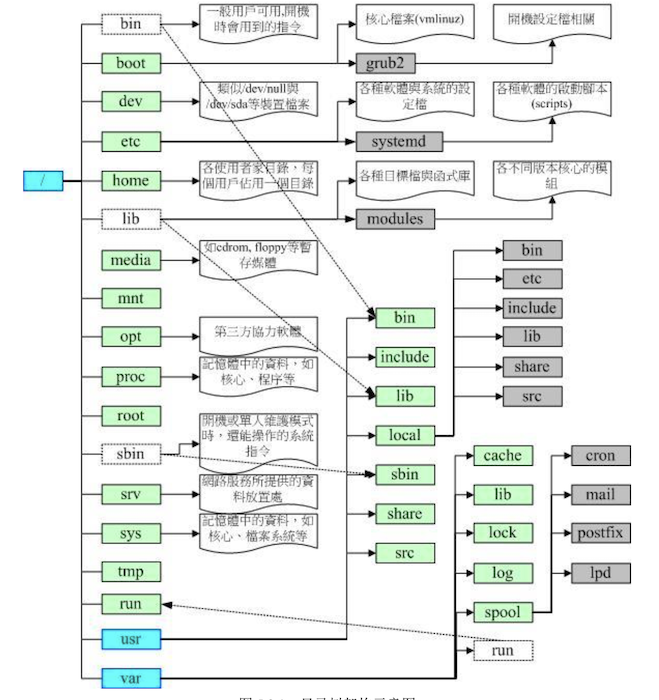
学习了这么多,那么现在回去看看安装前 主机规划与磁盘划分,对于当初如何要这样划分, 现在你就明白了。
根据 FHS 的定义,最好能将 /var 独立出来,因为当 /var 死掉时,你的根目录还会活着,还可以进入救援模式。
绝对路径与相对路径
文件名与路径的写法分为:
- 绝对路径:由根目录开始写起的文件或目录,例如 /home/mrcode/.bashrc
- 相对路径:开头不是
/则是相对路径,例如: ./home/mrcode
对于 . 的概念:
.:代表当前目录,也可以使用 ./ 来表示..:代表上一层目录,也可以使用 ../ 来表示
CentOS 的观察,linux 版本查询
除了第一章中谈到的 Linux distribution 的差异性,除了 FHS 之外,还有个 Linux Standard Base(LSB) 的标准是可以依循的。
可以简单的使用 ls 来查看 FHS 规范的目录是否正确的存在你的 Linux 系统中, 那么 支持 LSB 标准的 distribution 在 https://www.linuxbase.org/lsb-cert/productdir.php?by_lsb 中被列出
如果想要知道确切的核心与 LSB 所需求的几种重要的标准的话,就需要例如 uname 与 lsb_release 等指令来查询了。
lsb_release 软件不是默认安装软件了,因此需要先安装。
但是这里,新安装的机器居然不能连接外网,可以与宿主机通网了。那么这里无法安装,只能先记录命令
1 | # 检查 linux 核心与操作系统的位版本 |
Linux 文件与目录管理
本章进一步操作与管理文件及目录,包括在不同的目录间变换、建立、删除目录, 建立与删除文件、查找文件、查阅问价内容等,都会在这个章节进行简单介绍。
相对路径与绝对路径
- 绝对路径:由根目录开头,如 /home/mrcode
- 相对路径:不是由根目录开头的,如 ./mrcode
目录的相关操作
以下的特殊目录需要着重了掌握
.:代表此层目录..:上一层目录-:前一个工作目录~:目前用户身份坐在的家目录~account:表示 account 这个用户的家目录(account 是个账户名称)
需要特别注意的是,在所有目录下都会看到两个目录 . 与 ..,当前目录和上一层目录。
那么 linux 中,根目录有没有上层目录存在?
1 | [mrcode@study ~]$ ls -al / |
那么下面讲解下几个常见的处理目录的指令:
cd:变换目录pwd:显示当前目录mkdir:建立一个新的目录rmdir:删除一个空的目录
cd(change directory)变换目录
1 | [dmtsai@study ~]$ su - # 先切换身份成为 root 看看! |
cd是Change Directory的缩写,这是用来变换工作目录的指令。注意,目录名称与cd指令之间 存在一个空格。 一登陆Linux系统后,每个帐号都会在自己帐号的主文件夹中。那回到上一层 目录可以用“ cd .. ”。 利用相对路径的写法必须要确认你目前的路径才能正确的去到想要去的目录。例如上表当中最后一个例子, 你必须要确认你是在/var/spool/mail当中,并且知道 在/var/spool当中有个mqueue的目录才行啊~ 这样才能使用cd ../postfix 去到正确的目录说, 否则就要直接输入cd /var/spool/postfix 啰~
pwd(print Working Directory) 显示当前所在目录
1 | [mrcode@study mail]$ pwd |
pwd是Print Working Directory的缩写,也就是显示目前所在目录的指令。
mkdir 建立新目录
语法如下
1 | mkdir [-mp] 目录名称 |
练习
1 | # 进入临时目录 |
rmdir 删除空的目录
语法如下
1 | rmdir [-p] 目录名称 |
练习
1 | [mrcode@study tmp]$ ls -ld test* |
但是如果想把该目录下所有的东西都删除呢?你可以使用指令 rm -r test1 就能全部删掉了, 相对来说,rmdir 没有这么危险
关于执行文件路径的变量:$PATH
前面讲解 FHS 后,我们知道 ls 指令完整文件名为 /bin/ls(这是绝对路径), 那么为什么我们可以在任何地方执行 /bin/ls 这个指令呢?这是因为换了变量 PATH 的能力
当我们执行一个指令的时候,系统会按照 PATH 的设定去每个 PATH 定义的目录下搜索对应的可执行文件 (比如 ls),如果在 PATH 定义的目录中含有多个文件名为 ls 的可执行文件,那么先搜索到的被执行
1 | # 打印变量的信息,使用 echo ,「$」表示接一个变量 |
PATH(一定是大写)这个变量的内容是由一堆目录所组成的,每个目录中间用冒号(:)来隔 开, 每个目录是有“顺序”之分的。
1 | # 先把 ls 移动到 /bin 目录之外去,再运行 ls 看能不能运行? |
为什么不建议把 . 当前目录添加到 PATH 路径中?这其实是为了安全起见,不建议添加到 PATH 中, 比如在 /tmp 目录下,因为是大家都可以写的,有人搞破坏,写了一个 ls 的指令,但是里面写的是删除文件的, 这样就会先收到这个恶意的命令
由上面的示例,我们可以知道几件事情:
- 不同身份使用者预设的 PATH 不同,默认能够随意执行的指令也不同(如 root 与 mrcode)
- PATH 是可以修改的
- 使用绝对路径或相对路径直接指定某个指令文件名来执行,会比搜寻 PATH 来的正确
- 指令应该要放置到正确的目录下,执行才比较方便
- 当前目录「.」建议不要放到 PATH 中
文件与目录管理
文件与目录的检视: ls
1 | ls [-aAdfFhilnrRSt] 文件名或目录名称 |
选项与参数:
a:全部的文件,连同隐藏文件(开头为 .)一起列出来(常用)
A:全部的文件,连同隐藏文件(不包括 . 和 .. 这两个目录)
d:仅列出目录本身,而不是列出目录内的文件数据(常用)
f:直接列出结果,而不进行排序(ls 默认以文档名排序)
F:根据文件、目录等信息,给予附加数据结构
如:
*代表可执行文件,/代表目录=代表 socket 文件|代表 FIFO 文件
h:将文件容量以人类较易读的方式(例如 GB、KB)列出来
i:列出 inode 号码,inode 的意义后续讲解
l:长数据串输出,包含文件的属性与权限等数据(常用)
n:列出 UID 与 GID 而非使用者与群组的名称(UID 与 GID 会在账户管理中讲解)
r:将排序结果反向输出,例如原本文件名由小到大,反向则由大到小
R:连同子目录内容一起列出来,等于该目录下的所有文件都会显示出来
S:按文件容量大小排序
t:按时间排序
color 颜色配置
- never:不要依据文件特性给予颜色显示
- always:显示颜色
- auto:让系统自行依据设置来判断是否给予颜色
full-time:以完整时间模式)包含年月日时分输出
time={atime,ctime}:输出 access 时间或改变权限属性时间(ctime),而非内容变更时间
在 linux 中 ls 指令可能是 最常用的,由于文件所记录的信息实在是太多了, 所以默认显示的只有:非隐藏文档、以文件名进行排序、文件名代表的颜色显示
实践练习
1 | # 将家目录下的所有问价列出来,包含属性与隐藏文件 |
可以看到 ls 支持的功能很多,这些都是因为 linux 文件系统记录了很多有用的信息的缘故, 那么这些与权限、属性有关的数据放在 i-node 里面的。后续会深入讲解 i-node 的
另外,由于 ls -l 使用频率很高,为此,很多 distribution 在预设情况中已经将 ll 设定为 ls -l 的意思了。其实,那个功能是 Bash shell 的 alias 功能
复制、删除与移动:cp、rm、mv
cp:copy 复制文件,该指令还有其他功能,如建立连接档、比较亮文件的新旧而给予更新,复制整个目录等功能mv:move 移动目录与文件,也可以直接拿来当做更名(rename)rm:remove 移除文件
cp 复制文件或目录
1 | cp [-adfilprsu] 来源文件(source)目标文件(destination) |
选项与参数:
- a:相当于 -dr –preserve=all 的意思,至于 dr 请参考下列说明;(常用)
- d:若来源文件为链接文件的属性(link file),则复制链接文件属性而非文件本身
- f:强制(force)的意思,若目标文件已经存在且无法开启,则移除后再尝试一次
- i:若目标文件已经存在时,在覆盖时会先询问动作的进行。(常用)
- l:进行硬式链接(hard link)的链接档的建立,而非复制文件本身
- p:连同文件的属性(权限、用户、时间)一起复制过去,而非使用默认属性;(备份文件常用)
- r:递归持续复制,用于目录的复制行为。(常用)
- s:复制称为符号链接文件(symbolic link)
- u:destination 与 source 旧才更新 destination,或 destination 不存在的情况下才复制
--preserve=all:除了 -p 的权限相关参数外,还加入 SELinux 的属性,links、xattr 等也复制
最后需要注意的是:如果来源档有两个以上,则最后一个目的文件一定要是目录才行
而且不同身份者执行这个指令会有不同的结果产生,尤其是 -a、**-p** 的选项,对于不同身份来说, 差异则非常的大。
实践练习
1 | # 使用 root 身份,将家目录下的 .bashrc 复制到 /tmp 下,并更名为 bashrc |
上面示例中,不加任何选项会使用预设的配置,比如常常会复制别人的数据(当然需要有 read 权限), 总是希望复制到的数据最后是我们自己的,所以上面示例才有由 utmp 变更为 root
由于具有这个特性,因此在进行备份的时候,需要特别注意的特殊权限文件,例如密码文件(/etc/shadow) 以及一些配置文件,就不能直接以 cp 来复制,需要将全部的属性都原样复制过来
1 | # 复制 etc 目录下的所有内容 |
创建符号链接与实体链接
1 | # 将之前复制过来的 bashrc 建立一个链接档 |
使用 -l 及 -s 都会建立连接档(link file),那么有什么不同呢?
- bashrc_link:使用 s 创建出来的,是符号链接(symbolic link),简单说是一个快捷方式,会链接到 bashrc 中去。有一个 -> 的符号
- bashrc_hlink:使用 l 创建出来的,是实体链接(hard link)
实体链接与源文件的属性与权限一模一样,与尚未链接前的差异是 第二栏 的 link 由 1 变成了 2. 由于实体链接与 i-node 有关,这里先不深入了。
备份常见下的复制
当源文件比目标新的时候才复制
1 | # 先查看两个文件的时间,可以看到源文件是 2013 年,比目标文件旧 |
连接文档的复制
1 | # 该文件是一个符号链接文件 |
多个文件同时复制到通一个目录下
1 | cp ~/.bashrc ~/.bash_history /tmp/ |
身份不同执行 cp 指令表现不同
1 | # 使用 mrcode 身份, -a 把文件原原本本的复制过来 |
rm (移除文件或目录)
- f:force 强制的意思,忽略不存在的文件,不会出现警告信息
- i:互动模式,在闪出去会询问使用者是否操作
- r:递归删除
实践练习
1 | # 互动模式删除 |
由于 root 的是天神,所以大部分 distribution 都默认添加了 -i 的选项,删除前请三思啊。
mv 移动文件与目录或更名
1 | mv [-fiu] source destination |
- f:强制,如果目标文件已经存在,不会询问,直接覆盖
- i:若目标文件已经存在时,就会询问是否覆盖
- u:若目标已经存在,且 source 比较新,才会功更新该文件
1 | [root@study tmp]# cd /tmp/ |
取得路径的文件名与目录名称,basename、dirname
每个文件的完整文档名包含了前面的目录与最终的文件名,而每个文档名的长度都可达 255 个字符, 那么怎么区分哪个是文件名?哪个是目录名?可以使用斜线「/」来分辨
一般要获取文件名或目录名称,都是些程序的手来判断用,所以这部分指令可以用在后续的 shell scripts 里面。
1 | # /etc/sysconfig/network 比如这个路径 |
文件内容查阅
查阅一个文件内容是,这里有相当多有趣的指令来了解下, 最常使用的可以说是 cat 、more、less,那么当查阅一个很大型的文件的时候, 想要在几百兆的文件内容中找到我们想要的数据怎么办?下面的指令能发挥出一些作用
- cat:由第一行开始显示文件内容
- tac:从最后一行开始显示,可以看出 tac 是 cat 的倒着写
- nl:显示的时候顺道输出行号
- more:一页一页的显示文件内容
- less:与 more 类似,但是比 more 更好的是,他可以往前翻页
- head 只看头几行
直接检视文件内容
直接查阅一个文件的内容可以使用 cat、tac、nl 这几个指令
cat(concatenate)
1 | cat [-AbEnTv] |
- A:相当于 -vET 的整合选项,可列出一些特殊字符而不是空白
- b:列出行号,仅针对非空白行做行号显示,空白行不标行号
- E:将结尾的断行字符 $ 显示出来
- n:打印出行号(包含空白行)
- T:将 tab 按键以 ^I 显示出来
- v:列出一些看不出来的特殊字符
实践练习
1 | [root@study tmp]# cat /etc/issue |
下面练习显示特殊的内容
1 | [root@study tmp]# cat -A /etc/man_db.conf |
tac 反向列示
1 | # 从最后一行开始显示 |
nl 添加行号打印
1 | nl [-bnw] 文件 |
- b:指定行号指定的方式,主要有两种
-b a:表示不论是否为空行,也同样列出行号(类似 cat -n)-b t:如果有空行,空行不要列出行号(默认值)
- n:列出行号表示的方法,主要有三种
-b ln:行号在屏幕的最左方显示-b rn:行号在自己字段的最右方显示,且不加 0-b rz:行号在自己字段的最有方显示,且加 0
- w:行号字段的占用字符数
实践练习
1 | # 用 nl 列出 /etc/issue 的内容 |
可翻页检视
more 一页一页翻动
1 | [root@study tmp]# more /etc/man_db.conf |
在 more 程序中,有几个按键可以按:
- 空格键(space):向下翻一页
- Enter:向下翻一行
/字符串:在显示的内容中,向下搜索「字符串」这个关键词- q:立即离开 more
- b 或 ctrl+b:向前翻页,只针对文件有用,对管线(管道
|)无用
less 一页一页翻动
1 | # 使用指令后,就会进入到 less 环境 |
可以使用的按键和指令有
- 空格键:向下翻一页
- pagedown:向下翻一页
- pageup:向上翻一页
/字符串:向下搜索字符串;注意这个斜杠也是需要输入的,不是在 「:」输入,:也和这个是一个功能?字符串:向上搜索字符串- n:重复前一个搜索(与 / 或 ?有关)
- N:反向的重复前一个搜索
- g:前进到这个资料的第一行
- G:前进到这个资料的最后一行去(注意是大写)
- q:离开 less 这个程序
此外,man page 就是调用 less 来显示说明文件内容的,所以看上去很相似
笔者工作中查看日志中有用得数据的时候,就是这个 less 了,但是只知道 shift+g 可以前进到最后一行去,原来 shift+g 其实就是输入了大写的 G 指令
资料摘取
可以将输出的资料做一个最简单的摘取,如去除文件前面几行(head)或则后面几行(tail), 需要注意的是, head 和 tail 都是以行为单位来进行摘取的
head 取出前面几行
1 | head [-n number] 文件 |
1 | # 默认显示前 10 行,可以指定显示 20 行 |
tail 取出后面几行
1 | tail [-nf number] 文件 |
1 | # 默认显示最后 10 行 |
组合使用示例
1 | # 获取 第 11 到 20 行的数据 |
|:管线/管道符,前面的指令所输出的信息,请透过管线交由后续的指令继续使用。后续会详细讲解
上面的例子,其实我也不知道到底取出来的行数对不对,那么就可以使用管线来组合其他的指令使用
1 | # 先使用 cat -n 显示行号,再交给后续的指令 |
非纯文本 od
上面讲解了读取出文本的内容,那么想阅读非文本文件呢?比如查看 /usr/bin/passwd 文档, 使用上面提出来的指令读取就会乱码。
可以使用 od 指令来读取
1 | od [-t TYPE] 文件 |
type 选项为:
- a:利用默认的字符来输出
- c:使用 ASCII 字符来输出
d[size]:十进制(decimal)输出数据,每个整数占用 size bytesf[size]:浮点数(floating)输出数据o[size]:八进制(octal)x[size]:十六进制(hexadecimal)
实践练习
使用 ASCII 展示
1 | [root@study ~]# od -t c /usr/bin/passwd |
使用 8 进制位列出存储值与 ASCII 的对照表
1 | [root@study ~]# od -t oCc /etc/issue |
对照指令对于工程师来说可能更有用处,上面是文件是一个纯文本文件,显示了字符的 ACCIS 对照表, 百度了下, ACCIS 可以与上面的各种进制来对照
比如 password 字符串,需要他的 10 进制对照表
1 | # 可以使用管道符来给 od 处理 |
修改文件时间或新建文件 touch
使用 ls 指令的时候,提到过每个文件 linux 底下都会记录许多的时间参数,其实是有三个主要的变动时间:
modification time(mtime)
当文档 内容数据 变更时。该时间会被更新。
status time(ctime)
当文件 状态 改变时。比如权限与数学被更改了
access time(atime)
当文件 内容被取用 时。比如我们使用 cat 去读取 /etc/man_db.conf ,该时间就会改变
1 | [root@study ~]# date;ls -l /etc/man_db.conf ;ls -l --time=atime /etc/man_db.conf ;ls -l --time=ctime /etc/man_db.conf |
当你看到一个未来时间的文件,这个是有可能的,因为支持多时区,安装系统行为不当,就有可能导致这种情况发生
可以使用 touch 来修订时间
1 | touch [-acdmt] 文件 |
- a:仅修订 access time
- c:仅修改文件的时间,若该文件不存在则不建立新文件
- d:后面可以接欲修订的日期而不用目前的日期,也可以使用 –date=”日期或时间”
- m:仅修改 mtime
- t:后面可以接欲修订的时间而不用目前的时间,格式为 YYYYMMDDhhmm
实践练习
1 | [mrcode@study ~]$ cd /tmp/ |
那么 touc 中最常用的功能是:
- 建立一个空的文件
- 将某个文件日期秀固定为目前(mtime 与 atime)
- 比较重要的是 mtime,关心这个文件内容是什么时候被更新的
文件与目录的默认权限与隐藏权限
前面讲解过文件有若干的属性,读写执行等基本权限(rwx), 是否为目录(d)、文件(-)或则是链接(l)等属性,修改属性也可通过 chgrp、chown、chmod。
除了基本的 rwx 权限外,在传统的 ext2、3、4 文件系统下,还可以设置其他的系统隐藏属性, 可以使用 chattr 来设置,以 lsattr 来查看,最重要的属性就是可以设置不可修改的特性, 让连文件的拥有者都不能进行修改。
在安全机制方面特别的重要,但是在 CentOS7 中利用 xfs 作为预设文件系统, 该文件系统就不支持 chattr 参数了,仅有部分参数还有支持
文件预设权限 umask
umask:指定目前用户在建立文件或目录时候的默认权限
1 | # 以数值形态显示 |
在数值形态下有 4 组,第一组是特殊权限用的,先不看,因此预设情况如下:
文件
没有可执行(x)权限、只有 rw 两个项目,也就是最大为 666 分
-rw-rw-rw-目录
由于 x 与是否可以进入此目录有关,因此默认所有权限均开发,即 777 分
drwxrwxrwx
注意:umask 的分数指的是,该默认值需要 减掉 的权限!也就是需要从预设的权限中减掉
使用上面的示例来说明:
1 | r、w、x 分别是 4、2、1 分。 |
不信吗?可以实践看下
umask 的利用与重要性:专题制作
你和你同学在同一个目录下 /home/class 合作一个专题,那么有没有可能你制作的文件, 你的同学无法编辑?
如果 umask 设置为 0022 ,那么相当于 group 默认创建只有 r 属性,除了拥有者, 其他人只能读,不能写。所以需要修改 umask 的值
1 | # 修改语法是 umask 后接数值 |
TIP
umask 对于新建文件与目录的默认权限很重要,这个概念可以用在任何服务器上面, 尤其是未来假设文件服务器(file server),如 SAMBA Server 或则是 FTP server 时, 牵涉到你的使用者是否能够将文件进一步利用的问题
原来在预设的情况下,身份不同默认值也是不同的,root 的 umask 默认是 022,一般账户是 002。 关于预设设定可以参考 /etc/bashrc 这个文件的内容,不过这里不建议修改该文件, 后续讲解 bash shell 环境参数配置中再详解
文件隐藏属性
除了基本的 9 个权限外,还有隐藏属性,而隐藏属性对系统有很大的帮助,尤其是在安全上面。
chattr 配置文件隐藏属性
强调:在 ext2/3/4 中完全支持,而在 xfs 上部分支持
1 | chattr [+-=][ASacdistu] 文件或目录名称 |
+:增加一个特殊参数,其他参数不变-:移除一个特殊参数=:设定为后面接的参数- A:若有存取此文件/目录时,它的访问时间 atime 将不会被修改
- S:对文件的修改变成同步写入磁盘中,一般默认是异步写入(前面章节讲到过 sync)
- a:该问价只能增加数据,不能删除也不能修改数据,只有 root 才能设置该属性
- c:自动将此文件压缩,在读取的时候也将会自动解压缩,但是在存储的时候,会先压缩后再存储(对大文件似乎有用)
- d:当 dump 程序被执行的时候,可使该标记的文件或目录不被 dump 备份
- i:让文件不能被删除、改名、设置连接、写入或新增数据,完完全全就是只读文件了。只有 root 能设置该属性
- s:当文件被删除时,将会被完全的移除这个硬盘空间,所以如果误删,就找不回来了
- u:与 s 相反,删除后,其实数据还在磁盘中,可以用来救援该文件
注意:
- 属性设置常见的是 a 与 i 的设置,而且很多设置值必须要 root
- xfs 文件系统仅支持 AadiS 选项
实践练习
1 | [root@study tmp]# cd /tmp/ |
个人觉得 +i 和 +a 属性最重要:
i:无法被更动a:不能修改旧的数据,只能新增
那么 a 属性在后续的登录档(log file)这种登录日志类的场景就很适合了
lsattr 显示文件隐藏属性
1 | lsattr [-adR] 文件或目录 |
- a:将隐藏文件的属性也秀出来
- d:如果接的是目录,仅列出目录本身的属性而非目录内的文件名
- R:连同子目录的数据也列出来
1 | # 这里创建一个文件,然后观察他的特殊属性 |
文件特殊权限 SUID、SGID、SBIT
除了前面的 9 个权限之外,还有特殊的权限,如下面两个目录
1 | [mrcode@study ~]$ ls -ld /tmp/;ls -l /usr/bin/passwd |
s 与 t 这两个的权限与后续的 「系统的账户」及系统的程序(process)较为相关, 关于概念需要再后续两个章节讲完之后,才会了解,这里只需要知道 SUID、SGID 如何设定即可
Set UID
当 s 标志出现在文件拥有者 x 权限上时,就被称为 Set UID,简称 SUID 特殊权限, 对于文件的特殊功能如下:
- SUID 权限仅对二进制程序(binary program)有效
- 执行者对于该程序需要具有 x 的可执行权限
- 本权限仅在执行该程序的过程中有效(run-time)
- 执行者将具有该程序拥有者(owner)的权限
比如:linux 中,所有的账户的密码都记录在 /etc/shadow 文件中,既然该文件仅有 root 可以修改,那么我自己的 mrcode 一般账户使用者能否自行修改自己的密码呢?
1 | [mrcode@study ~]$ passwd |
使用如上命令,发现可以修改,那么: shadow 一般账户不能读取,为什么还能修改密码呢?(也就是间接的修改了 shadow 中的数据),这就是 SUID 的功能了。
- mrcode 对于 /usr/bin/passwd 这个程序来说具有 x 权限的,表示 mrcode 能执行 passwd
- passwd 的拥有者是 root 账户
- mrcode 执行 passwd 的过程中,会暂时获得 root 的权限
- /etc/shadow 就可以被 mrcode 所执行的 passwd 所修改
那么使用 cat 去读取 /etc/shadow 可以吗?通过查看 cat 的权限,会发现 cat 没有包含 SUID 特殊权限,就是为什么不能读取的原因
1 | [mrcode@study ~]$ ll /usr/bin/passwd |
TIP
SUID 仅可用在 binary program 上,不能用在 shell script 上面, 因为 shell script 只是将很多的 binary 执行档叫进来执行而已。
所以 SUID 的权限部分需要看脚本中执行的指令是否具有 SUID ,而不是脚本自身。 对目录页是无效的
Set GID
s 在群组的 x 时称为 Set GID
1 | [mrcode@study ~]$ ls -l /usr/bin/locate |
SGID 可以针对文件或目录来设置,针对文件来说有如下功能含义:
- SGID 对二进制程序有用
- 程序执行者对于该程序来说,需要具备 x 的权限
- 执行者在执行的过程中将会获得该程序群组的支持
例如:**/usr/bin/locate** 这个程序可以搜索 /var/lib/mlocate/mlocate.db 文件内容, 权限如下
1 | [root@study ~]# ll /usr/bin/locate /var/lib/mlocate/mlocate.db |
如果使用 mrcode 账户去执行 locate 时,mrcode 将会取得 slocate 群组的支持; (这里有点懵逼,使用 locate -A /var/lib/mlocate/mlocate.db 没有报错,但是没有内容, 但是直接使用 ll /var/lib/mlocate/ 却提示没有权限,只能后续的课程讲了后才知道是什么意思了)
除了 binary program 外,SGID 还能用在目录上,当一个目录设置了 SGID 的权限后,将具有如下的功能:
- 用户若对于此目录具有
r与x的权限时,该用户能够进入此目录 - 用户在此目录下的有效群组(effective group)将会变成该目录的群组
- 用途:若用户在此目录下具有
w的权限(可以新建文件),则使用者所建立的新文件,该新文件的群组与此目录的群组相同
SGID 对于项目开发来说非常重要,涉及到群组权限的问题。可以参考下后续的「情景模拟的案例」, 能加深一点了解
Sticky Bit
Sticky Bit简称为 SBT ,目前只针对目录有效,对于文件没有效果了
作用是:当用户对于此目录具有 w、x 权限,即具有写入的权限时,当用户在该目录下简历文件或目录时, 仅有自己与 root 才有权利删除该文件
例如:mrcode 用户在 A 目录是具有 w 的权限(群组或其他人类型权限),这表示 mrcode 对该目录 内任何人简历的目录或则文件均可进行删除、更名、搬移等动作,但是将 A 目录加上了 SBIT 的权限时,则 mrcode 只能够针对自己建立的文件或目录进行删除、更名、搬移等动作,而无法删除他人的文件
TIP
这部分内容在后续章节「关于程序方面」的只是后,再回过头来看,才能明白讲的是什么
SUID、SGID、SBIT 权限设定
可以使用数值权限更改方法来设置,他们代表的数值是:
- SUID:4
- SGID:2
- SBIT:1
下面演示具体这个数值加载哪里
1 | [root@study tmp]# cd /tmp/ |
下面再来演示几个
1 | # 添加 SUID + SGID 权限 |
上面最后一个例子出现了大写的三个特殊权限 S、S、T,这里是这样的,因为 666 的权限中 不包含 x 权限,所以当特殊权限出现在 x 中的时候(又不拥有 x)则会出现大写的,表示空。 SUID 表示该文件在执行的时候,具有文件拥有者的权限,但是文件拥有者都无法执行了, 哪里来的权限给其他人使用呢?
除了数值,还可以使用符号来处理:
- SUID:u+s
- SGID:g+s
- SBIT:o+t
1 | # 设置为 -rws--x--x |
观察文件类型 file
想知道某个文件的基本数据,例如属于 ASCII 或则是 data 文件、binary 、是否用到动态函数库(share library)等信息,可以使用 file 指令来检阅
1 | # ASCII 文本文件 |
通过这个指令可以简单的判断文件的格式,包括判断使用 tar 文档是使用的哪一种压缩功能
指令与文件的搜寻
很有用的功能之一,需要搜索某个文件在哪个位置,因为很多软件的配置文件名是不变的, 但是各 distribution 放置的目录则不同。要把位置找出来才能修改配置
脚本文件名的搜索
我们已经知道在终端模式下,连续两次「tab」有指令补全的功能,能展示出想匹配的指令, 那么这些指令在哪里呢?
which 搜索执行文档
1 | which [-a] command |
1 | # 搜索 ifconfig 这个指令完整文件名 |
上面 history 为什么找不到?
- which 根据 PATH 环境变量中的目录来搜索的
- 只能找出执行文件
- history 是 bash 内置的指令
history 不在 PATH 内的目录中,是 bash 内置的指令, 但是可以通过 type 指令,后续章节 bash 详解
文件名的搜索
linux 中有许多搜索指令,通常 find 不很常用,因为速度慢,操硬盘(啥意思?), 一般先用 whereis 或则是 locate 来检查,如果找不到,则用 find 来搜索。
- whereis 只找系统中某些特定目录下的文件,速度快
- locate 则利用数据库来搜索文件名的,速度块
- find 搜索全磁盘内的文件系统状态,耗时
whereis 由一些特定的目录中搜索文件名
1 | whereis [-bmsu] 文件或目录名 |
- l:列出 whereis 会去查询的几个主要目录
- b:只找 binary 格式的文件
- m:只找在说明文件 manual 路径下的文件
- s:只找 source 来源文件
- u:搜索不在上述三个选项中的其他特殊文件
1 | # 找到 ifconfig 文件名 |
whereis 主要是针对 /bin/sbin 下的执行文件、**/usr/share/man** 下的 man page 文件、和几个特定的目录,所以速度块很多,由于不是全盘查找,可能找不到你想要的文件,可以使用 whereis -l 来显示具体会找那些目录
locate / updatedb
1 | locate [-ir] keyword |
- i:忽略大小写的差异
- c:不输出文件名,仅计算找到的文件数量
- l:仅输出几行,例如输出五行则是 -l 5
- S:输出
locate所使用的数据库文件相关信息,包括该数据库记录的文件/目录数量等 - r:后面可接正规表示法的显示方式
1 | # 找出系统中所有与 passwd 先关的文件名,且只列出 5 个 |
locate 可以其实就是模糊搜索,只要包含关键词的文件名都会被匹配,他是他有一个限制, 查找的数据是已建立的数据库 /var/lib/mlocate 里面的数据来搜索的。
该数据库建立默认是每天执行一次(每个 distribution 不同,CentOS 7 是每天更新一次数据库), 所以能搜索到的结果是有延迟的
可以手动触发数据库的更新,直接使用 updatedb 指令就可以
updatedb
根据 /etc/updatedb.config 的设置去搜索系统盘内的文件名,并更新到 /var/lib/mlocate 数据库文件内
locate:从 /var/lib/mlcate 内的数据库中搜索关键词
find
1 | find [path] [option] [action] |
与时间有关的参数
与时间有关的参数有 -atime、**-ctime、-mtime,以 **-mtime 说明:
- mtime n:在 n 天前的「一天之内」被修改过内容的文件
- mtime +n:列出在 n 天之前(不含 n 本身)被修改过内容的文件
- mtime -n:列出在 n 天之内(含 n 天本身)被修改过内容的文件
- newer file:file 为一个存在的文件,列出比 file 还要新的文件
1 | # 将过去系统上 24 小时内有更动过内容(mtime)的文件列出 |
mtime 选项的 n 正负数差别表示不同的含义,图示如下
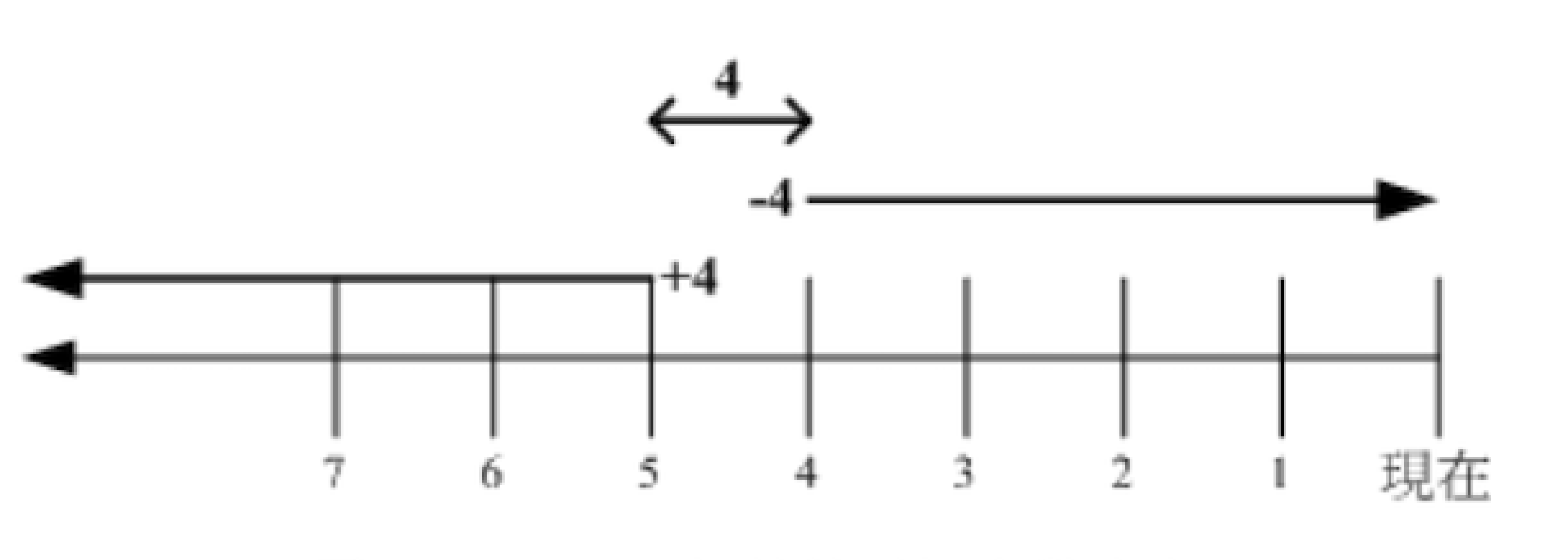
+4:表示大于等于 5 天前的-4:表示小于等于 4 天内的- 4:表示 4~5 哪一天的文件
与使用者或组名有关的参数
uid n:n 为数字,是用户的账户 ID(UID),UID 记录在 /etc/passwd 里面与账户名称对于的数字。后续介绍
gid n:n 为数字,是组名的 ID,记录在 /etc/group 文件中
user name:name 为使用者账户名称,如 mrcode
group name:name 为组名
nouser:寻找文件的拥有者不存在 /etc/passwd 的人
nogroup:寻找文件的拥有群组不存在 /etc/group 的文件
当你自行安装软件时,很可能该软件的属性当中并没有文件拥有者,这个时候就可以使用 nouser 与 nogroup
实践与练习
1 | # 查找 /home 下属于 mrcode 的文件 |
nouser 和 nogroup 的选项,除了你自行由网络上面下载文件时会发生之外,如果你将系统里面某个账户删除了, 但是该账户以及在系统内建立了很多文件,那么就可能发生 nouser 和 nogroup 的文件
与文件权限及名称有关的参数
name filename:查找文件名为 filename 的文件
size [-+]SIZE:查找比 SIZE 还要大(**+)或则小(-**)的文件
SIZE 支持的单位有:
- c:byte
- k:1024 byte
所以要查找 比 50 KB 还要大的文件,指令为
find /home/ -size +50kstype TYPE:查找文件类型为 TYPE 的。主要有
- f:一般正规文件
- b,c:装置文件
- d:目录
- l:连接
- s:socket
- p:FIFO
perm mode:查找文件权限「刚好等于」mode 的文件,mode 为类似 chmod 的属性。
例如:**-rwsr-xr-x** 的属性为 4755
perm -mode:查找文件权限「必须要全部包括 mode 的权限」的文件
例如:查找 -rwxr–r– ,即 0744 的文件,使用 -perm -0744
perm /mode:查找文件权限「包含任意 mode 的权限」的文件
例如:**-rwxr-xr-x,即 **-perm /755 时,但一个属性属性为 -rw—— 也会被列出来, 因为他有 -rw 的属性存在
实践与练习
1 | # 找出文件名为 passwd 的文件 |
上面范例中比较有趣的是 -perm 可以找出特殊权限的文件,SUID 与 SGID 都可以设置在二进制文件上
1 | # 找出 /usr/bin /usr/sbin 具有 SUID 或 SGID 的文件 |
额外可以进行的动作
- exec command:
command为其他指令,**-exec** 后面可再接额外的指令来处理搜索到的结果 - print:将结果打印到屏幕上,这个动作是预设的,不然不会看到结果
实践与练习
1 | # 将上个范例找到的文件使用 ls -l 列出来 |
find 的特殊功能就是可以进行额外的动作(action),图解一个范例
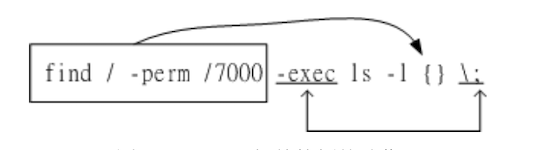
{}:表示由 find 找到的内容-exec 开头到 \; 结尾:中间的表示指令额外动作;:在 bash 环境下又特殊意义的,用斜杠\来跳脱
说使用 find 在寻找数据的时候相当操硬盘是啥意思?耗费硬盘?所以能用 whereis 与 locate 操作的尽量用
删除 n 天前的文件
笔者这里既然学习了 find 知识点,现在拿出之前在工作中经常用到删除 n 天前的指令来分析下, 看能不能看懂
1 | find /usr/local/backups -mtime +10 -name "*.*" -exec rm -rf {} \; |
find 常用命令收集
以下收集一些常用的使用方式
1 | # 搜索文件内容,并显示命中的文件 与 内容所在行 |
权限与指令间的关系
权限对于使用者账户来说是非常重要的,因为可以限制使用者不能读取、建立、删除、修改文件或目录。
那么什么指令在什么样的权限下才能够运行?
让用户能进入某目录称为「可工作目录」的基本权限
- 可使用的指令:例如 cd 等变换工作目录的指令
- 目录所需权限:用户对这个目录至少具有 x 的权限
- 额外需求:如果想在该目录内利用 ls 查阅文件名,则还需要有目录的 r 权限
用户在某个目录内读取一个文件的基本权限
- 可使用的指令:例如 cat、more、less 等
- 目录所需权限:至少具有 x 权限
- 文件所需权限:至少具有 r 权限
让使用者可以修改一个文件的基本权限(修改文件内容)
- 可使用的指令:例如 nano 或未来要介绍的 vi 编辑器等
- 目录所需权限:至少具有 x 权限
- 文件所需权限:至少具有 r、w 权限
让一个使用者可以建立一个文件的基本权限
- 目录所需权限:至少具有 w、x 权限,重点是 x 权限
让用户进入某目录并执行该目录下的某个指令之基本权限
- 目录所需要的权限:至少具有 x 权限
- 文件所需要的权限:至少具有 x 权限
文件与文件系统的压缩、打包与备份
压缩文件的用途与技术
文件压缩技术一般用于的场景是:当文件容量很大的时候,想要降低一些容量,在网络中传输时间少,当然下载的人就能更快的下载完,还有数据归档使用 cd 或则 dvd 来存储,但是某些单一文件比这些传统的一次性存储媒体还要大、等等的场景。
简单说就是:这些大型文件通过压缩技术之后,可以将他的磁盘使用量降低,达到减低文件容量的效果
文件压缩的原理是什么?
计算机最小的计量单位是 bits,不过目前我们使用的计算机系统中都是使用 bytes 单位来计量的,1 bytes=8bits,计算机存储文件是二进制的,当这个 8 bits 中没有被填满时,就会出现大量的 bit 被 0 填充,实际上他们是没有什么意义的,一些工程师利用一些复杂的计算方式,将这些没有使用到的空间去掉,来达到让文件占用空间变小的目的,这就是 压缩技术
还有一种压缩技术是将重复的数据进行统计记录。比如:你的数据为「1111….」有 100 个 1,压缩技术会记录「100 个 1」,而不是真的写了 100 个 1 出来。这样也能达到减少文件体积的目的
简单说:文件里面有相当多的「空间」存在,并不是完全填满的,而压缩技术就是将这「空间」填满,让整个文件占用的容量下降。但是被压缩过的文件无法被直接使用,需要还原回未压缩前的模样,这就是 解压缩 技术。
压缩后与压缩的文件所占用的磁盘空间大小,就可以被称为是「压缩比」,更多的技术可以查阅 GZIP 文件格式规范
解压缩有什么好处呢?Linux 3.10.81(CentOS 7 用的延伸版本)完整核心大小约 570MB 左右,由于核心主要多是 ASCII code 的纯文本形态文件,这种文件的「多余空间」是比较多的。那么压缩之后的核心仅有 76MB 左右,相差几倍。网络传输时间减少,你的磁盘占用也减少。
Linux 系统常用的压缩指令
在 linux 环境中,压缩文件的扩展名大多是:.tar、.tar.gz、.tgz、.Z、.bz2、.xz ,为什么会有这么多?
虽然在 linux 下扩展名没有啥作用,但是支持的压缩指令非常多,彼此之间无法互通压缩或解压缩,扩展名用于分别是使用哪种软件来解压缩。常用的扩展名如下:
.Z:compress 程序压缩的文件- .
zip:zip 程序压缩的文件 .gz:gzip 程序压缩的文件.bz2:bzip2 程序压缩的文件.xz:xz 程序压缩的文件.tar:tar 程序打包的数据,并没有压缩过.tar.gz:tar 程序打包的数据,并经过 gzip 的压缩.tar.bz2:同上,经过了 bzip2 压缩.tar.xz:同上,经过了 xz 的压缩
linux 上常见的压缩指令是 gzip、bzip2 以及最新的 xz,还有支持 windows 的 zip,至于其他的压缩指令基本上都淘汰了。这些指令通常仅能针对一个文件来压缩与解压缩,如此一来每次压缩与解压缩都要一大堆文件,所以 tar (打包)软件就出现了
tar 可以将很多文件「打包」成为一个文件,将很多文件集结为一个文件,但是没有提供压缩的功能,后来 GNU 计划中,将整个 tar 与压缩的功能结合在一起,提供了更强大的压缩与打包功能。
gzip,zcat/zmore/zless/zgrep
gzip 可以说是应用最广的压缩指令,目前可用解开 compress、zip 与 gzip 等软件所压缩的文件,语法如下
1 | gzip [-cdtv#] 文档名 |
选项与参数:
- c:将压缩的数据输出到屏幕上,可通过数据流重导向来处理
- d:解压缩的参数
- t:可以用来检验一个压缩文件的一致性,看看文件有无错误
- v:可以显示出原文件、压缩文件的压缩比等信息
- **#**:为数字的意思,代表压缩等级
- -1:最快,但是压缩比最差
- -9:最慢,但是压缩比最好
- -6:默认值
实践练习
1 | # 找出 /etc 下(不含子目录)容量最大的文件,并将他们复制到 /tmp,然后以 gzip 压缩 |
这里需要注意,使用 gzip 进行压缩时,默认状态下原本的文件会被压缩成 .gz 的文件,并且原始文件不存在了(文案已经提示了);另外 gzip 压缩的文件在 windows 中可以被 WinRAR、7zip 软件解压缩
1 | # 由于 services 是文件内容,将压缩后的文件内容读出来 |
在压缩文档中搜索字符的话可以使用 zgrep、egrep 等指令
bzip2、bzcat/bzmore/bzgrep
bzip2 可以说是取代了 gzip 并提供更佳的压缩比。使用方式几乎与 gzip 相同
1 | bzip2 [-cdkzv#] 文档名 |
选项与参数:
- c:将压缩的过程产生的数据输出到屏幕上
- d:解压缩的参数
- k:保留源文件
- z:压缩的参数(默认值,可以不加)
- v:可以显示出源文件/压缩文件的压缩比信息
#:与 gzip 一样,-9 最佳、-1 最快
实践练习
1 | [mrcode@study tmp]$ bzip2 -v services |
使用方式 bzip2 与 gzip 几乎一模一样,不过压缩率好的一般都会更耗时
xz、xzcat/xzmore/xzless/xzgrep
xz 比 bzip2 压缩比更高,用法也与 bzip2、gzip 就一模一样
1 | xz [-dtlkc#] 文档名 |
选项与参数:
- d:解压缩
- t:测试压缩文件的完整性,看是否有错误
- l:列出压缩文件的相关信息
- k:保留原本的文件
- c:将数据由屏幕上输出
#:同样,压缩比数值
1 | # 压缩 |
打包指令:tar
前面讲解的 gzip、bzip2、xz 也能够针对目录进行压缩,但是是将目录内所有文件 分别 压缩的。而在 windows 下可以使用 winRAR 之类的压缩文件,将好多数据包成一个文件的样式。
这种将多个文件或目录包成一个大文件的指令功能,就可以称呼为 打包指令,tar 就是这样一个功能的打包指令,同时还可以通过压缩指令将该文件进行压缩。windows 中的 WinRAR 也支持 .tar.gz 的解压缩
tar 的选项与参数非常多,这里只接受几个常用的选项
1 | 打包与压缩:`tar [-z|-j|-J][cv][-f 待建立的文件名] filename` |
选项与参数
- c:建立打包文件,可搭配
-v来观察过程中被打包的文件名 - t:查看打包文件的内容含有哪些文件,重点在查看文件名
- x:接打包或解压缩的功能,可搭配 -C 在特定目录解开,特别注意 c、t、x 不能同时出现在一起
- z:通过 gzip 的支持进行压缩、解压缩;此时文件名最好为
*.tar.gz - j:通过 bzip2 的支持进行压缩、解压缩;此时文件名最好为
*.tar.bz2 - J:通过 xz 的支持进行压缩、解压缩;此时文件名最好为
*.tar.xz - v:在压缩、解压缩的过程中,将正在处理的文件名显示出来
- f:后面要立刻接要被处理的文件名,建议 -f 单独写一个选项(不容易忘记)
- C:在指定目录解压缩
- p:保留备份数据的原本权限与属性,常用语备份(-c)重要的配置文件
- P:保留绝对路径,保留 root 跟路径
--exclude=FILE:在压缩过程中,排除指定的文件,不打包
最常用的是以下命令:
- 压 缩:
tar -jcv -f filename.tar.bz2 要被压缩的文件或目录 - 查 询:
tar -jtv -f filename.tar.bz2 - 解压缩:
tar -jxv -f filename.tar.bz2 -C 指定目录解开
小提示:上面 -jcvf 可以写一起,但是阅读起来就没有上面这样分开好理解
使用 tar 加入 -z、-j 或 -J 的参数备份 /etc/ 目录
1 | # 备份 /etc/ 需要 root 权限,否则会出现一堆错误 |
前面讲解 cp 指令复制的时候也涉及到复制后的文件权限与属性问题,这里的 -p 选项也是这样
查阅 tar 文件的数据内容(可查看文件名)与备份文件名是否有根目录的意义
1 | # -v 把权限属性也列出来了 |
为什么需要拿到根目录呢?主要是为了安全,使用 tar 备份的数据可能会需要解压缩回来使用,在 tar 所记录的文件名(上面 -jtv 显示的文件名)就是解压缩后的实际文件名。如果拿到了根目录,则会在当前目录解压。比如现在在 /tmp ,解压后就变成 /tmp/etc/xxx;如果不拿掉根目录,源文件就被覆盖了
1 | [root@study ~]# tar -jPc -f /root/etc.and.root.tar.bz2 /etc |
将备份的数据解压缩,并考虑指定目录压缩(-C 选项的应用)
1 | [root@study ~]# pwd |
仅解开单一文件
前面讲解的都是解开该压缩包中的所有文件。
1 | # 利用 -t 查看文件名,接管道查找 shadow |
打包某目录,但不包含该目录下的某些文件
1 | [root@study ~]# tar -jc -f /root/system.tar.bz2 --exclude=/root/etc* --exclude=/root/system.tar.bz2 /etc /root |
仅备份比某个时刻还要新的文件
1 | # 先找出比 /etc/passwd 还要新的文件 |
基本名称: tarfile, tarball ?
tar 可以只打包不压缩 tar -c -f file.tar,这种文件称为 tarfile,如果有压缩就称为 tarball。
此外 tar 还可以将文件打包到特别的装置中去,例如,tar -c -f /dev/st0/home /root/etc ,把 etc 打包到磁带机去(磁带机是一次性读取、写入装置,因此不能使用 cp 等指令)
特殊应用:利用管线命令与数据流
关于数据流重导向与管线命令在 bash 章节再详细讲解
1 | [mrcode@study ~]$ cd /tmp/ |
例题:系统备份范例
系统上有非常多的目录需要进行备份,也不建议将备份数据放到 /root 目录下,假设目前已经知道重要的目录有:
/etc/:配置文件/home/:用户的家目录/var/spool/mail/:系统中所有的邮件信箱/var/spool/cron/:所有账户的工作排成配置文件/root/:系统管理员的家目录
前面做过的练习,*/home/loop** 不需要备份,**/root** 下的压缩文件也不需要备份,假设需要将备份的数据放到 /backups 中,并且该目录仅有 root 权限进入,此外,每次备份的文件名希望不相同。
1 | # 创建备份目录,并修改权限 |
解压缩后的 SELinux 课题
假如你的系统必须要以备份的数据来回填到原本的系统中,那么需要特别注意复原后的系统 SELinux 问题,尤其是在系统文件上面。比如:**/etc** 下的文件群。SElinux 是比较特别的细部权限设定,具体的会在第 16 章介绍。SELinux 的权限问题,可能让你的系统无法存取某些配置文件内容,导致影响到系统的正常使用权。
有一个例子,通过上面的 tar 备份,然后在另外一部系统上还原回来,但是无法正常的登录系统,在单位维护模式去操作系统,看起来一切都正常,但是这里就是无法登录。大部分原因就是因为 /etc/shadow 密码文件的 SELinux 类型在还原时被更改了,简单的处理方式有如下几个:
- 通过各种可行的救援方式登录系统,修改 /etc/seliux/config 文件,将 SELinux 改成 permissive 模式,重新启动系统就可以了
- 在第一次复原系统后,不要立即重新启动,先使用
restorecon -Rv /etc自动修复下 SELinux 的类型即可 - 通过各种可行的方式登录系统,建立 /.autorelabel 文件,重新启动后系统会自动修复 SELinux 的类型,并且又会再次重新启动,之后就正常了
vim 程序编辑器
系统管理员的重要工作就是需要修改与设置某些重要软件的配置文件,因此至少得学会一种以上的文字模式下的文本编辑器。所有的 Linux distribution 上都有一套文本编辑器 vi,而且很多软件默认也是使用 vi 作为他们编辑器的接口。此外 vim 是进阶版的 vi,不但可以用不同颜色显示文字内容,还能够进行诸如 shell script、C program 等程序编辑功能,可以将 vim 视为一种程序编辑器
vi 与 vim
在 LInux 的世界中,绝大部分的配置文件都是以 ASCII 的纯文本形态存在的,因此利用简单的文字编辑软件就可以修改配置了
在 linux 的文本模式下的编辑器有:emacs、pico、nano、joe、vim 等,那么为何就要学 vi 呢?
为何要学 vim
为什么需要学习 vi ?原因如下:
- 所有 Unix Like 系统都会内置 vi 编辑器,其他的编辑器则不一定会存在
- 很多各别软件的编辑接口都会主动调用 vi (例如未来会讲解的 crontab、visudo、edquota 等指令)
- vim 具有程序编辑的能,可以主动的以字体颜色辨别语法的正确性,方便程序设计
- 因为程序简单,编辑速度相当快
可以将 vim 视作是 vi 的进阶版,有语法高亮等功能。比如当使用 vim 编辑一个 shell script 脚本时,vim 会依据文件的扩展名或则是文件内的开头信息,判断该文件的内容而自动调用该程序的语法判断。甚至一些 Linux 基础配置文件内的语法,都能用 vim 来检查,例如第 7 章谈到的 /etc/fstab 文件内容
简单说,vi 是老式的文字处理器,vim 则是程序开发工具(https://www.vim.org/ 官网也是这样介绍的)而不是文字处理软件。因为 vm 里面加入了很多额外的功能,例如支持正规表示法的搜索架构、多文件编辑、区块复制等等。
vi 的使用
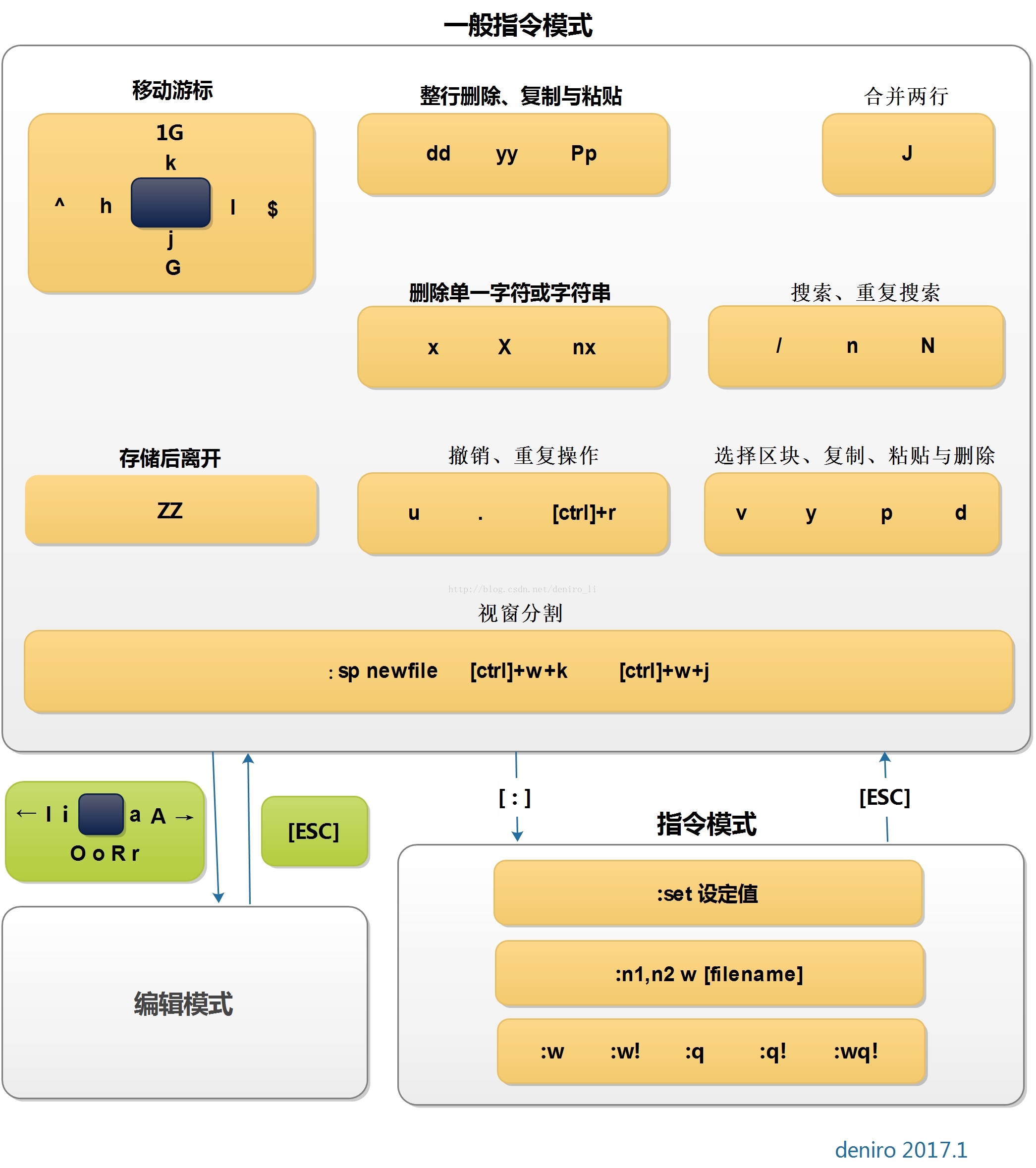
基本上 vi 共分为三种模式:一般指令模式、编辑模式、指令列命令模式
一般指令模式(command mode)
以 vi 打开一个文件就直接进入一般指令模式了(默认模式,也简称一般模式)。
在该模式中,可以使用「上下左右」按键移动光标,可以使用「删除字符」或「删除整列」来处理文件内容,也可以使用「复制、粘贴」
编辑模式(insert mode)
在一般模式中可以进行删除、复制、粘贴等动作,但是无法编辑文件内容。
需要按下「i、I、o、O、a、A、r、R」等任意按键后才会进入编辑模式,通常会在左下方出现 INSERT 或 REPLACE 的字样,可以通过 esc 按键退出编辑模式,回到一般指令模式
指令列命令模式(commadn-line mode)
在一般模式中,输入「**:、/、?**」任意字符,则光标会移动到最底下的一列。
在这个模式中,可以提供你搜索、读取、存盘、大量取代字符、离开 vi、显示行号等功能
简单说,可以将这三个模式想象成下面的图标来表示
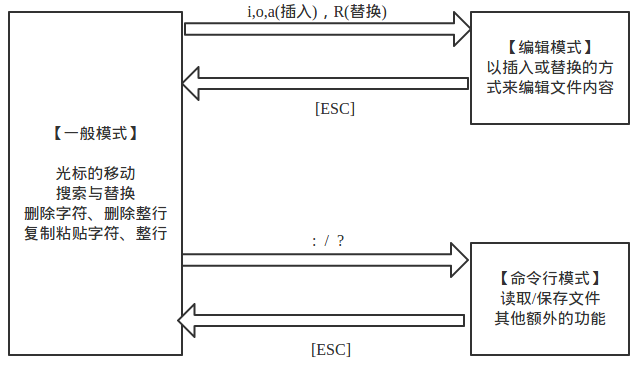
注意这里互换,编辑模式不能直接换到指令列模式!
按键说明
第一部分:一般指令模式可用的按钮说明
移动光标的方法
| 按键 | 说明 |
|---|---|
| h 或 左箭头 ← | 光标向左移动一个字符 |
| j 或 下箭头 ↓ | 光标向下移动一个字符 |
| k 或 向上箭头 ↑ | 光标向上移动一个字符 |
| i 或 右箭头 → | 光标向右移动一个字符 |
| 特别说明 | hjki 在键盘上是排列在一起 的,适合移动光标,移动多个的话可以加上数值再按方向键,比如 30↓ ,向下移动 30 行(注意是一般指令模式下) |
| ctrl + f | 常用;向下移动一页,相当于 Page Down 按键 |
| ctrl + b | 常用;向上移动一页 |
| ctrl + d | 向下移动半页 |
| ctrl + u | 向上移动半页 |
| + | 光标移动到非空格符的下一列 |
| - | 光标移动到非空格符的上一列 |
n<space> |
n 表示数字,如按下 20 ,再按空格键,光标会向右移动 n 个字符 |
| 0 或功能键 Home | 常用;移动到这一行的最前面字自字符处 |
$或功能键 End |
常用;移动到这一行的后面字符处 |
| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
| G | 常用;移动到这个文件的最后一行 |
| nG | n 为数字,移动到这个文件的第 n 行。可配合 :set nu 显示行号,再移动到具体的行 |
| gg | 常用;移动到这个文件的第一行,相当于 1G 的功能 |
n<Enter> |
常用;n 为数字,光标向下移动 n 行 |
搜索与取代
| 按键 | 说明 |
|---|---|
| /word | 常用;向光标之下寻找一个名称为 word 的字符串 |
| ?word | 向光标之上寻找 word |
| n | n 为键盘的 n 按键。代表「重复前一个搜索动作」比如找到多个搜索结果的时候,可以按 n 来跳到下一个下一个 |
| N | 大写的 N 按键,与 n 相反 |
| 说明 | 使用 /word 配合 n 或 N 是非常方便的,可以让你重复的找到一些你搜寻的关键词 |
:n1,n2s/word1/word2/g |
常用;n1 与 n2 为数值。在第 n1 与 n2 列之间查找 word1 这个字符串,并将该字符串替换为 word2;比如::100,200s/mrcode/MRCODE/g 就是在 100 到 200 列之间寻找 mrcode 并替换成大写的 |
1,$s/word1/word2/g |
常用;从第一行到最后一行,将 word1 替换成 word2 |
1,$s/word1/word2/gc |
常用;从第一行到最后一行,将 word1 替换为 word2,在替换前,显示字符让用户确认(confirm)是否需要替换 |
删除、复制、粘贴
| 按键 | 说明 |
|---|---|
| x,X | 常用;在一行字当中,x 为向后删除一个字符(相当于 del 按键),X 向前删除一个字符 |
| nx | n 为数值,连续向后删除 n 个字符 |
| dd | 常用;删除光标所在列(这一行文本) |
| ndd | 常用;删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除光标所在处,到该行最后一个字符 |
| d0 | 删除光标所在处,到该行最前面一个字符,这个 0 就是数值 0 |
| yy | 常用;复制光标所在处的行 |
| nyy | 常用;n 为数值,复制光标所在的向下 n 行 |
| y1G | 复制光标所在处到第一行的所有数据 |
| yG | 复制光标所在处到最后一行的所有数据 |
| y0 | 复制光标所在处那个字符到该行第一个字符的数据 |
| y$ | 复制光标所在处那个字符到该行最后一个字符的数据 |
| p,P | 常用;p 为将以复制的数据在光标的下一行粘贴上,P 则为贴在光标的上一行。 |
| J | 将光标所在行与下一行的数据结合成同一行 |
| c | 重复删除多个数据,例如向下删除 10 行,10cj |
| u | 常用;复原前一个动作 |
| ctrl + r | 常用;重做上一个动作 |
| 说明 | u 与 ctrl + r 是很常用的执行,一个是复原,一个是重做一次 |
| . | 常用;小数点,重复前一个动作。例如先要重复删除、重复粘贴等,按下小数点就可以了 |
第二部分:一般指令模式切换到编辑模式可用的按键说明
| 按键 | 说明 |
|---|---|
| i,I | 常用;进入插入模式(insert mode):i 从当前光标所在处插入,I 从当前所在行的第一个非空格符号处插入 |
| a,A | 常用;进入插入模式,a 从当前光标所在的下一个字符开始插入,A 从光标所在行的最后一个字符处开始插入 |
| o,O | 常用;进入插入模式,o 从当前光标所在的下一行插入新行,O 从光标所在处的上一行插入新的行 |
| r,R | 常用;进入取代模式(Replace mode):r 只会取代光标所在的那个字符一次;R 会一直取代光标所在的文字,直到按下 ESC 为止 |
| 说明 | 上面这些按键中,在 vi 画面左下角会出现 —INSERT— 或 —REPLACE— 的字样。 |
| Esc | 常用;退出编辑模式,回到一般指令模式中 |
第三部分:一般指令模式切换到指令模式的可用按钮说明
指令列模式的存储、离开等指令
| 按键 | 说明 |
|---|---|
| :w | 常用;将编辑的数据写入硬盘文件中 |
| :w! | 若文件属性为「只读」时,强制写入该文件。不过,到底能不能写入,还是跟你对该文件的文件权限有关 |
| :q | 常用;离开 vi |
| :q! | 不想存储,强制离开 |
| 说明 | !惊叹号在 vi 中,常常具有「强制」的意思 |
| :wq | 常用;存储后离开,后面加 !则表示强制存储后离开 |
| ZZ | 若文件没有改动,则不存储离开,若文件已经被改动过,则存储后离开 |
| :w[filename] | 将编辑的数据存成另一个文件,类似另存为 |
| :r[rilename] | 在编辑的数据中,读取另一个文件的数据。即将 filename 文件内容加到光标所在处后面 |
| :n1,n2 w [filename] | 将 n1 到 n2 的内容存储成 filename 这个文件。(n 说的是行数把?) |
| :! command | 暂时离开 vi 到指令模式下执行 comman 的显示结果!例如 「:! ls /home」即可再 vi 中查看 /home 下以 ls输出的文件信息;这个笔者感觉很常用,在编辑中往往会忘记路径啥的,通过这个就可以查看了 |
vi 环境的变更
| 按键 | 说明 |
|---|---|
| :set nu | 在每一行最前面显示行号 |
| :set nonu | 取消行号 |
特别注意,在 vi 中 「数字」是很有意义的,数字通常代表重复做几次的意思,也有可能是代表去到第几个什么什么的意思。
比如:要删除 50 行,使用 「50dd」;向下移动 20 行,使用 「20j」或「20↓」
会上面这些指令就已经很厉害了,因为常用到的指令也只有不到一半,除了上面列举到常用的之外,其他的都不用死记硬背,用到再查询即可
一个案例练习
http://linux.vbird.org/linux_basic/0310vi/man_db.conf 可以使用这个文件来测试
1 | [mrcode@study ~]$ cd /tmp/ |
上面的练习部分比如删除字符等,与书上的部分内容对不上,我想可能是因为整个文件内容就对不上的原因
vim 的暂存档、救援恢复与开启时的警告讯息
在你编辑过程中,突然宕机等情况下,在你还诶呦保存的时候,可能就想要是能恢复下刚刚未保存的数据就好了
那么 vim 就提供了这样的功能,是通过暂存档来实现的。在使用 vim 编辑时,会在被编辑的文件目录下,再建立一个名为 .filename.swp 的文件,编辑的数据会被存在该文件中。
来测试这个恢复功能(注:下面的部分指令,现在还未讲解,后续讲解后,再回头来这里练习下)
1 | [mrcode@study vitest]$ cd /tmp/vitest/ |
上面翻译成中文有如下的主要信息:由于暂存文件的存在,vim 会主动判断你的这个文件可能有些问题,上面列出的两个主要原因与解决方案翻译如下:
可能有其他人或程序同时在编辑这个文件
- 找到另外那个程序或人员,请他将该 vim 的工作结束,然后你再继续处理
- 如果只是想要看该文件的内容并不会有任何修改编辑的行为,那么可以选择开启成为只读文件(O),就是那个 [o] pen Read-Only 选项
在前一个 vim 环境中,可能因为某些不知名的原因导致 vim 中断(crashed)
这就是常见的不正常结束 vim 产生的后果。解决方案依据不同的情况不同,常见的处理方法为:
- 如果之前的 vim 处理动作尚未存储,此时应该按下 R (使用 (R)ecover 选项),此时 vim 会载入 .man_db.conf.swp 的内容,让你自己来决定要不要存储!不过需要你离开 vim 后手动删除 .man_db.conf.swp 文件,避免下次打开还出现这样的警告
- 如果你确定这个暂存文件是没有用的,可以直接按下 D(**(D)elete it**)删除它
下面是出现的 6 个选项的说明:
[O]pen Read-Only:以只读方式打开。不能编辑(E)dit anyway:以正常方式打开文件,不会载入暂存文件中的内容。不过很容易出现两个使用者互相改变对方的文件等问题。不推荐(如果是多人编辑的情况下)(R)ecover:加载暂存文件的内容,用在恢复之前未保存的内容,恢复之后记得手动删除暂存文件(D)elete it:确定暂存文件是无用的,删除它(Q)uit:离开 vim,不会进行任何动作(A)bort:忽略这个编辑行为,感觉上与 quit 非常类似。
vim 额外功能
其实,目前大部分的distribution 都以 vim 取代 vi 的功能了,因为 vim 具有颜色显示、支持许多程序语法(syntax)等功能
那么怎么分辨是否当前 vi 被 vim 取代了呢?
通过 alias 分辨
1 | [mrcode@study vitest]$ alias |
通过界面分布
区块选择(Visual Block)
上面提到的简单 vi 操作过程中,几乎提到的都是以行为单位来操作的。那么如果想要搞定一个区块范围呢?如下面这个文件内容
1 | 192.168.1.1 host1.class.net |
假设想要将 host1,host2 等复制,并且加到每一行的后面,即每一行的结果变成 192.168.1.1 host1.class.net host2.class.net... 。在传统或现代的窗口型编辑器似乎不容易达到这个需求,在 vim 中可以使用 Visual Block 区块功能。当按下 v 或 V 或则 ctrl+v 时,光标移动过的地方就会开始反白,按键含义如下
| 按键 | 含义 |
|---|---|
| v | 字符选择,会将光标经过的地方反白选择 |
| V | 行选择,会将光标经过的行反白选择 |
| ctrl + v | 区块选择,可以用长方形的方式选择 |
| y | 将反白的地方复制起来 |
| d | 将反白的地方删除 |
| p | 将刚刚复制的区块,在光标所在处贴上 |
实践练习区块怎么使用
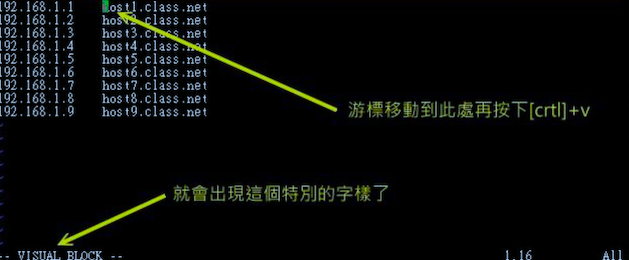

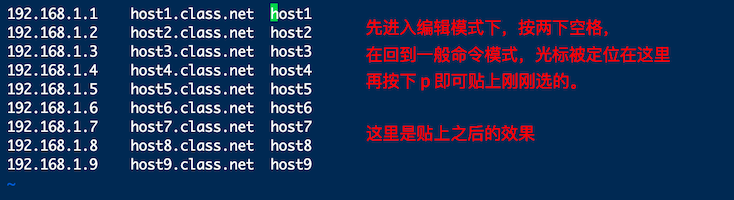
多文件编辑
想象这样一个场景:要将刚刚 host 内的 IP 复制到 /etc/hosts 这个文件去,那么该如何编辑?我们知道在 vi 内可以使用 :r filename 来读入某个文件的内容,不过是将整个文件读入,如果只想要部分内容呢?这个时候就可以使用 vim 的多文件编辑功能了。使用 vim 后面同时接好几个文件来同时开启,相关按键有
| 按键 | 含义 |
|---|---|
| :n | 编辑下一个文件 |
| :N | 编辑上一个文件 |
| :files | 列出目前这个 vim 开启的所有文件 |
没有多文件编辑的话,实现将 A 文件内的 10 条消息移动到 B 文件中,通常需要开两个 vim 窗口来复制,但是无法在 A 文件下达 nyy 再跑到 B 文件去 p 的指令。
练习多文件编辑
1 | # 开启两个文件,host 是我们刚刚编辑的那个 |
多窗口功能
在开始逐个小节前,先来想象两个情况:
- 当我有一个文件非常的大,查阅到后面的数据时,想要对照前面的数据,是否需要使用 ctrl + f 与 ctrl + b 或 pageup、pagedown 功能键来前后翻页对照?
- 我有两个需要对照看的文件,不想使用前一小节提到的多文件编辑功能
vim 有「分区窗口」的功能,在指令行模式输入 :sp filename即可,filename 存在则开启另一个文件,不存在则出现的是相同的文件内容
使用 vim /etc/man_db.conf,然后输入 「**:sp**」就会出现上下各一个窗口,两个窗口都是同一个文件内容
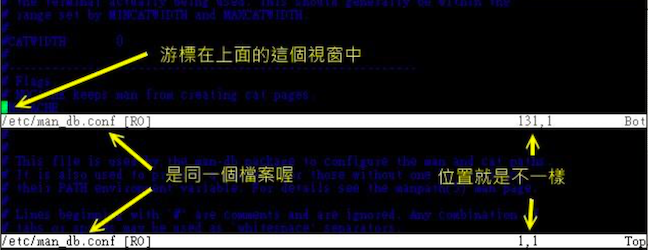
再次输入 :sp /etc/hosts 则会再分出来一个窗口

可以使用 ctrl + w + ↑ 和 ctrl + w + ↓ 组合键来切换窗口(笔者测试使用 ctrl + w 可以切换 ctrl + w + 箭头触发了宿主机的 ui 切换功能)
多窗口情况下的按键功能
| 按键 | 说明 |
|---|---|
| :sp [filename] | 开启一个新窗口,不加 filename 则默认打开当前文件,否则打开指定文件 |
| ctrl + w + j/↓ | 使用方法:先按下 ctrl 不放,再按下 w 后放开所有的按键,再按下 j 或向下的箭头键,则光标可移动到下方的窗口 |
| ctrl + w + k/上 | 同上 |
| ctrl + w + q | 就是 :q 结束离开。比如:想要结束下方的窗口,先使用 ctrl + w + j 移动到下方窗口,输入 :q 或则按下 ctrl + w + q 离开 |
vim 的挑字补全功能
我们知道在 bash 环境下可以按下 tab 按钮来达成指令、参数、文件名的补全功能,还有 windows 系统上的各种程序编辑器,如 **notepad++**,都会提供:语法检验和根据扩展名来挑字的功能。
在语法检验方面,vim 已经使用颜色来达成了,建议可以记忆的 vim 补齐功能如下:
| 组合按键 | 补齐内容 |
|---|---|
| ctrl + x -> ctrl +n | 通过目前正在编辑的这个「文件的内容文件」作为关键词,补齐; |
| ctrl + x -> ctr + f | 以当前目录内的「文件名」作为关键词,予以补齐 |
| ctrl + x -> ctrl + o | 以扩展名作为语法补充,以 vim 内置的关键词,予以补齐 |
用法:先输入关键词如 host 再按 ctrl + x,再按 ctrl + n,如果有可补齐的待选文案,会显示下拉列表给你选择
实践练习:使用 css 美化功能时,突然想到有个北京的东西要处理,但是忘记了背景 CSS 关键语法,就可以用如下的模式来处理
1 | # 一定要是 .html 否则不会使用正确的语法检验功能 |
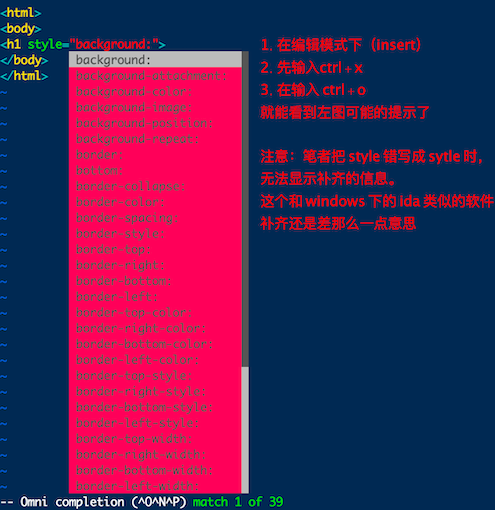
vim 环境设置与记录:~/.vimrc、~/.viminfo
有没有发现:如果以 vim 软件来搜寻一个文件内部的某个字符串时,这个字符串会被反白,而下次我们再次以 vim 编辑这个文件时,该搜索的字符串反白的情况还是存在的,甚至于在编辑其他文件时,如果也存在该字符,也会主动反白。另外,当我们重复编辑同一个文件时,当第二次进入该文件时,光标竟然在上次离开的那一行上面
这是因为 vim 会主动将你曾经做过的行为记录在 ~/.viminfo 文件中,方便你下次可以轻松作业
此外,每个 distribution 对 vim 的预设环境都不太相同,例如:某些版本在搜寻关键词时并不会高亮度反白,有些版本则会主动帮你进行缩排的行为。这些其实都可以自定设置的,vim 的环境设置参数有很多,可以在一般模式下输入「**:set all**」来查询,不过可设置的项目太多了,这里仅列出一些平时比较常用的一些简单设置值,供你参考
vim 的环境设置参数
| item | 含义 |
|---|---|
| :set nu、**:set nonu** | 设置与取消行号 |
| :set hlsearch、:set nohlsearch | hlsearch 是 high light search (高亮度搜索)。设置是否将搜索到的字符串反白设置。默认为 hlsearch |
| :set autoindent、**:set noautoindent** | 是否自动缩排?当你按下 Enter 编辑新的一行时,光标不会在行首,而是在于上一行第一个非空格符处对齐 |
| :set backup | 是否自动存储备份文件,一般是 nobackup 的,如果设置为 backup,那么当你更改任何一个文件时,则源文件会被另存一个文件名为 filename~ 的文件。如:编辑 hosts,设置 :set backup ,那么修改 hosts 时,在同目录下就会产生 hosts~ 的文件 |
| :set ruler | 右下角的状态栏说明,是否显示或不显示该状态的显示 |
| :set shwmode | 是否要显示 —INSERT– 之类的提示在左下角的状态栏 |
| :set backpace=(012) | 一般来说,如果我们按下 i 进入编辑模式后,可以利用退格键(baskpace)来删除任意字符的。但是某些 distribution 则不允许如此。此时,可以通过 backpace 来设置,值为 2 时,可以删除任意值;0 或 1 时,仅可删除刚刚输入的字符,而无法删除原本就已经存在的文字 |
| :set all | 显示目前所有的环境参数设置 |
| :syntax on 、 :syntax off | 是否依据程序相关语法显示不同颜色 |
| :set bg=dark、**:set bg=light** | 可以显示不同颜色色调,预设是 light。如果你常常发现批注的字体深蓝色是在很不容易看,就可以设置为 dark |
总之这些常用的设置非常有用处,但是在行模式下设置只是针对当前打开的 vim 有效果;想要修改默认打开就生效的话,可以修改 ~/.vimrc 这个文件来达到(如果此文件不存在,请手工创建)
1 | vi ~/.vimrc |
vim 常用指令示意图
其他 vim 使用注意事项
vim 功能很强大,但是上手不是那么容易,下面分享一些需要注意地方
中文编码的问题
在 vim 里面无法显示中文,那么你需要考虑:
- Linux 系统默认支持的语系数据,与
/etc/locale.conf有关 - 终端界面(bash)的语系;与 LANG、LC_ALL 几个参数有关
- 文件原本的编码
- 开机终端机的软件,例如在 GNOME 下的窗口
上面最重要的是第 3 和 4 点,只要这两点编码一致,就能不乱码;
可以使用如下的方式来暂时修改 tty 的语系(前面都讲过的)
1 | LANG=zh_CN.UTF-8 |
DOS 与 Linux 的断行字符
cat 命令 中讲解过 DOS(windows 系统)建立的文件的特殊格式,发现 DOS 为 ^M$,而 linux 是 $,windows 是 CR(^M) 与 LF($) 两个符号组成的,Linux 是 LF ;对于 Linux 的影响很大
在 Linux 指令开始执行的时候,判断依据是 Enter 按键(也就是换行符,回车一下就会出现换行符),由于两个系统的换行符不一致,会导致 shell script 程序文件无法执行
可以使用 dos2unix 指令来一键转换,但是目前为止,虚拟机还没有网络,无法安装,笔者这里只记录用法
1 | dos2unix [-kn] file [newfile] |
练习
1 | # 将 /etc/man_db_conf 重新复制到 /tmp/vitest 下,并将其修改为 dos 断行 |
语系编码转换
文件编码转换,可以使用 iconv 指令来做,比如下面这一段文字内容(没有网络下载不了,直接粘贴复制保存把)
1 | 每個系統管理員都應該至少要學會一種文字介面的文書處理器,以方便系統日常的管理行為。 |
1 | [root@study ~]# cd /tmp/ |
语法
1 | iconv --list |
实践练习
1 | # 查看原本文件编码,这里由于刚刚终端机是 utf-8 的,保存后就是 utf-8 了 |
认识与学习 BASH
在 Linux 环境下,如果你不懂 bash 是什么,那么其他的东西就不用学习了,所以 bash 非常重要
bash 的东西非常多:变量的设置与使用、bash 操作环境的建立、数据流重导向功能、管线命令 等
本章几乎是所有指令模式(commadn line)与未来主机维护与管理的重要基础。
认识 BASH 这个 Shell
在第一章讲到:管理整个计算机硬件的其实是操作系统的核心(kernel),一般使用者只能通过 shell 来与核心沟通。那么有系统有多少 shell 可用呢?以及为什么要使用 bash?本章告诉你答案
硬件、核心与 Shell
什么是 Shell?几乎上都听听到过,因为只要有操作通,那么就离不开 Shell 这个东西。在讨论 Shell之前,先来了解一下计算机的运作状况。举个例子:当你要计算机传输出来「音乐」的时候,你的计算机需要什么东西呢?
- 硬件:有「声卡芯片」设备,才能发声
- 核心管理:操作系统支持这个芯片组,以及提供芯片的驱动程序
- 应用程序:需要使用者(就是你)输入发生声音的指令
这就是基本的一个输出声音所需要的步骤,可以用如下图示来说明:
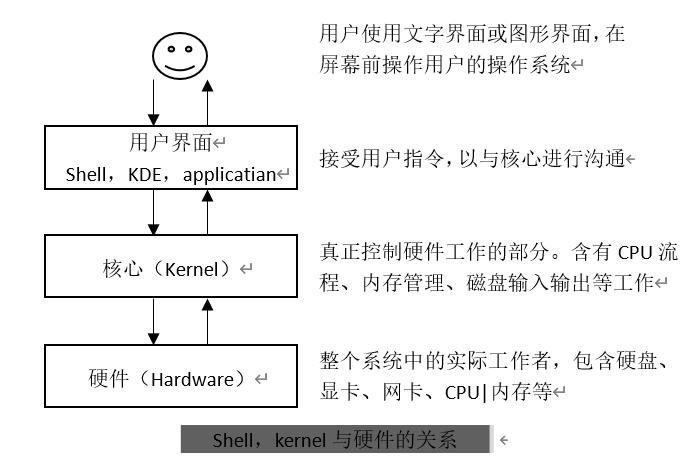
在第 0 章的操作系统章节曾提到过:操作系统其实是一组软件,控制整个硬件与管理系统的活动检测,如果这组软件能被用户随意的操作,若使用者应用不当,将会使得整个系统崩溃!所以不能随便被一些没有管理能力的终端用户随意使用
但是可以考虑使用程序来指挥核心,在第 0 章所提供的操作系统图示中,可以发现应用程序其实是在最外层,就如同鸡蛋的外壳一样,因此也就被称呼为壳程序(Shell)
其实壳程序的功能只是提供用户操作系统的一个接口,因此整个壳程序需要可以呼叫其他软件的功能,如前面提到过的很多指令,包括 man、chmod、chown、vi、fdisk、mkfs 等指令,这些指令都是独立的应用程序,但是可以通过壳程序(指令行模式)来操作这些应用程序
也就是说,只要能够操作应用程序的接口都能够成为壳程序。狭义的壳程序指的是指令方面的软件,包括本章要介绍的 bash 等。广义的壳程序包括图形界面软件。
为何要学习文字接口的 shell?
文字接口的 shell 不好学,但是学了之后好处多多,因此需要克服这个困难
文件接口的 shell:大家都一样
为什么要学习 shell?x window 下的 ui 工具点一点就可以达到目的,比如 Webmin 是真的好用,他可以帮我很建议的设置我们的主机,甚至是一些很进阶的设置都可以帮我们搞定
但是这里还是需要再强调下:x window 与 web 接口的工具,它虽然功能强大,只是把所有利用到的软件整合到一起的一组程序而已,并非一个完整的套件,所以某些当你升级或则是使用其他套件管理模块(如 tarball 而非 npm 文件等)时,就会造成设置的困扰了。甚至不同的 distribution 所设计的 x window 接口也都不相同,这样也造成学习方面的困扰
而几乎各家 distribution 使用的 bash 都是一样的,如此一来几乎上能够轻轻松松的转换不同的 distribution
远程管理:文字接口就是比较快
Linux 的管理常常需要通过远程联机,而联机时文字接口的传输速度一定比较快,而且不容易出现断线或则是信息外流的问题,因此 shell 真的是得学习的一项工具,而且会让你更深入 Linux。
Linux 的任督二脉:shell
所谓技多不压身,书到用时方恨少。此外,如果你真的有心要将你的主机管理好,那么良好的 shell 程序编写是一定需要的!
例如作者的经验来说,管理的主机不到十台,但是如果每台书籍都要花上几十分钟来查询他的登录文件信息以及相关的信息,可能会疯掉,太没有效率。但是通过 shell 提供的数据流重导向以及管线命令,分析登录信息只要花费不到十分钟就可以看完所有的主机的重要信息了
由于学习 shell 的好处真的多多,想要管理好系统的话,shell 就像是打通任督二脉一样,任何武功都能随你应用
系统的合法 shell 与 /etc/shells 功能
由于早年 Unix 年代,发展众多,所以 shell 依据发展者的不同就有许多版本,例如 Bourne SHell(sh)、在 Sun 里头预设的 CSHell、商业上常用的 K Shell、TCSH 等,每一种 Shell 都各有其特点。而 Linux 使用的这一种版本就称为「Bourne Again SHell(简称 bash),是 Bourne Shell 的增强版,也是基于 GNU 的架构下发展出来的
shell 简单历史
第一个流行的 shell 是由 Steven Bourne 发展出来的,所以称为 Bourne shell(简称 sh)。后来另一个广泛流传的 shell 是由柏克莱大学的 Bill Joy 设计依附于 BSD 版的 Unix 系统中的 shell,该 shell 语法类似 c 语言,所以才得名为 C shell(简称 csh)。 Sun 主要是 BSD 的分支之一,而且 Sun 主机势力庞大,所以 csh 流传广泛
目前 Linux 可以使用的 shells
以 CentOS 7 为例,有多少我们可以使用的 shells 可以通过检查 /etc/shells 文件,至少有以下几个
/bin/sh:已被/bin/bash所取代/bin/bash:Linux 预设的 shell/bin/tcsh:整合 C Shell 提供更多的功能/bin/csh:已被/bin/tcsh取代
虽然各家 shell 的功能都差不多,但是在某些语法下达方面则所有不同,因此建议需要选择一种 shell 来熟悉。Linux 预设就是使用的 bash,因此最初学会它就非常了不起了。
为什么系统上合法的 shell 要写入 /etc/shells 这个文件?因为系统某些服务在运行过程中,回去检查使用者能够使用的 shells
举例来说:某些 FTP 网站回去检查使用者的可用 shell,而如果你不想让这些用户使用 FTP 以外的主机资源时,可能会给予该使用者一些怪怪的 shell,让使用者无法以其他服务登录主机。这个时候,你就可以将那些怪怪的 shell 写到 /etc/shells 中。举例来说, CentOS 7 的 /etc/shells 里头就有个 /sbin/nologin 文件的存在,这个就是我们说的怪怪的 shell
我这个使用者上面时候可以取得 shell 来工作呢?还有预设会取得哪一个 shell 呢?在登录终端的时候,系统就会给一个 shell 进行工作,而这个登录取得的 shell 就记录在 /etc/passwd 文件内
1 | [mrcode@study ~]$ cat /etc/passwd |
如上所示,每一行的最后一个数据,就是你登录后可以取得的预设 shell,系统账户 bin 与 daemon 等就是使用哪个怪怪的 /sbin/nologin ,关于使用者这部分的内容,在后续 第十三章的账户管理中讲解
Bash shell 的功能
Linux 预设的 /bin/bash 是 GNU 计划中重要的工具软件之一,目前也是 Linux distribution 的标准 shell,主要兼容于 sh,并且依据一些使用者需求加强的 shell 版本。主要有点有如下几个
命令编修能力(history)
能记录使用过的指令,只要在指令列按「上下键」可以浏览历史记录,默认的指令记忆条数可达 1000 个。
指令记录在你的家目录内的 .bash_history ,该文件记录的是前一次登录以前所执行过的指令,而当前这一次的指令被暂存在内存中,当你成功注销系统后,指令记录才会存入该文件中
这种工作机制的优点:最大好处可以查询曾经做过的举动,如此可以知道你的执行步骤,那么就可以追踪你曾经下达过的指令,以作为除错的重要流程,但是如果被黑客入侵,只要翻阅你曾经执行过的指令,刚好你的指令又与系统有关(比如登录 mysql 的密码在指令列上),那么很容易数据库密码就被泄露了
那么该功能和历史记录数是好是坏?只能是仁者见仁智者见智了
命令与文件补全功能(tab 按键的好处)
在 bash 中常常使用 tab 补全功能,可以让你效率提升,并且减少输入时数据错误的几率,
- 命令补全:tab 接在一串指令的第一个字的后面
- 文件补全:tab 接在一串指令的第二个字以后时
- 若安装 bash-completion 软件,则在某些指令后面使用 tab 按键时,可以进行「选项**/**参数的补齐」功能
命令别名设置功能(alias)
假如我需要知道这个目录下的所有文件(包含隐藏文件)以及所有的文件属性,那么必须下达 ls -al这样的指令,可以通过 alias 来自定义命令取代上面的命令
1 | alias lm='ls -al' |
工作控制、前景背景控制(job control、foreground、background)
这部分在 第十六章 Linux 过程控制中详细讲解。使用前、背景可以让工作进行得更为顺利,而工作控制(jobs)用途则更广,可以让我们随时将工作丢到背景中执行,而不怕不小心使用了 ctrl + c 来停掉该程序。此外,可以在单一登录的环境中,达到多任务的目的
程序化脚本(shell scripts)
在 DOS 年代将一堆指令写在一起的批处理文件,在 Linux 下的 shell scripts 则发挥更强大的功能,可以将你平时管理系统常需要下达的连续指令写成一个文件,该文件并且可以通过对谈交互式的方式来进行主机的侦测工作。也可以借由 shell 提供的环境变量及相关指令来进行设计,以前在 DOS 下需要程序语言才能写的东西,在 Linux 下使用简单的 shell scripts 就可以实现,这部分在 第十二章 讲解
通配符(wildcard)
举例来说:想要知道 /usr/bin 下有多少以 X 开头的文件,使用ls -l /usr/bin/X* 就可以知道,此外还有其他可用的通配符
查询指令是否为 Bash shell 的内置命令:type
可以通过 man bash 查看联机帮助文档,内容很多,让你看几天几夜也无法看完,不过该 bash 的 man page 中,还有其他文件的说明,比如 cd 指令也在该 man page 内。在输入 man cd 时,最上方也出现一堆的指令介绍,这是由于方便 shell 的操作内置了这些指令
可以通过 type 指令来观察某个指令是否是内置指令
1 | type [-tpa] name |
实践练习
1 | # 查询 ls 这个指令是否为 bash 内置 |
指令的下达与快速编辑按钮
前面讲过怎么下达指令,这里仅以反斜杠来说明下指令下达方式
1 | # 如果指令串太长的话,如何使用两行来输出 |
使用 \ 来跳脱回车键,前面的 > 是跳脱模式下的标识符,还有组合按键帮助我们快速实现功能
| 组合键 | 功能与示范 |
|---|---|
ctrl + u、ctrl + k |
快速删除:分别是从光标处向前删除指令串,及向后删除指令串 |
ctrl + a、ctrl + e |
快速移动:分别是让光标移动到整个指令串的最前面和最后面 |
总之,当我们顺利的在终端机 tty 上面登录后,Linux 就会依据 /etc/passwd 文件的设置给我一个 shell(预设是 bash),可以通过 man 来查询指令的使用方式,根据上面下达指令的方式来操作 shell
Shell 的变量功能
变量是 bash 环境中非常重要的一个概念
什么是变量
简单说,某一个特定字符串代表不固定的内容;比如:y = ax+b 等号左边的是变量,右边的是变量的内容,使用简单的变量来取代另一个比较复杂或则是容易变动的数据,这样做的好处就是方便!
变数的可变性与方便性
举例来说,我们每个账户的邮件信箱预设是以 MAIL 这个变量来进行存取的,当不同的账户登录取得的变量内容如下所示
1 | dmtsai 的 MAIL = /var/spool/mail/dmtsai |
好处是则是邮件处理程序读取 MAIL 变量就能为对应的账户处理了
影响 bash 环境操作的变量
某些特定变量会影响到 bash 的环境,例如前面多次提到的 PATH 变量,它会影响指令是否能找到。
为了区别与自定义变量的不同,环境变量通常以大写字符来表示
脚本程序设计(shell script)的好帮手
写过程序的都知道,变量在程序中的重要性,比如在 shell script 中,前面几行定义变量,后面的大量逻辑处理使用变量,那么修改变量的内容,就能让后续的处理逻辑改变,达到非常方便的效果
变量的取用与设置:echo 、变量设置规则、unset
变量的取用:echo
1 | echo $variable |
关于 echo 的功能也较多,自行 man echo,这只是用来显示变量内容
1 | # 在屏幕上显示你的环境变量 HOME 与 MAIL |
变量的修改使用等号赋值
1 | [mrcode@study ~]$ echo ${myname} |
需要注意的是:每一种 shell 的语法都不相同,在 bash 中 echo 一个不存在的变量不会保存,并显示空,其他的可能就会报错了
变量的设置规则
变量与变量内容以一个「**=**」来连接
1
myname=Mrcode
等号两边不能直接接空格符号
1
myname = Mrcode # java 语法格式强迫症不要这样写
变量名称只能是英文字母与数字
变量内容若有空格可以使用双引号或单引号限定,但是以下除外
「**$**」在双引号中可以保留原本的特性
1
2var="lang is $LANG"
则使用 echo $var 则得到输出信息为:lang is utf8 等的字样「‘」在单引号内的特殊字符仅为一般字符
1
2var='lang is $LANG'
则输出信息为:lang is $LANG
可用跳脱字符「
\」把特殊字符变成一般字符1
2# 就是转义符
myname=mrcode\ Tsai # 这里将空格转义成普通字符了在一串指令的执行中,还需要使用其他额外的指令所提供的信息时,可以使用反单引号「
指令」或「**$(指令)**」1
2
3
4
5
6# 取得核心版本的设置
[mrcode@study ~]$ echo $version
[mrcode@study ~]$ version=$(uname -r); echo $version
3.10.0-1062.el7.x86_64若该变量为扩增变量内容时,则可使用如下方式累加变量
1
2
3PATH="$PATH:/home/bin"
PATH=${PATH}:/home/bin
若该变量需要再其他子程序执行,则需要以 export 来使变量变成环境变量
1
2export PATH
通常大写字符为系统默认变量,自行设定变量可以使用小写字符,方便判断(纯粹按个人风格决定)
取消变量使用 unset
1
2# 如取消 myname 的设置
unset myname
实践练习
1 | # 练习 1:设置变量 name,内容为Mrcode |
什么是子程序?像上面那样,在当前这个 shell 下,去启用另一个新的 shell,新的哪个 shell 就是子程序了。在一般的状态下,父程序的自定义变量是无法在子程序内使用的。可以通过 export 将变量变成环境变量,就可以在子程序中使用了。
至于子程序相关概念,在第十六章程序管理中讲解。
1 | # 练习 6:如何进入到你目前核心的模块目录? |
其实上面的指令可以说是做了两次动作:
- 先进行反单引号内的动作「
uname -r」,并得到核心版本 3.10.0-1062.el7.x86_64 - 在上述结果带入原指令,得到
cd /lib/modules/3.10.0-1062.el7.x86_64/kernel/
TIP
为啥推荐
${}方式?方便识别 在复杂的变量引用中,没有分割符来分割非常的不方便识别
1 | # 练习 7:取消刚刚设置的 name 变量内容 |
环境变量的功能
环境变量可以帮我打到很多功能,如:家的目录变换、提示字符的显示、执行文件搜寻的路径等,可以使用 env 与 export 来查询当前 shell 环境中有多少默认的环境变量
用 env 观察环境变量与常见环境变量说明
1 | [mrcode@study kernel]$ env |
env 是 environment 环境 的简写,上面列出来所有的环境变量,使用 export 也是一样的内容,只不过 export 还有其他额外的功能,上面这些变量的作用如下
HOME
代表用户的家目录。使用
cd 或 cd ~也能回到自己的家,这个就是取用的 HOME 变量SHELL
目前这个环境使用的 SHELL 是哪个程序,Linux 预设使用 /bin/bash
HISTSIZE:历史命令可记录的总数量
MAIL:使用 mail 指令收信时,系统会读取的邮件信箱文件(mailbox)
PATH
执行文件搜索的路径,目录与目录中间以冒号「:」分割,由于文件搜索是按 PATH 变量内的目录查询的,所以目录的顺序也很重要
LANG
语系信息,很多程序都会用到。比如,启动某些 perl 的程序语言文件,会主动分析语系数据文件,如果发现有他无法解析的编码语系,可能会产生错误
RANDOM
随机树生成器的变量,目前大多数 distribution 都会有随机数生成器,就是
/dev/random文件。可以通过该随机数文件相关的变量($RANDOM)来获取随机数值。在 BASH 环境下,该变量范围为 0~32767 之前
1 | [mrcode@study kernel]$ echo $RANDOM |
用 set 观察所有变量(含环境变量与自定义变量)
bash 不只有环境变量,还有一些与操作接口有关的变量,以及用户自己定义的变量存在。
1 | # 使用 set,除了环境变量之外,还会将其他咋 bash 内的变量都显示出来 |
一般来说,无论是否为环境变量,只要跟我们这个 shell 的操作接口有关的变量,通常都会被设置为大写字符。也就是说,基本上,在 Linux 预设的情况中,使用{大写的字母}来设置的变量一般为系统内定需要的变量。上面的变量中有如下几个比较重要
PS1 提示字符的设置
命令提示字符,当我们每次按下 Enter 键去执行某个指令后,最后要再次出现提示字符时,就会主动去读取这个变数值了。相关设置可以通过 man bash 查询 PS1 的相关说明,下面列出一些符号含义:
\d:可显示出「星期、月、日」的日期格式,如:「Mon Feb 2」\H:完整的主机名。如:本次练习机名称「study.centos.mrcode」.\h:仅取主机名第一个小数点之前的名字,如上面的则取「study」\t:显示时间,24 小时格式的 HH:MM:SS\T:显示时间,12 小时格式\A:显示时间,24 小时格式 HH:MM\@:显示时间,12 小时格式 am/pm 格式\u:目前使用者的账户名称,如 mrcode\v:BASH 的版本信息,如 4.2.46(1)-release 仅取「4.2」\w:完整的工作目录名称,由根目录写起的目录名称。但家目录会以 ~ 取代\W:利用 basename 函数取得工作目录名称,所以仅会列出最后一个目录名\#:下达的第几个指令\$:提示字符,如果是 root 时,则为#,否则就是$
预设内容为 [\u@\h \W]\$,对照上表来看,[mrcode@study ~]$ 这个为啥会显示成这样了
假设我们需要有类似如下的提示符号时,可以通过以下方式设置
1 | # [mrcode@study /home/mrcode 16:50 #12] |
?关于上个执行指令的回传值
在 bash 中该变量非常重要,表示「上一个执行的指令所回传的值」,当我们执行某些指令时,这些指令都会回传一个执行后的代码。一般来说,如果成功的执行该指令,则会回传一个 0 值,如果执行过程中发生错误,则会回传「错误代码」。简单说:非 0 则执行有错误
1 | [mrcode@study /home 02:31 #13]$ echo $SHELL |
OSTYPE、HOSTTYPE、MACHTYPE主机硬件与核心的等级
在第 0 章中谈到过 CPU 等级,个人主机的 CPU 主要分为 32/64 位,其中 32 位又分为 i386、i586、i686 ,而 64 位则称为 x86_64。由于不同等级的 CPU 指令集不太相同,因此你的软件可能会针对某些 CPU 进行优化,以取得更佳的软件性能。所以软件就有 i386 、x86_64 之分了。
要留意的是,较高阶的硬件通常会向下兼容旧的软件,但较高阶的软件可能无法在旧机器上面安装
export 自定义变量转成环境变量
evn 与 set 表示环境变量与自定义变量,他们的差异在于「该变量是否会被子程序所继续引用」。
当你登录 Linux 并取得一个 bash 之后,你的 bash 就是一个独立的程序,这个程序的识别使用的是一个称为程序标识符(PID)。接下来你再这个 bash 下下达的任何指令都是由这个 bash 所衍生出来的,那些被下达的指令就被称为子程序了。
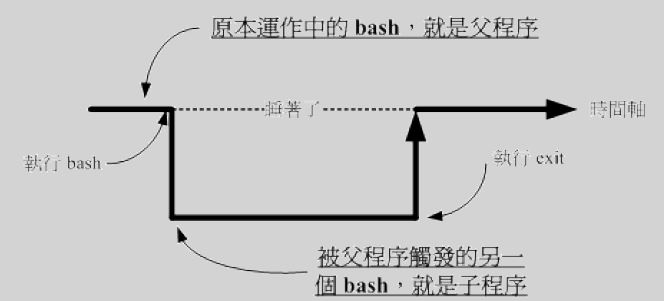
如上,在原本的 bash 下执行另一个 bash,结果操作的环境接口会跑到第二个 bash 去(就是子程序),原本的 bash 就 sleep 了。整个指令运作的环境是实线的部分!若要回到原本的 bash 去,只有将第二个 bash 结束掉(exit 或 logout)才行。更多的程序概念后续讲解
因为子程序仅会继承父程序的环境变量,子程序不会继承父程序的自定义变量;这里就会出现在这种父子切换中可能一不小心就会出现找不到变量等的情况发生
可以使用 export 将自定义变量变成环境变量,那么子程序就会继承了。
1 | export 变量名称 |
影响显示结果的语系变量 locale
笔者在使用 man 命令等指令时,mrcode 和 root 账户一个显示英文,一个显示中文,使用 locale 查询如下
1 | [mrcode@study /home 02:59 #20]$ locale |
发现一个账号是 en_US.UTF-8 一个是 zh_CN.UTF-8 ,以上可单独设置的变量有好多个,但是有 LANG 和 LC_ALL 是全局的,当其他都没有设置的时候,就会以这两个的语系为准
默认的语系配置文件在下面文件中
1 | [root@study ~]# cat /etc/locale.conf |
如果只是暂时在 tty 中显示指定的语系,而不是持久化的更改时,直接使用环境变量赋值方式
1 | [mrcode@study /home 03:09 #22]$ LANG="zh_CN.UTF-8" |
变量的有效范围
在 export 指令中就提到了这个概念,如:父子变量不会被继承,需要使用 export 导出为环境变量。
某些书籍中会谈到全局变量(global variable)与局部变量(local variable),在本章:
- 环境变量 = 全局变量
- 自定义变量=局部变量
为啥环境变量的数据可以被子程序所引用呢?是因为内存配置的关系,理论上是这样的:
- 当启动一个 shell,操作系统会分配一块内存给 shell 使用,此内存变量可让子程序取用
- 若在父程序中利用 export 功能,可以让自定义变量的内容写到上述的区块中(环境变量)
- 当加载另一个 shell 时,子 shell 可以将父 shell 的环境变量所在的区块导入自己的环境变量区块中
但是需要注意的是:这里的环境变量与「bash 的操作环境」不太一样,如 PS1 并不是环境变量,可以看成是对 bash 程序的配置
变量键盘读取、数组与宣告:read、array、declare
上述的变量都是由指令直接设置的,可以让用户使用键盘输入,如某些程序执行过程中,会等待使用者输入 yes/no 之类的信息。
read
交互式指令,阻塞等待用户输入信息。该指令在 shell script 中经常用到。关于 script 在 第十三章介绍
1 | read [-pt] variable |
实践练习
1 | # 范例 1:让用户由键盘输入一个内容,将该内容变成名为 atest 的变量 |
declare 、 typeset
declare 或 typeset 都是声明变量的类型。如果使用 declare 后面并没有接任何参数,那么 bash 会主动将所有变量名称与内容显示出来,就好像使用 set 一样。语法如下
1 | declare [-aixr] variable |
实践与练习
1 | # 范例 1 :让变量 sum 进行 100 + 300 + 50 的加总结果 |
在默认的情况下, bash 对于变量有几个基本的定义:
- 变量类型默认为字符串
- bash 环境中的数值运算,预设最多仅能达到整数形态,所以 1/3 结果是 0
1 | # 范例 2:将 sum 变成环境变量 |
declare 功能很有用,在 shell script 中经常使用。如果不小心将变量设置为「只读」,通常需要注销再登录才能复原该变量的类型
array
废话不多说,笔者是个程序员,就不记录那么低级的概念
1 | # 语法 |
实践与练习
1 | # 范例:设置 var[1] ~ var[3] 的变量 |
与文件系统及程序的限制关系:ulimit
想象一个状况:Linux 主机同时登陆了 10 个人,同时开启了 100 个文件,每个文件约 10MBytes,那么需要的内存则是 10*100*10=100000MBytes=10GBytes,耗费太多内存,系统很容易崩溃;为了预防这种情况,bash 可以「限制用户的某些系统资源」,包括可以开启的文件数量、CPU 可以使用的时间、可用内存总量等。
1 | ulimit [-SHacdfltu] [配额] |
选项与参数:
H:hard limit,严格的设定,必定不能超过这个设定的数值
S:soft limit,警告的设定,可以超过该设定值,超过则出现警告信息
在设置上,通常 soft 会比 hard 小。比如:soft=80,hard=100,那么你可以使用到 90(因为没有超过 100), 但是介于 80 ~ 100 之间,系统会有警告信息通知你
a:后面不接任何选项与参数,可列出所有的限制额度
c:限制每个核心文件的最大容量
当某些程序发生错误时,系统可能会将该程序再内存中的信息写成文件(排除用),这种文件被称为核心文件(core file)。
f:此 shell 可以建立的最大文件容量(一般可能设置为 2GB)单位为 Kbytes
d:程序可使用最大断裂内存(segment)容量
l:可用于锁定(lock)的内存量
t:可使用最大 CPU 时(单位为妙)
u:单一用户可以使用的最大程序(process)数量
实践与练习
1 | # 范例 1:列出你目前身份(假设为一般账户)的所有限制数据值 |
在第七章 Linux 磁盘文件系统中提到过,单一 filesystem 能够支持单一文件大小与 block 的大小有关系。但是文件系统的限制容量都允许太大了,可以使用 ulimit -f 来限制使用者建立的文件不要太大。
TIP
此外,ulimit 除了重新登录账户外,还可以重新设置 ulimit,但是普通用户只能降低,而不能增加文件容量,
若想要管控使用者的 ulimit 限值,可以参考第十三章的 pam 介绍
变量内容的删除、取代与替换(Optional)
除了可以设置修改原本的内容外,还可以对变量进行微调,如删除、取代、替换
变量内容的删除
下面的范例以此进行,比较能理解到这里想表达的意思
1 | # 范例 1:让小写的 path 自定义变量设置与 PATH 内容相同 |
上面的语法示意解析如下
1 | ${变量#/*local/bin;} |
1 | # 范例 3:想要删除前面所有的目录,仅保留最后一个目录 |
在 PATH 变量中的内容都是以冒号「**:」隔开的,所以要从头删除掉目录就是介于「/」到「:」之间,但是 **PATH 中不止一个冒号,所以需要以 # 与 ## 分表表示
#:符合取代文字的「最短的」那一个##:符合取代文字的「最长的」那一个
# 是由后面往前删除内容,%则是由前往后删除内容
1 | # 范例 4:假设你的 MAIL 变量是 /var/spool/mail/mrcode,只想要 mrcode 这个字符串,也就是前面的目录都不要了 |
#:从字符串头部往后匹配,匹配上则删除这一串,按最短匹配原则##:同上,按最长匹配原则%:从字符串尾部往前匹配,匹配上则删除这一串,按最短匹配原则%%:同上,按最常匹配原则
变量内容的替换
1 | # 范例 1:将 path 的变量内容内的 sbin 替换成大写的 SBIN |
\:替换首次出现的字符串为指定字符串;${path\关键字\替换成目标字符串}\\:替换所有匹配的字符串为指定字符串
变量的测试与内容替换
1 | # 范例 1: 测试 username 变量,若不存在则给定默认内容为 root |
除了以上的是否为空判定之外,还有其他的功能,总结如下
| 变量设置方式 | str 不存在 | str 为空字符串 | str 已存在且不为空字符串 |
|---|---|---|---|
var=${str-expr} |
var=expr | var= | var=$str |
var=${str:-expr} |
var=expr | var=expr | var=$str |
var=${str+expr} |
var= | var=expr | var=expr |
var=${str:+expr} |
var= | var= | var=expr |
var=${str=expr} |
str=expr; var=expr | str 不变;var= | str 不变;var=$str |
var=${str:=expr} |
str=expr; var=expr | str=expr; var=expr | str 不变;var=$str |
var=${str?expr} |
expr 输出至 stderr | var= | var=$str |
var=${str:?expr} |
expr 输出至 stderr | expr 输出至 stderr | var=$str |
总结:: 冒号都是把空字符串识别为不存在,其他的按功能如下:
-:不存在则给默认值,存在则使用原始值+:存在则给默认值,不存在不给值=:不存在则改变变量值,会影响原始变量的值;存在则使用原始值?:不存在则报错,存在则使用原始值
实践练习:
1 | # 测试:- ,str 不存在 |
这里其实还是稍微有点难以理解,没有 if else 这样看的明白,追求极致代码简洁的情况下可以使用这种方式。
命令别名与历史命令
命令别名设置:alias、unalias
命令别名就是你可以把一长串指令指定一个简短的名称,在键入指令的时候使用简短的名称来达到调用一长串指令的目的。例如:ls -al|more 查看隐藏文档并且翻页查看,觉得这串指令太长了,可以通过下面的指令来设置别名
1 | [mrcode@study ~]$ alias lm='ls -al | more' |
别名的定义规则与变量定义规则几乎相同,另外可以取代已经存在的变量名
1 | alias rm='rm -i' |
root 可以移除(rm)任何数据,所以当使用 rm 的时候需要小心,可以使用上面的别名指令覆盖掉原始的 rm 指令,执行的时候就是执行 rm -i 指令了
1 | [mrcode@study ~]$ alias |
在 root 用户下是没有 vi='vim' 的,一般用户会默认添加该别名
想取消别名可以使用 unalias 指令
1 | unalias lm |
例题:DOS 年代,列出目录与文件用 dir,清除屏幕用 cls,在 linux 如何达到这个效果?
1 | [mrcode@study ~]$ alias cls='clear' |
历史命令:history
前面提过 bash 有提供指令历史的服务,可以使用 history 来查询曾经下达过的指令
1 | history [n] |
选项与参数:
- n:数字,列出最近 n 条命令
- c:将目前的 shell 中的所有 history 内容全部消除
- a:将目前新增的 history 指令新增如 histfiles 中,若没有加 histfiles 则预设写入
~/.bash_history - r:将 histfiles 的内容读到目前这个 shell 的 history 记忆中
- w:将目前的 history 记忆内容写入 histfiles 中
实践与练习
1 | # 范例 1:列出目前内存内的所有 history 记忆 |
正常情况下历史命令的读取记录是这样的:
- 当以 bash 登录 Linux 主机后,系统会主动的由家目录的
~/.bash_history读取 - 假设这次登录后,共下达过 100 次命令,等你注销时,系统就会将 101~1100 总共 1000 条记录更新到
~/.bash_history中,因为和能存储最大条数 HISTSIZE 有关系,前面的序号会增加,但是总存储条数只有 HISTSIZE 条 - 也可以使用 history -w 强制写入
history 指令不只是提供了查询历史记录而已,还可以利用相关命令来执行指令,如下
1 | # 执行第几条命令,这里 number 是数值序号 |
虽然好用,但是需要小心安全问题,尤其是 root 的历史记录,这是黑客的最爱。另外使用 history 配合 ! 曾经使用过的指令下达是很有效率的一个指令下达方式
同一账户同时多次登录的 history 写入问题
常常会同时开几个 bash 窗口,这些 bash 的身份都是 root。这样会有 ~/.bash_history的写入问题吗?
自动写入的条件是注销 bash 时,自动写入,那么最后一个被注销的 bash 窗口中的历史记录会存下来,如果记录大于了 1000 的话,后注销的会覆盖前面先注销的(会有同时注销的情况导致错乱的吗?书上没有说)
由于多重登录有这样的问题,很多朋友都习惯单一 bash 登录,再用后续要讲解的 「工作控制 job control 来切换不同的工作」,这样才能将所有曾经下达过的指令记录下来,也方便未来系统管理员进行指令的 debug
无法记录时间
history 有一个问题就是无法记录指令下达时间。按序号记录的,但是没有记录时间。如果有兴趣,其实可以通过 ~/.bash_logout 来进行 history 的记录,并加上 date 来增加时间参数(后续的情景模拟题中会讲到怎么做)
TIP
有一种情况就是,想不要别人翻阅你的历史记录的话,可以使用 history -c;history -w 强迫清除并立即写入文件来清空历史记录
Bash Shell 的操作环境
在我们登陆主机的时候,屏幕上会有一些说明文字,告知我们的 Linux 版本之类的信息,还可以显示一些欢迎等信息。此外,我们习惯的环境变量、命令别名等,是否可以在登录后就主动帮我设置好?
这些设置又分为系统全局配置和个人账户级配置,仅是文件放置位置不同
路径与指令搜寻顺序
前面讲到过使用 alias 可以建立别名,比如创建了一个 ls 的别名,其实 ls 有少的指令,那么到底是哪一个会被选中执行呢?基本上,指令运行顺序可以这样看:
- 以相对、绝对路径执行命令,例如
/bin/ls或./ls - 由 alias 找到该指令来执行
- 由 bash 内置的指令来执行
- 通过
$PATH这个变量的顺序搜索到第一个指令执行
举例来说:
/bin/ls:该指令运行后,没有颜色ls:该指令运行后输出的内容有颜色,因为是使用别名alias ls=‘ls --color=auto’
也可以使用 type -a ls 来查询指令搜寻的顺序
1 | # 范例:设置 echo 的命令别名为 echo -n,然后观察 echo 执行的顺序 |
可以看到上面的顺序与本节总结的执行顺序一致
bash 的进站与欢迎信息:/etc/issue、/etc/motd
进站信息 /etc/issue
在 tty1~tty6 登录时,会有几行提示字符,这个就是进站画面,该字符串在 /etc/issue 中配置的
1 | [mrcode@study ~]$ cat /etc/issue |
如上的变量引用使用的是反斜杠,变量可以通过 man issue 中查看到 agetty ,再 man agetty 得到如下的信息,代码变量信息如下
\d:本地端时间的日期\l:显示第几个终端机接口\m:显示硬件的等级(i386、i486、i586…)\n:显示主机的网络名称\O:显示 domain name\r:操作系统的版本(相当于 uname -r)\t:显示本地端时间的时间\S:操作系统的名称\v:操作系统的版本
1 | # 练习:如果想在 tty3 的进站画面看到如下显示,该如何设置才能达到效果? |
怎么登录 tty 和切换 tty 请参考之前的章节,记得,进站画面是切换到 tty 时顶部显示的信息,而不是登录后显示的信息。
该文件中的规则就是使用反斜杠引用上面的变量,其他的你可以随意操作,比如写个字符画等,搞得个性一点
当使用 telnet 登录主机时,是不会显示 /etc/issue 中的配置,而是显示 /etc/issue.net 中的配置
欢迎信息 /etc/motd
想要使用者登录后,取得一些信息,例如使用注意事项信息,就可以修改 /etc/motd 文件
1 | [root@study ~]# vi /etc/motd |
bash 的环境配置文件
我们一进入 bash 就取得了一堆有用的变量,这是因为系统有一些环境配置文件的存在,让 bash 在启动时直接读取这些配置文件,以规划好 bash 的操作环境。而这些配置文件分为全局系统配置和用户个人偏好配置
login 与 non-login shell
在介绍 bash 的配置文件前,一定要先知道 login shell 与 non-login shell ,重点就在于有没有登录(login)
login shell:取得 bash 时需要完整的登录流程,就称为 login shell
举例来说,你要由 tty1~tty6 登录,需要输入用户的账户与密码,此时取得的 bash 就称为「login shell」
non-login shell:取得 bash 接口的方法不需要重复登录的举动
比如:你以 x window 登录 linux 后,再以 X 的图形化接口启动终端机,此时该终端机并没有再次输入账户与密码,那么该 bash 的环境就称为 non-login shell
再比如:你再原本的 bash 环境下再次下达 bash 这个指令,同样也没有输入账户密码,那第二个 bash(子程序)也是 non-login shell
上面两种情况取得的 bash 配置文件不一致。由于我们需要登录系统,所以先谈谈 login shell 会读取哪些配置文件?一般来说,login shell 其实只会读取这两个配置文件
- /etc/profile:系统整体配置,最好不要修改这个文件
~/.bash_profile或~/.bash_login或~/.profile:属于使用者个人设置
/etc/profile (login shell 才会读)
该文件相对于现在我们来看,可能还不太能看得懂,里面是利用使用者的标识符(UID)来决定很多重要的变量数据,这也是 每个使用者登录取得 bash 时一定会读取的配置文件 ,也就是系统级全局配置,主要变量如下:
- PATH:会依据 UID 决定 PATH 变量要不要含有 sbin 的系统指令目录
- MAIL:依据账户设置好使用者的 mailbox 到 **/var/spool/mail/**账号名
- USER:根据用户的账户设置该变量类容
- HOSTANME:依据主机的 hostname 指令决定此变量内容
- HISTSIZE:历史命令记录数量。CentOS 7.x 设置为 1000
- umask:包括 root 默认为 022 而一般用户为 002 等
/etc/profile 可不止会做这些事情,还会呼叫外部的设置数据,在 CentOS 7.x 默认情况下,下面的数据会依序被呼叫进来:
*/etc/profile.d/.sh**
通配符方式,加载该目录内所有的 sh 文件,另外,使用者需要具有 r 的权限,那么该文件就会被 /etc/profile 调用。
在 CentOS 7.x 中,该目录下的文件规范了 bash 操作窗口的颜色、语系、ll 与 ls 指令的命令别名、vi 的命令别名、which 的命令别名等。如果你需要帮所有使用者设置一些共享的命令别名时,可以在该目录下自行建立后缀为 .sh 的文件,并将所需要的数据加入即可
/etc/local.conf
该文件是由 /etc/profile.d/lang.sh 呼叫进来的,这也是我们决定 bash 预设使用何种语系的重要配置文件!文件里最重要的就是 LANG、LC_ALL 这些变量的设置,前面讨论过
*/usr/share/bash-completion/completions/**
tab 键补全,除了命令补齐、文档名补齐外,还可以进行指令的选项、参数补齐功能。就是从这个目录里面找到对应的指令来处理的。
该目录下的内容是由 /etc/profile.d/bash_completion.sh 文件载入的
~/.bash_profile (login shell 才会读)
bash 在读完了整体环境设置的 /etc/profile ,并借此加载其他配置文件后,接下来则是会读取使用者的个人配置文件。在 login shell 的 bash 环境中,所读取的个人偏好配置文件其实主要有 3 个,依序分别是:
~/.bash_profile~/bash_login~/,profile
其实 bash 的 login shell 设置只会读取上面三个文件中的一个,而读取的顺序则是依照上面的顺序。
什么意思呢?是当第一个文件不存在时,读取第二个,那么当第一个文件存在时,后面的都不读取了
为什么会有这么多的文件?是因为其他 shell 转换过来的使用者习惯不同,而做的兼容。
1 | # 看看 mrcode 的 .bash_profile 的内容 |
该文件设置了 PATH,并使用 export 将 PATH 变成环境变量,看配置是通过累加方式将用户家目录下的 ~/bin/ 目录添加进 PATH 了,这就意味着,你可以将可执行文件放到 ~/bin/ 下,执行时,就不需要写全路径了
上面的文件内容中有一段 if…then… 代码,该代码后续再 shell sript 中讲解,这里判断 ~/.bashrc 文件是否存在,存在则加载。
bash 配置文件的读入方式是通过 source 指令来读取的。这个后续讲解,最后来看看整个 login shell 的读取流程
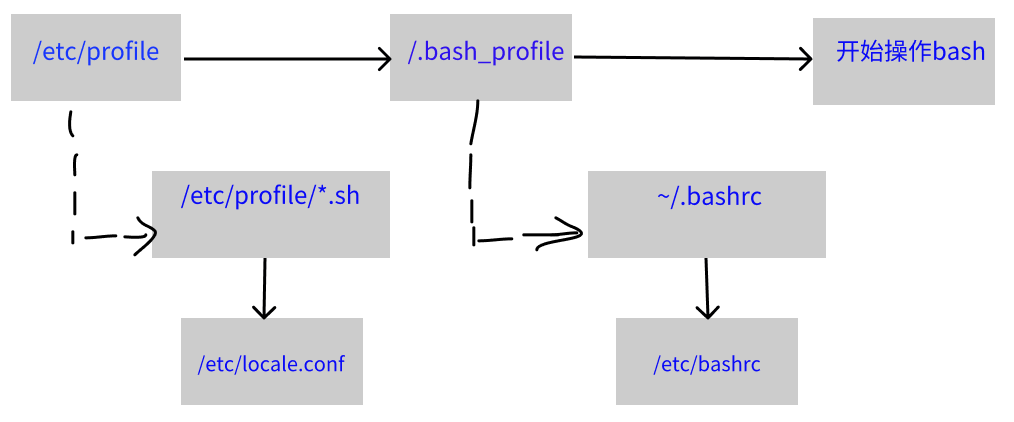
实线的方向是主线流程,虚线的方向则是被加载的配置文件。从上图来看,CentOS 的 login shell 环境下,最终被读取的配置文件是 ~/.bashrc 文件,所以可以将自己的偏好设置写入该文件即可。
下面还要讨论 source 与 ~/.bashrc
source : 读取环境配置文件的指令
由于 /etc/profile 与 ~/.bash_profile 都是在取得 login shell 的时候才会读取的配置文件,所以将自己的偏好设置写入上述文件后,通常都是需要注销后再登录,才会生效。可以使用 source 指令达到立即生效。
1 | source 配置文件名 |
1 | # 范例:将 家目录的 ~/.bashrc 的设置读入目前的 bash 环境中 |
source 还可以用于不同环境配置文件的场景中,比如,我的工作环境分为 3 个,那么需要分别编写属于 3 个项目的环境变量配置文件,当需要该环境时,直接使用 source 加载进来
~/.bashrc (non-login shell 会读)
在非登录情况下取得 bash 环境配置文件时,仅会读取 ~/.bashrc 文件
1 | [mrcode@study ~]$ cat ~/.bashrc |
注意看,不同身份账户不同,这也解释了个人偏好配置文件是什么
1 | [root@study ~]# cat ~/.bashrc |
CentOS 7.x 中为什么会主动加载 /etc/bashrc 文件呢?是因为 /etc/bashrc 帮我们的 bash 定义出下面的数据:
- 依据不同的 UID 规范出 umask 的值
- 依据不同的 UID 规范出提示字符(就是
PS1变量) - 加载
/etc/profile.d/*.sh的设置
需要注意的是,**/etc/bashrc** 是 CentOS 特有的(Red Hat 系统),其他的 distribution 可能不是该名称。由于 ~/.bashrc会加载 /etc/bashrc 和 /etc/profile.d/*.sh 所以,当你不小心删除了 ~/.bashrc 那么这些都不能读取了,你的 bash 提示字符可能就变成下面这个样子了
1 | -bash-4.2$ |
原因是,没有加载 /etc/bashrc 来规范 PS1 d的变量,这种情况也不会影响你的 bash 使用。可以复制 /etc/skel/.bashrc 文件复制到 ~/.bashrc ,恢复回来
其他相关配置文件
事实上还有一些配置文件可能会影响到你的 bash 操作
/etc/man_db.conf
该文件对于系统管理员来说,是一个很重要的文件,它规范了使用 man 时, man page 的路径到哪里去寻找。
如果你是以 tarball 的方式来安装你的数据库,那么你的 man page 可能会放置在 /usr/local/softpackage/man 中,softpackage 是套件的名称,这个时候就需要手动将该路径加到 /etc/man_db.conf 中。否则 man 就会找不到相关的说明文档
~/bash_history
在讲解「历史命令」时提到过该文件,预设情况下,历史命令就记录在该文件中。每次登陆 bash 后,bash 会先读取这个文件,将所有的历史指令读入内存,因此,当我们登陆 bash 后就可以查知上次使用过哪些指令
~/.bash_logout
该文件则记录了:当我注销 bash 后,系统再帮我做完师门动作后才离开的意思。你可以读取下该文件的内容,预设情况下,注销时,bash 只是帮我们清掉屏幕的信息而已。
不过,你也可以将一些备份或则是其他你认为重要的工作写在这个文件中(如:清空暂存盘)
终端机的环境设置:stty、set
前面讲解过可以在 tty1~tty6 这 6 个文字终端机(terminal)环境中登录,登录的时候可以取得一些字符设置的功能。比如
- 使用退格键(删除键)来删除命令行上的字符
- ctrl + c 来强制终止一个指令的执行
- 当时呼入错误时,会有声音跑出来警告
以上功能都是在登录终端机时,自动获取终端机的输入环境设置实现的
事实上,目前我们使用的 Linux distributions 都帮我们制作了最棒的使用者环境了,但是在某些 Unix like 机器中,还是可能需要手动修改配置
1 | # setting tty |
1 | # 范例 1 :列出所有的按键与按键内容 |
下面是几个重要的含义:
- intr:送出一个 interrupt 中断信号给目前正在 run 的程序
- quit:送出一个 quit 信号给目前正在 run 的程序
- erase:向后删除字符
- kill:删除在目前指令列上的所有文字
- eof:End of file 的意思,代表「结束输入」
- start:在某个程序停止后,重新启动它的 output
- stop:停止目前屏幕的输出
- susp:送出一个 terminal stop 的喜好给正在 run 的程序
比如要设置 ctrl + h 来进行字符的删除
1 | stty erase ^h |
1 | 错误操作问题:在 windows 下 ctrl + s 是保存功能,在 Linux 使用 vim 时,使用 ctrl + s 整个画面死锁,不能动了,是什么原因? |
除了 stty 之外,bash 还有自己的一些终端机设置
1 | set [-uvCHhmBx] |
选项与参数:
- u:预设不启用。若启用后,当使用未设置变量时,会显示错误信息
- v:预设不启用。若启用后,在信息被输出前,会先显示信息的原始内容
- x:预设不启用。若启用后,在指令被执行前,会显示指令内容(前面有 ++ 符号)
- h:预设启用。与历史命令有关
- H:预设启用。与历史命令有关
- m:预设启用。与工作管理有关
- B:预设启用。与括号
[]的作用有关 - C:预设不启用。若使用 > 等,则若文件存在时,该文件不会被覆盖
1 | # 范例 1: 显示目前所有的 set 设置 |
另外,还有其他的按键设置功能,前一小节提到的 /etc/inputrc 这个文件里面设置。还有例如 /etc/DIR_COLORS* 与 /usr/share/terminfo/* 等,也都是与终端机有关的环境配置文件。但是这里不建议修改 tty 的环境,因为 bash 的环境以及设置的很亲和了。
bash 默认的组合键汇总如下
| 组合按键 | 功能 |
|---|---|
| ctrl + c | 终止目前的命令 |
| ctrl + D | 输入结束(EOF),例如邮件结束的时候 |
| ctrl + M | Enter |
| ctrl + S | 暂停屏幕的输出 |
| ctrl + Q | 恢复屏幕的输出 |
| ctrl + U | 在提示字符下,将整列命令删除 |
| ctrl + Z | 暂停 目前的命令 |
通配符与特殊符号
在 bash 操作环境中,通配符(wildcard)是非常有用的,利用 bash 处理数据就更方便了。下面是一些常用的通配符:
| 符号 | 含义 |
|---|---|
* |
代表「0 个到无穷多个」任意字符 |
? |
代表「一定有一个」任意字符 |
[] |
代表「一定由一个在括号内」的字符(非任意字符)。例如[abcd] 则表示一定由一个字符,可能是 a、b、c、d 中的任意一个 |
[-] |
若有减号在括号中时,表示「在编码顺序内的所有字符」。例如[0-9],表示 0~9 之前所有数字 |
[^] |
若括号中的第一个字符为指数符号 ^,表示反向旋转,例如[^abc],表示不包含 a、b、c |
实践练习
1 | # 范例 1:找出 /etc 下一 cron 开头的文件名 |
除了通配符外,bash 环境中的特殊符号还有以下项,这里进行整理:
| 符号 | 含义 |
|---|---|
# |
批注、注释符号 |
\ |
跳脱符号、转义符号 |
| ` | ` |
; |
连续指令下达分隔符:连续性命令的节点。与管线命令不相同 |
~ |
用户的家目录 |
$ |
取用变量前导符 |
& |
工作控制(job control):将指令变成背景下工作 |
! |
逻辑运算意义上的「非」not 的意思 |
/ |
目录符号:路径分割的符号 |
>、>> |
数据流重导向:输出导向,分别是「覆盖」和「追加」 |
<、<< |
数据流重导想:输入导向(下个章节讲解) |
'' |
单引号,不具有变量替换功能,**$** 变为纯文本 |
"" |
双引号,具有变量替换功能,**$** 可保留相关功能 |
| `` | 两个 「」中间为可以先执行的指令,也可以使用 $()` |
() |
在中间为 子 shell 的起始与结束 |
{} |
在中间为命令区块的组合 |
以上是 bash 环境中常见的特殊符号整理,理论上,文件名尽量不要使用上述字符
数据流重导向
数据流重导向(redirect),将数据传导到其他地方去,将某个指令执行后应该要出现在屏幕上的数据,给传输到其他的地方。
例如文件或则是装置(打印机之类的),数据流重导向在 Linux 的文本模式下很重要,尤其是想要将某些数据存储下来时,就更有用了
什么是数据流重导向?

执行一个指令时,这个指令可能会由文件读入资料,经过处理之后,再将数据输出到屏幕上。
- standard output:标准输出 STDOUT
- standard error output:标准错误输出 STDERR
standard output 与 standard error output
可以简单理解为:
- 标准输出:指令执行所回传的正确的信息
- 标准错误输出:指令执行失败后,所回传的错误信息
比如,我们的系统默认有 /etc/crontab 但无 /etc/mrcode ,此时若下达 cat /etc/crontab /etc/mrcode 指令时,cat 会执行:
- 标准输出:读取 /etc/crontab 后,将该文件内容显示到屏幕上
- 标准错误输出:因为无法找到 /etc/mrcode ,因此在屏幕上显示错误信息
可见不管正确或错误信息都输出到屏幕上,那么可以通过数据流重导向将 stdout 与 stderr 分别传送到其他文件或装置去,就达到了分别输出的目的,语法如下:
- 标准输入(stdin 简写):代码为 0,使用
<或<< - 标准输出(stdout):代码为 1,使用
>或>> - 标准错误输出(stderr):代码为 2,使用
2>或2>>
为了理解 stdout 与 stderr,下面进行练习
1 | # 范例 1:观察你的系统根目录 / 下各目录的文件名、权限与属性,并记录下来 |
上面的指令流程:
- 该文件若不存在,系统会自动创建文件
- 该文件若存在,那么会清空内容,再写入数据
标准输出和标准错误输出,单个符号是覆盖数据,2 个符号的是追加数据;
1 | # 范例 2:利用一般身份账户查找 /home 下是否有 .bashrc 的文件存在 |
/dev/null 垃圾桶黑洞装置的特殊写法
就是可以将任何信息吃掉的黑洞装置
1 | # 范例 4:将错误的数据丢弃,屏幕上显示正确的数据 |
那么能否将正确和错误的数据都写到同一个文件呢?需要特殊的写法才行
1 | # 范例 5:将指令的数据全部写入 list 文件中 |
standard input :< 与<<
简单来说:将原本需要由键盘输入的数据,该由文件内容来代替。
1 | # 范例 6:利用 cat 指令来建立一个文件的简单流程 |
上面使用 cat > catfile ,使用了数据流重导向,catfile 文件会被建立,内容是需要键盘输入,也就是上面的两行内容。这里可以使用标准输入来取代键盘的敲击
1 | # 范例 7:用 stdin 代替键盘输入,建立新文件的简单流程 |
而 << 表示接受的输入字符。比如:我要用 cat 直接将输入的信息输出到 catfile 中,且当由键盘输入 eof 时,该次输入就结束
1 | [mrcode@study ~]$ cat > catfile << 'eof' |
<<可以代替快捷键 ctrl + d,来终止输入,那为什么要使用命令输出重导向呢?
- 屏幕输出的信息很重要,而且我们需要将它存下来的时候
- 背景执行的程序,不希望他干扰屏幕正常的输出结果的时候
- 一些系统的例行命令(例如在 /etc/crontab 中的文件)的执行结果,希望他可以存下来时
- 一些执行命令可能已知错误信息时,想以
2>/dev/null丢弃时 - 错误信息与正确信息需要分别输出时
当然还有其他的使用场景,最简单的就是网友们经常问到:为何我的 root 都会受到系统 crontab 寄来的错误信息呢?这个是场景的错误,而如果我们已经知道这个错误信息是可以忽略的时,2> errorfile 这个功能就很重要了吧
1 | # 问:假设要将 echo `error message` 以 standard error output 的格式来输出,怎么做? |
命令执行的判断依据:;、&&、||
很多指令想要一次输入去执行,而不想分此执行,基本上有两种方法:
- 第十二章要介绍的 shell script 脚本执行
- 通过本章的知识点来完成
cmd;cmd 不考虑指令相关性的连续指令下达
比如子关机的时候希望可以执行两次 sync 同步写入磁盘后,再 shutdown 计算机
1 | sync; sync; shutdown -h now |
这个是两个指令之前没有关系的执行,前一个执行完成后,就执行后一个;如果是这样的情况:在某个目录下创建文件,如果目录存在,则创建文件,如果不存在则不做任何操作,该指令就无法完成了
$?(指令回传值)与 && 和 ||
前面章节讲到过指令回传值:若前一个指令执行的结果为正确,在 Linux 下会回传一个 $?=0 的值。可以通过判断这个值来是否执行后面的指令
逻辑操作符这里就不过多解释了
&&:前一个执行正确,后面才会执行||:前一个执行正确,后面的不会执行
1 | # 范例 1:使用 ls 查阅 目录 /tmp/abc 是否存在,若存在则用 touch 建立 /tmp/abc/hehe |
范例三,对于的表达式对于 java 或则 js 来说,理解不太一样,如下分析:
- 第一种情况:**/tmp/abc** 不存在
- ls /tmp/abc 回传
$?≠0,结果为 false - 则执行创建操作,由于会成功,故
$?=0,结果为 true - 则执行创建 hehe 文件
- ls /tmp/abc 回传
- 第二种情况:**/tmp/abc** 存在
- ls /tmp/abc 回传
$?=0,结果为 true ||遇到 true 后面的不会执行,但是 结果会往后传递- 前一个结果为 true,那么就执行创建
- ls /tmp/abc 回传
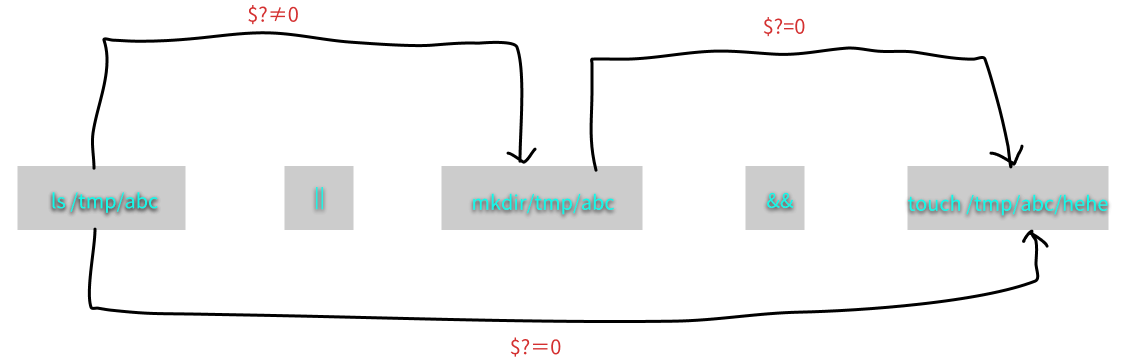
只要注意:linux 指令是从左往右执行的,只有相邻的指令会被特殊符号阻断
1 | ## 例题:以 ls 测试 /tmp/mrcode 是否存在,存在则显示 exist, 不存在则显示 not exist |
只要注意:linux 指令是从左往右执行的,只有相邻的指令会被特殊符号阻断
1 | ## 例题:以 ls 测试 /tmp/mrcode 是否存在,存在则显示 exist, 不存在则显示 not exist |
管线命令(pipe)
bash 命令执行的时候有输出数据,如果这群数据必须经过几道手续之后才能得到我们想要的格式,这就可以使用管线命令(pipe)来完成了
假设我们想知道 /etc/ 下有多少文件,可以使用 ls /etc/ 来查询,不过因为文件太多了,输出占满整个屏幕,导致最开始是什么文件看不到了,这就可以通过管线命令结合 less 指令来达成
1 | [mrcode@study ~]$ ls -al | less |
如此一来, ls -al 指令输出后的内容,能够被 less 读取,并且利用 less 的功能,可以前后翻动相关信息
管线命令仅能处理由前一个指令传来的正确信息(standard output),对于 standard error 没有直接处理的能力,整体管线命令可以使用下图表示
在每个管线后面接的第一个数据必定是「指令」,而且这个指令必须能接受 standard input 的数据才可以,这样的指令则是「管线命令」,例如 less、more、head、tail 等都是可以接受 standard input 的管线命令。而 ls、cp、mv 等就不是管线命令了,因为他们不不会接受来自 stdin 的数据。管线命令主要有两个比较需要注意的地方:
- 管线命令仅会处理 standard output ,对于 standard error output 会忽略
- 管线命令必须要能接受来自前一个指令的数据成为 standard input 继续处理才行
如果硬要 standard error 可以被管线命令所使用可以使用如下方式
那么下面来玩一些管线命令,以下知识点对系统管理费用有用
截取命令 cut、grep
简单说:将一段时间经过分析后,取出我们想要的。或则是经过由分析关键词,取得我们所想要的那一行。一般来说,截取信息通常是针对一行一行来分析的。
cut
1 | cut -d '分割字符' -f fields # 用于有特定分割字符 |
选项与参数:
- d:后面接分割字符。与
-f一起使用 - f:依据 -d 的分割字符将一段信息分区成数段,用 -f 取出第几段的意思
- c:以字符(characters)的单位取出固定字符区间
1 | # 范例 1:将 PATH 变量取出,我要找出第 5 个路径 |
cut 主要的用途:将同一行里面的数据进行分解
常使用在分析一些数据或文字数据的时候,因为有时候会以某些字符当做分区的参数,然后将数据切割,以取得我们所需要的数据,作者常常在分析 log 文件的时候,但是 cut 在处理多空格相连的数据时,就比较麻烦,所以某些常见可能需要使用下一章节要讲解的 awk 来取代
grep
cut 是将一行信息中,取出某部分我们想要的数据,而 grep 则是分析一堆信息,若一行当中有匹配的数据,则将这一行数据拿出来
1 | grep [-acinv] [--color=auto] '搜索的字符串' filename |
选项与参数:
- a:将 binary 文件以 text 文件的方式搜索数据
- c:计算找到「搜索字符」的次数
- i:忽略大小写
- n:输出行号
- v:反向选择,显示出没有搜索字符串的那一行数据
--color:可以将找到的关键词部分加上颜色显示
1 | # 范例 1:将 last 中,有出现 root 的那一行找出来 |
grep 支持的语法很多,用在正规表示法里,能够处理的数据太多。但是这里先不了解正规表示法,下一章再来讲解
这里只需要了解下,grep 可以解析一行文字,取得关键词,若改行有存在关键词,就会整行取出来
排序命令:sort、wc、uniq
sort
可以依据不同的数据形态来排序。例如数字与文字的排序不一样,另外,排序的字符与语系的编码有关,因此,如果需要排序时,建议使用 LANG=C 来让语系统一,数据排序比较好一些
1 | sort [-fbMnrtuk] [file or stdin] |
选项与参数:
- f:忽略大小写的差异
- b:忽略最前面的空格符
- M:以月份的名字来排序,例如 JAN、DEC 等排序方法
- n:使用纯数字进行排序,默认是以文字形态来排序
- r:反向排序
- u:uniq,相同的数据中,仅出现一行代表,也就是去重
- t:分隔符,预设使用 「tab」来分割
- k:以那个区间(field)来进行排序
1 | # 范例 1:个人账户都记录在 /etc/passwd 下,将账户进行排序 |
uniq
1 | uniq [-ic] |
实践练习
1 | # 范例 1: 使用 last 将账户列出,仅取出账户,排序后去重 |
wc
wc 可以计算输出的信息。比如:/etc/man_db.conf 这个文件里面有多少字?多少行?
1 | wc [-lwm] |
1 | # 范例 1:/etc/man_db.conf 这个文件里面有多少字 |
双向重导向:tee
前一节讲解到 > 会将数据流整个栓送给文件或装置,因此除非去读取该文件或装置,那么如果想要将整个暑假流的处理过程中将某段信息存下来该怎么做?就可以使用 tree
1 | Standard input ------> tee --------> Screen |
tee 会同时将数据流分送到文件与屏幕,而输出到屏幕的其实就是 stdout,那么就可以让指令继续处理
1 | tee [-a] file |
1 | # 将 last 内容输出到 last.list 文件中,并继续处理 |
字符转换命令:tr、col、join、paste、expand
在 vim 程序编辑器中提到过 DOS 换行符与 Unix 不一样,并且可以使用 dos2unix 与 unix2dos 来完成转换。
那么思考下,是否还有其他的字符转换命令,比如:将大写改成小写、将数据中的 tab 转成空格、如何将两篇信息整合成一篇?
tr:正则替换或删除字符
tr 可以用来删除一段信息中的文字,或则是进行文字信息的替换
1 | tr [-ds] SET1 ... |
1 | # 范例 1:将 last 输出的信息中,原有的小写变成大写字符 |
该指令也可以写在正规表示法里面,因为他也是由正规表示法的方式来取代数据的,比如上面使用 [] 来设置字符,通常用来取代文件中的怪异符号。
col:将 tab 转换成对等的空格
1 | col [-xb] |
1 | # 范例 : 利用 cat -A 显示出所有的特殊按键,最后以 col 将 tab 转成空白 |
虽然 col 有特殊的用途,但是很多时候可以用来简单的将 tab 取代为空格键,并且可以取代会对等宽度的空格
join:合并两个文件中相同行的数据
1 | join [-ti12] file1 file2 |
选项与参数:
- t:join 默认以空格符分割数据,并且比对「第一个字段」的数据,如果两个文件相同,则将两笔数据连城一行,且第一个字段放在第一个
- i:忽略大小写
- 1:数值 1,代表「第一个文件要用哪个字段来分析」
- 2:数值 2,代表「第二个文件要用哪个字段来分析」
1 | # 范例 1:用 root 身份,将 /etc/passwd 与 /etc/shadow 相关数据整合成一栏 |
paste:将两行贴在一起
将两行贴在一起,且中间以 tab 隔开
1 | paste [-d] file1 file2 |
1 | # 范例 1:用 root 身份,将 /etc/passwd 与 /etc/shadow 同一行贴在一起 |
expand:将 tab 转成空格
1 | expand [-t] file |
1 | # 范例 1:将 /etc/man_db.conf 内行首为 MANPATH 的字样取出,仅取前三行 |
有一个需要特别注意:tab 最大功能就是格式排列整齐,但是换成空格之后,就不一定是排列整齐的了,也可以参考一下 unexpand 这个将空白转成 tab 的指令
1 | [root@study ~]# grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 6 | unexpand -t 6 | cat -A |
分区命令:split
split 可以分割文件,按文件大小或行数来分割
1 | split [-bl] file PREFIX |
1 | # 范例 1:/etc/services 有 600 多 k,若想要分成 300k 一个文件 |
参数代换:xargs
产生某个指令的参数。xargs 可以读入 stdin 的数据,并且以空格符或换行符号作为分辨,将 stdin 的数据分割成为 arguments。
1 | xargs [-0epn] command |
- 0:数值 0,如果输入的 stdin 含有特殊字符,例如 `、\、空格等时,可以将他转义为一个普通字符
- e:EOF(end of file)。后面可以接一个字符串,当 xargs 分析到这个字符串时,会停止继续工作;注意:
-e'sync'选项与后面的 eof 字符中间没有空格 - p:在执行每个指令的 argument 时,都会询问使用者
- n:后面接次数,每次 command 指令执行时,要使用几个参数
当 xargs 后面没有接任何指令时,默认是以 echo 来进行输出的
实践练习
1 | # 范例 1:将 /etc/passwd 内第一栏取出,仅取三行,使用 id 这个指令将每个账户内容秀出来 |
xargs 是一个非常好用的指令,一般使用它的原因是,很多指令其实并不支持管线命令,因此可以通过 xargs 来提供该指令引用 standard input 。如果还不太明白,下面在来看一个例子
1 | # 范例 4:找出 /usr/sbin 下具有特殊权限的文件名,并使用 ls -l 列出详细属性 |
关于减号 - 的用途
管线命令在 bash 的连续的处理程序中是相当重要的。另外,在 log file 的分析中也是很重要的一环。
另外,在管线命令中,常常会使用到前一个指令的 stdout 作为这次的 stdin,某些指令需要用到文件名(例如 tar)来进行处理时,该 stdin 与 stdout 可以利用减号 -来替代
1 | # 将 /home 里的文件打包,但打包的数据不是记录到文件,而是传送到 stdout |