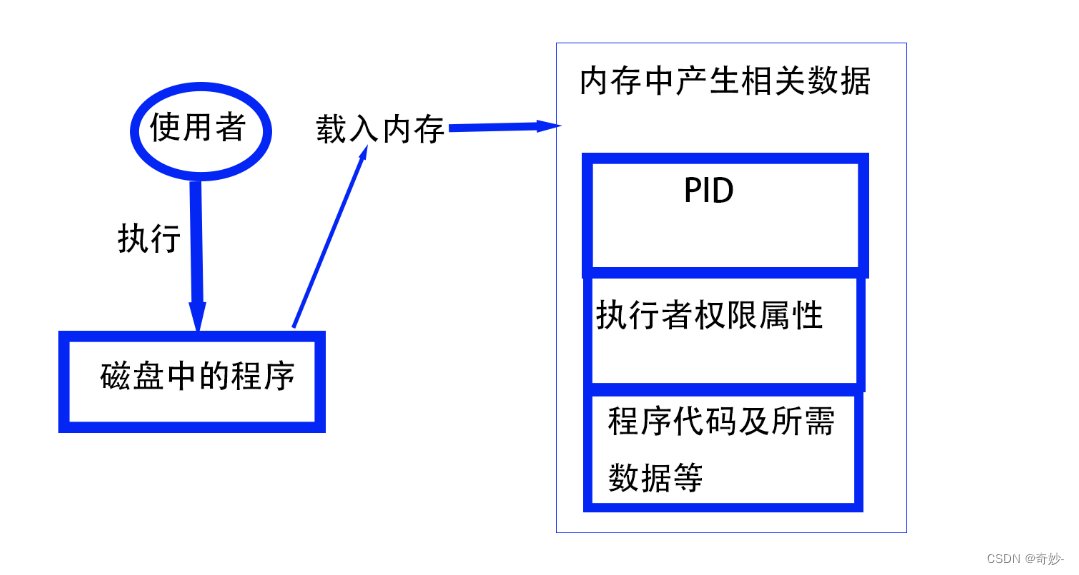
"Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. However, this dress is about $ 3183 dollars. GNU is free air not free beer. Her hair is very beauty. I can't finish the test. Oh! The soup taste good. motorcycle is cheap than car. This window is clear. the symbol '*' is represented as start. Oh! My god! The gd software is a library for drafting programs. You are the best is mean you are the no. 1. The world <Happy> is the same with "glad". I like dog. google is the best tools for search keyword. goooooogle yes! go! go! Let's go. # I am VBird
范例 1:搜索特定字符
从文件中取得 the 这个特定字符串,最简单的方式如下
1 2 3 4 5 6
[mrcode@study tmp]$ grep -n 'the' regular_express.txt 8:I can't finish the test. 12:the symbol '*' is represented as start. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 18:google is the best tools for search keyword.
反向选择,可以看到输出结果少了上面的 8、12、15、16、18 行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
[mrcode@study tmp]$ grep -vn 'the' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 5:However, this dress is about $ 3183 dollars. 6:GNU is free air not free beer. 7:Her hair is very beauty. 9:Oh! The soup taste good. 10:motorcycle is cheap than car. 11:This window is clear. 13:Oh! My god! 14:The gd software is a library for drafting programs. 17:I like dog. 19:goooooogle yes! 20:go! go! Let's go. 21:# I am VBird 22:
忽略大小写 ,多出来几行
1 2 3 4 5 6 7 8
[mrcode@study tmp]$ grep -in'the' regular_express.txt 8:I can't finish the test. 9:Oh! The soup taste good. 12:the symbol '*' is represented as start. 14:The gd software is a library for drafting programs. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 18:google is the best tools for search keyword.
范例 2:利用中括号[]来搜索集合字符
如果要搜索 test 或 taste 这两个单词时,可以发现他们其实有共同的 t?st 存在
1 2 3
[mrcode@study tmp]$ grep -n 't[ae]st' regular_express.txt 8:I can't finish the test. 9:Oh! The soup taste good.
中括号中,无论几个字符都表示任意一个字符。如果想要搜索到所有 oo 字符时
1 2 3 4 5 6 7
[mrcode@study tmp]$ grep -n 'oo' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes!
如果不想要 oo 前面的 g 呢?
1 2 3 4 5
[mrcode@study tmp]$ grep -n '[^g]oo' regular_express.txt 2:apple is my favorite food. 3:Football game is not use feet only. 18:google is the best tools for search keyword. 19:goooooogle yes!
# 由于小写字符的 ASCII 编码顺序是连续的,所以可以简化为,否则就需要把 a-z 都写出来 [mrcode@study tmp]$ grep -n '[^a-z]oo' regular_express.txt 3:Football game is not use feet only.
# 取得有数字那一行 [mrcode@study tmp]$ grep -n '[0-9]' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1.
[mrcode@study tmp]$ grep -n '[^[:lower:]]oo' regular_express.txt 3:Football game is not use feet only.
[mrcode@study tmp]$ grep -n '[[:digit:]]' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1.
# 只要行首是 the 的 [mrcode@study tmp]$ grep -n '^the' regular_express.txt 12:the symbol '*' is represented as start.
# 想要行首是小写字符开头的 [mrcode@study tmp]$ grep -n '^[a-z]' regular_express.txt 2:apple is my favorite food. 4:this dress doesn't fit me. 10:motorcycle is cheap than car. 12:the symbol '*' is represented as start. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. # 下面的等效 # [mrcode@study tmp]$ grep -n '^[[:lower:]]' regular_express.txt
# 不要英文字母开头的 # ^ 在中括号内表示反选,在外表示定位首航 [mrcode@study tmp]$ grep -n '^[^a-zA-Z]' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 21:# I am VBird
# 找出行尾为 . 符号的数据 # 使用 \ 对 小数点转义 [mrcode@study tmp]$ grep -n '\.$' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 5:However, this dress is about $ 3183 dollars. 6:GNU is free air not free beer. 7:Her hair is very beauty. 8:I can't finish the test. 9:Oh! The soup taste good. 10:motorcycle is cheap than car. 11:This window is clear. 12:the symbol '*' is represented as start. 14:The gd software is a library for drafting programs. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 17:I like dog. 18:google is the best tools for search keyword. 20:go! go! Let's go.
[mrcode@study tmp]$ cat -An regular_express.txt | head -n 10 | tail -n 6 5 However, this dress is about $ 3183 dollars.^M$ 6 GNU is free air not free beer.^M$ 7 Her hair is very beauty.^M$ 8 I can't finish the test.^M$ 9 Oh! The soup taste good.^M$ 10 motorcycle is cheap than car.$ # 但实际上 ^M 被丢失了
# 找出 g??d 的字符串,也就是 g 开头 d 结尾的 4 字符的字符串 [mrcode@study tmp]$ grep -n 'g..d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 9:Oh! The soup taste good. 16:The world <Happy> is the same with "glad".
# 找出 oo、ooo、ooo 等数据,至少含有 2 个 o # 注意,这里不能写 oo* 因为,*是作用于第二个 o 的,表示 0 到任意个 # 也就是说如果是 oo* 有可能匹配到一个 o [mrcode@study tmp]$ grep -n 'ooo*' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes!
# 找出 开头与结尾都是 g ,并且中间至少含有一个 o 的数据 # 也就是 gog、goog 之类的数据 [mrcode@study tmp]$ grep -n 'goo*g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
# 找出 开头与结尾都是 g,中间有无字符均可 [mrcode@study tmp]$ grep -n 'g*g' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 3:Football game is not use feet only. 9:Oh! The soup taste good. 13:Oh! My god! 14:The gd software is a library for drafting programs. 16:The world <Happy> is the same with "glad". 17:I like dog. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. # 使用 g*g 发现第一行的数据就不匹配,这个还是需要再终端看,因为可以开启高亮,方便查看哈 # 原因是 * 作用于 g,g* 代表空字符或一个以上的 g,因此应该匹配 g、gg、ggg 等 # 正确的应该这样实现 [mrcode@study tmp]$ grep -n 'g.*g' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 14:The gd software is a library for drafting programs. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go.
# 找出包含任意数字的数据 # 同上,[0-9]* 只作用于一个中括号 [mrcode@study tmp]$ grep -n '[0-9][0-9]*' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1. # 直接使用 grep -n '[0-9]' regular_express.txt 也可以得到相同结果哈
范例 5:限定连续 正则字符范围 {}
找出 2 个到 5 个 o 的连续字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 华括弧在 shell 中是特殊符号,需要转义 [mrcode@study tmp]$ grep -n 'o\{2\}' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes! # 上述结果是至少是 2 个 oo 的出来了
# 单词开头结尾都是 g,中间 o,至少 2 个,最多 5 个 [mrcode@study tmp]$ grep -n 'go\{2,5\}g' regular_express.txt 18:google is the best tools for search keyword.
# 承上,只是中间的 o 至少 2 个 [mrcode@study tmp]$ grep -n 'go\{2,\}g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes!
基础正则表示法字符汇总
^word:搜索的关键词 word 在行首
范例:搜索行首为 # 的,并列出行号 grep -n '^#' file
word$:搜索的关键词 word 在行尾
范例:搜索以 !结尾的,grep -n '!$' file
.:一定有一个任意字符
范例:搜索字符串可以是 eve、eae、eee、e e;grep -n 'e.e' file
\:转义字符
范例:搜索含有单引号数据。grep -n '\’' file
*:重复另个到无穷多个前一个字符
范例:找出含有 es、ess、esss 等字符串;grep -n 'es*' file
[list]:里面列出想要截取的字符合集
范例:找出含有 g1 或 gd 的数据;grep -n 'g[1d]' file
[n1-n2]:字符合集范围
范例:找出含有任意大写字母的数据;grep -n '[A-Z]' file
[^list]:不要包含该集合中的字符或该范围的字符
范例:找出 ooa、oog 但是不包含 oot 的数据; grep -n 'oo[^t]'
\{n,m\}:连续 n 到 m 个前一个字符
\{n\}:连续 n 个前一个字符
\{n,\}:至少 n 个以上的前一个字符;咋效果上感觉和 \{n\} 是一样的
最后再强调,通配符和正则表达式不一样,比如在 ls 命令中找出以 a 开头的文件
通配符:ls -l a*
正则表达式:ls | grep -n '^a' 或则 ls | grep -n '^a.*'
1 2 3 4 5
# 范例:以 ls -l 配合 grep 找出 /etc/ 下文件类型为链接文件属性的文件名 # 符号链接文件的特点是权限前面一位是 l,根据 ls 的输出,只要找到行首为 l 的即可 [mrcode@study tmp]$ ls -l /etc | grep '^l' lrwxrwxrwx. 1 root root 56 Oct 4 18:22 favicon.png -> /usr/share/icons/hicolor/16x16/apps/fedora-logo-icon.png lrwxrwxrwx. 1 root root 22 Oct 4 18:23 grub2.cfg -> ../boot/grub2/grub.cfg
sed 工具
了解了一些正则基础使用后,可以来玩一玩 sed 和 awk ;作者就利用他们两个实现了一个小工具:logfile.sh 分析登录文件(第十八章会讲解)。里面绝大部分关键词的提取、统计等都是通过他们来完成的
sed:本身是一个管线命令,可以分析 standard input 的数据,还可以将数据进行替换、新增、截取特定行等功能
1 2
sed [-nefr] [动作]
选项与参数:
n:使用安静(silent)模式
在一般 sed 的用法中,所有来自 STDIN 的数据一般都会列出到屏幕上,加上 -n 之后,只有经过 sed 特殊处理的那一行(或则动作)才会被打印出来
e:直接在指令模式上进行 sed 的动作编辑
f:直接将 sed 的动作写在一个文件内,- f filename 则可以执行 filename 内的 sed 动作
# 范例1:利用 sed 将 /tmp/regular_express.txt 内每一行结尾若为 . 则换成 ! # 下面还是使用了动作 s 替换,后面的是转义 . 和 ! # 这样可以直接修改文件内容 [mrcode@study tmp]$ sed -i 's/\./\!/g' regular_express.txt
# 范例2:利用 sed 直接在 /tmp/regular_express.txt 最后一行加入 # This is a test # $ 表示最后一行 [mrcode@study tmp]$ sed -i '$a # This is a test ' regular_express.txt # 想要删除最后一行就简单了 [mrcode@study tmp]$ sed -i '$d' regular_express.txt
[mrcode@study tmp]$ egrep -n 'go+d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 9:Oh! The soup taste good! 13:Oh! My god!
?:「0 个或 1 个」的前一个 RE 字符
范例:搜索 gd、god
1 2 3
[mrcode@study tmp]$ egrep -n 'go?d' regular_express.txt 13:Oh! My god! 14:The gd software is a library for drafting programs!
|:用或(or)的方式找出数个字符串
范例:搜索 gd 或 good
1 2 3 4
[mrcode@study tmp]$ egrep -n 'gd|good' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 9:Oh! The soup taste good! 14:The gd software is a library for drafting programs!
():找出「群组」字符串
范例:搜索 glad 或 good
1 2 3 4 5 6
# 当然,这里使用上面完整的或来匹配两个固定单词也是可以的 [mrcode@study tmp]$ egrep -n 'g(la)|(oo)d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs! 2:apple is my favorite food! 9:Oh! The soup taste good! 16:The world <Happy> is the same with "glad"!
# # # This file is used by the man-db package to configure the man and cat paths. # It is also used to provide a manpath for those without one by examining # their PATH environment variable. For details see the manpath(5) man page.
# 增加执行权限 [mrcode@study bin]$ chmod a+x read.sh # 执行 [mrcode@study bin]$ ./read.sh first name: zhu last name: mrcode You full name: zhumrcode
下面是书上的程序
1 2 3 4 5 6 7 8 9 10 11 12 13
vim showname.sh #!/bin/bash # Program: # 用户输入姓名,程序显示出输入的姓名 # History: # 2020/01/19 mrcode first release PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "Please input you first name: " firstname # 提示使用者输入 read -p "Please input you last name: " lastname # 提示使用者输入 # -e 开启反斜杠转移的特殊字符显示,比如下面的 \n 换行显示 echo -e “\n Your full name is: ${firstname}${lastname}” # 结果由屏幕输出
1 2 3 4 5 6
# 执行结果 [mrcode@study bin]$ ./showname.sh Please input you first name: zhu Please input you last name: mrcode
Your full name is: zhumrcode
笔者小结:可以看到上面这个脚本,增加了一个良好的习惯,就是脚本说明等信息
随日期变化:利用 date 进行文件的建立
考虑一个场景,每天备份 MySql 的数据文件,备份文件名以当天日期命名,如 backup.2020-01-19.data.
vim file_perm.sh #!/bin/bash # Program # User input a filename,program will check the flowing: # 1.) exist? # 2.) file/directory? # 3.) file permissions # History # 2020/01/19 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo -e "Please input a filename,I will check the filename's type and permission. \n\n" read -p "Input a filename :" filename # 判断是否输入了字符串 test -z ${filename} && echo"You MUST input a filename. " && exit 0
# 判断该文件是否存在: 不存在输出提示信息并退出 test ! -e ${filename} && echo"The filename ${filename} does not exist" && exit 0
# 开始判断文件类型与属性 test -f ${filename} && filetype="regulare file" test -d ${filename} && filetype="directory" test -r ${filename} && perm="readable" test -w ${filename} && perm="${perm} writable" test -x ${filename} && perm="${perm} executable"
# 信息输出 echo"The filename: ${filename} is a ${filetype}" echo"And the permissions for you are : ${perm}"
测试输出如下
1 2 3 4 5 6 7 8 9 10 11 12 13
[mrcode@study bin]$ ./file_perm.sh Please input a filename,I will check the filename's type and permission. Input a filename :ss The filename ss does not exist [mrcode@study bin]$ ./file_perm.sh Please input a filename,I will check the filename's type and permission.
Input a filename :/etc The filename: /etc is a directory And the permissions for you are : readable executable
除了以上注意之外,中括号使用方式与 test 几乎一模一样,只是中括号比较常用在 条件判断 if…then..fi 的情况中。
实践范例需求如下:
当执行一个程序的时候,要求用户选择 Y 或 N
如果用户输入 Y 或 y 时,就显示「Ok,continue」
如果用户输入 N 或 n 时,就显示「Oh,interrupt!」
如果不是以上规定字符,则显示「I don’t know what your choice is」
利用中括号、&&、|| 来达成
1 2 3 4 5 6 7 8 9 10 11 12 13 14
vi ans_yn.sh #!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo"Ok,continue" && exit 0 [ "${yn}" == "N" -o "${yn}" == "n" ] && echo"Oh,interrupt!" && exit 0 echo"I don't know what your choice is" && exit 0
[mrcode@study bin]$ ./print_info.sh a b ./print_info.sh 2 ./print_info.sh:行11: 2: 没有那个文件或目录 a b a b
以下是书上的写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
vi how_paras.sh #!/bin/bash # Program: # 输出脚本文件名,与相关参数信息 # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo"The script name is ==> $0" echo"Total parameter number is ==> $#" [ "$#" -lt 2 ] && echo"参数数量太少,比如大于等于 2 个" && exit 0 echo"Your whole parameter is ==> '$@'" echo"The 1st parameter ==> $1" echo"The 2nd parameter ==> $2"
输出测试
1 2 3 4 5 6 7 8 9 10 11
[mrcode@study bin]$ ./how_paras.sh The script name is ==> ./how_paras.sh Total parameter number is ==> 0 参数数量太少,比如大于等于 2 个
[mrcode@study bin]$ ./how_paras.sh a b The script name is ==> ./how_paras.sh Total parameter number is ==> 2 Your whole parameter is ==> 'a b' The 1st parameter ==> a The 2nd parameter ==> b
shift:造成参数变量位置偏移
先修改下上面的范例,how_paras.sh 先来看看效果什么是偏移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
vi how_paras.sh #!/bin/bash # Program: # Program shows the effect of shift function # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
echo"Total parameter number is ==> $#" echo -e "Your whole parameter is ==> '$@' \n"
shift# 进行第一次 一个变量的 shift echo"Total parameter number is ==> $#" echo -e "Your whole parameter is ==> '$@' \n"
shift 3 # 进行第二次 三个变量的 shift echo"Total parameter number is ==> $#" echo"Your whole parameter is ==> '$@'"
#!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn # [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo "Ok,continue" && exit 0 if [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]; then echo"Ok,continue" exit 0 fi
# [ "${yn}" == "N" -o "${yn}" == "n" ] && echo "Oh,interrupt!" && exit 0 if [ "${yn}" == "N" ] || [ "${yn}" == "n" ]; then echo"Oh,interrupt!" exit 0 fi echo"I don't know what your choice is" && exit 0
if [ 条件表达式 ]; then 做点啥 elif [ 条件表达式 ]; then 做点啥 else 做点啥 fi
改写 ans_yn.sh 脚本如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#!/bin/bash # Program: # This program shows the user's choice # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
read -p "请输入 Y/N:" yn # [ "${yn}" == "Y" -o "${yn}" == "y" ] && echo "Ok,continue" && exit 0 if [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]; then echo"Ok,continue" exit 0 else echo"Oh,interrupt!" exit 0 fi echo"I don't know what your choice is" && exit 0
#!/bin/bash # Program: # Chek $1 is equal to "hello" # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
if [ "$1" == "hello" ]; then echo"Hello, how ary you?" elif [ "$1" == "" ]; then echo"You MUST input parameters, ex> {${0} someword}" else echo"The only parameter is 'hello', ex> {${0} hello}" fi
信息输出如下
1 2 3 4 5 6
[mrcode@study bin]$ ./hello-2.sh You MUST input parameters, ex> {./hello-2.sh someword} [mrcode@study bin]$ ./hello-2.sh hell The only parameter is 'hello', ex> {./hello-2.sh hello} [mrcode@study bin]$ ./hello-2.sh hello Hello, how ary you?
echo"现在开始检测当前主机上的服务" echo -e "www、ftp、mail、www 服务将被检测 \n" # 将 local Address 字段截取出来 datas=$(netstat -tuln | awk '{print $4}') testing=$(grep ":80"${datas}) if [ ! -z "${testing}" ]; then echo"www" fi testing=$(grep ":22"${datas}) if [ ! -z "${testing}" ]; then echo"ssh" fi testing=$(grep ":21"${datas}) if [ ! -z "${testing}" ]; then echo"ftp" fi testing=$(grep ":25"${datas}) if [ ! -z "${testing}" ]; then echo"mail" fi
#!/bin/bash # Program: # Using netstat and grep to detect www⽀~Assh⽀~Aftp and mail services # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
testing=$(grep ":80"${testfile}) if [ "${testing}" != "" ]; then echo"www is running in you system. " fi
testing=$(grep ":22"${testfile}) if [ ! -z "${testing}" ]; then echo"ssh is running in you system. " fi
testing=$(grep ":21"${testfile}) if [ ! -z "${testing}" ]; then echo"ftp is running in you system. " fi testing=$(grep ":25"${testfile}) if [ ! -z "${testing}" ]; then echo"mail is running in you system. " fi
vim cal_retired.sh #!/bin/bash # Program: # You input you demobilization date,I calculate how many days before you demobilize. # History: # 2020/01/20 mrcode first relese PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH
# 1. 告知用户程序的用途,并且告知应该如何输入日期格式 # 这个程序将尝试计算出,您的退伍日期还有多少天 echo"This program will try to calculate :" echo"How many days before your demobilization date..." read -p "Please input your demobilization date (YYYYMMDD ex>20200112):" date2
# 2. 测试判定,输入内容是否正确,使用正则表达式 date_d=$(echo${date2} | grep '[0-9]\{8\}') # 匹配 8 位数的字符串 if [ -z "${date_d}" ]; then # 您输入了错误的日期格式 echo"You input the wrong date format..." exit 1 fi
# 3. 开始计算日期 declare -i date_dem=$(date --date="${date_d}" +%s) # 退伍日期秒数 declare -i date_now=$(date +%s) # 当前日期秒数 declare -i date_total_s=$((${date_dem}-${date_now})) # 剩余秒数 # 需要注意的是:这种嵌套执行的时候,括号一定要嵌套对位置 declare -i date_d=$((${date_total_s}/60/60/24)) # 转换为日 # 中括号里面不能直接使用 < 这种符号 if [ "${date_total_s}" -lt 0 ]; then # 这里是用 -1 乘,得到是正数,标识已经退伍多少天了 echo"You had been demobilization before: $((-1*${date_d})) ago" else # 这里使用 总秒数 - 转换为日的变量(这里只是转换为了天),剩余数据转成小时 # 则计算到 n 天 n 小时 declare -i date_h=$(($((${date_total_s}-${date_d}*60*60*24))/60/60)) echo"You will demobilize after ${date_d} days and ${date_h} hours." fi
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200120 # 输入当天 You had been demobilization before: 0 ago
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200119 # 输入前一天 You had been demobilization before: 1 ago
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20200121 # 输入明天 You will demobilize after 0 days and 8 hours.
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):2020^H^H3 # 输入错误的格式 You input the wrong date format...
[mrcode@study bin]$ ./cal_retired.sh This program will try to calculate : How many days before your demobilization date... Please input your demobilization date (YYYYMMDD ex>20200112):20300120 # 输入10 年后 You will demobilize after 3652 days and 8 hours.
[mrcode@study bin]$ ./show123.sh 只能输入 one、two、three [mrcode@study bin]$ ./show123.sh one one [mrcode@study bin]$ ./show123.sh two two [mrcode@study bin]$ ./show123.sh three three [mrcode@study bin]$ ./show123.sh three111 只能输入 one、two、three
利用 function 功能
函数功能,不用多说,可以被复用,优化程序结构,语法如下
1 2 3
functionfname(){ 程序段 }
TIP
由于 shell script 执行方式是由上而下,由左而右,因此 function 的代码一定要在程序的最前面
[mrcode@study bin]$ ./show123-2.sh one Your choice is one [mrcode@study bin]$ vim show123-2.sh [mrcode@study bin]$ ./show123-2.sh tow 只能输入 one、two、three [mrcode@study bin]$ ./show123-2.sh two Your choice is TWO
[mrcode@study bin]$ ./show123-3.sh one Your choice is 1 [mrcode@study bin]$ ./show123-3.sh two Your choice is 2 # 可以看到,这里给定参数 1,那么在里面获取 ${1},的时候就获取到了
[mrcode@study bin]$ ./show123-3.sh three Your choice is three # 在外部给定的是脚本中的变量 $1, 在内部也能获取到变量的具体内容 [mrcode@study bin]$ ./show123-3.sh threex 只能输入 one、two、three
read -p "请输入一个目录,将会检测该目录是否可读、可写、可执行:" dir # 判定输入不为空,并且目录存在 if [ "${dir}" == '' -o ! -d "${dir}" ]; then echo"The ${dir} is NOT exist in your system" exit 1 fi
# 获取该目录下的文件权限信息 filelist=$(ls ${dir}) for file in${filelist} do perm="" test -r "${dir}/${file}" && perm="${perm} readable" test -w "${dir}/${file}" && perm="${perm} writable" test -x "${dir}/${file}" && perm="${perm} executable" echo"The file ${dir}/${file}'s permission is ${perm}" done
[mrcode@study bin]$ ./what_to_eat.sh your may eat 太上皇 [mrcode@study bin]$ ./what_to_eat.sh your may eat 越油越好吃打呀 [mrcode@study bin]$ ./what_to_eat.sh your may eat 想不出吃什么 [mrcode@study bin]$ ./what_to_eat.sh
while [ "${eated}" -lt 3 ]; do check=$((${RANDOM} * ${eatnum} / 32767 + 1)) mycheck=0 # 当为 0 时,表示不重复 # 去重检查 if [ ${eated} -gt 0 ]; then# 当已选中至少一个店铺的时候,才执行 for i in $(seq 1 ${eated}) do if [ "${eatedcon[$i]}" == $check ]; then mycheck=1 fi done fi if [ ${mycheck} == 0 ]; then echo"your may eat ${eat[${check}]}" eated=$(( ${eated} + 1 )) eatedcon[${eated}]=${check}# 将已选中结果存储起来 fi done
# 范例 2:将 show_animal.sh 的执行过程全部列出来 [mrcode@study bin]$ sh -x show_animal.sh + PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:/home/mrcode/bin + export PATH + for animal in dog cat elephant + echo'There are dogs...' There are dogs... + for animal in dog cat elephant + echo'There are cats...' There are cats... + for animal in dog cat elephant + echo'There are elephants...' There are elephants...
# 范例 1: 执行 find / -perm /7000 > /tmp/text.txt,立刻丢到背景去暂停 [root@study ~]# find / -perm /7000 > /tmp/text.txt find: '/proc/29541/task/29541/fd/5': No such file or directory find: '/proc/29541/task/29541/fdinfo/5': No such file or directory find: '/proc/29541/fd/6': No such file or directory find: '/proc/29541/fdinfo/6': No such file or directory ^Z [4]+ Stopped find / -perm /7000 > /tmp/text.txt
# 范例 2:让该工作在背景下进行,并且观察他 [root@study ~]# jobs ; bg %4; jobs [2]- Stopped vim ~/.bashrc [3] Stopped find / -print [4]+ Stopped find / -perm /7000 > /tmp/text.txt
# 最终的指令是如下的 [root@study ~]# kill -SIGHUP $(ps aux | grep 'rsyslogd' | grep -v 'grep' | awk '{print $2}') # 是否重启无法看通过看进程来知道,可以看日志 [root@study ~]# tail -5 /var/log/messages Mar 9 23:20:01 study systemd: Removed slice User Slice of root. Mar 9 23:30:01 study systemd: Created slice User Slice of root. Mar 9 23:30:01 study systemd: Started Session 19 of user root. Mar 9 23:30:01 study systemd: Removed slice User Slice of root. Mar 9 23:35:20 study rsyslogd: [origin software="rsyslogd" swVersion="8.24.0-38.el7" x-pid="1273" x-info="http://www.rsyslog.com"] rsyslogd was HUPed # 看上面,rsyslogd was HUPed 的字样,表示有重新启动
# 范例 2:强制终止所有以 httpd 启动的进程(其实当前没有该进程启动) [root@study ~]# killall -9 httpd httpd: no process found
# 范例 3:依次询问每个 bash 程序是否需要被终止 [root@study ~]# killall -i -9 bash Signal bash(7780) ? (y/N) n Signal bash(7835) ? (y/N) n Signal bash(9051) ? (y/N) n bash: no process found
# 这里都选择了 n,所以提示没有进程被找到,按下 y 就杀掉了
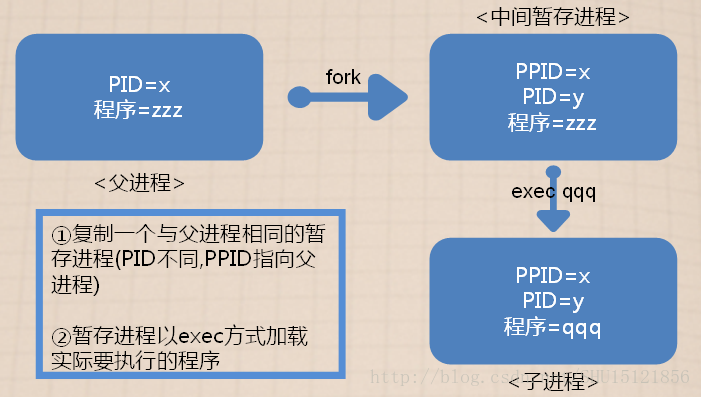
关于程序的执行顺序
CPU 是切换着执行进程,那么谁先执行?这个就要看进程的优先级 priority 与 CPU 排程(每个进程被 CPU 运行的演算规则)
Priority 与 Nice 值
CPU 一秒钟可以运行多达数 G 的微指令次数,通过核心的 CPU 调度可以让各程序 被 CPU 所切换运行, 因此每个程序在一秒钟内或多或少都会被 CPU 执行部分的指令码。
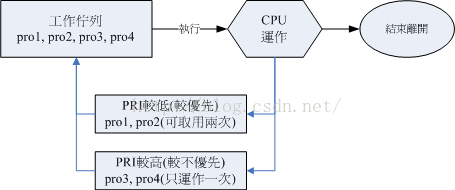
如上图,有了优先级之后,高优先级的可用被执行两次,低优先级则执行 1 次,但是上图仅是示意图,并非高优先级的就会执行两次,Linux 给予进程一个优先执行序(priority PRI),PRI 值越低优先级越高,不过该值是由核心动态调整的,用户无法直接调整 PRI 值
1 2 3 4 5
[root@study ~]# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 0 R 0 7183 9051 0 90 10 - 12406 - pts/0 00:00:00 ps 4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su 4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash
由于 PRI 是动态调整的,用户无法干涉,但是可以通过 Nice 值来达到一定的优先级调整,Nice 就是上述中的 NI 值,一般来说 PRI 与 NI 的相关性 PRI(new)=PRI(old)+nice,虽然可以调整 nice 的值,由于 PRI 是动态调整的,所以不包装调整完之后,最终的 PRI 就会变低,优先级变高的
此外,必须要注意,nice 值范围
nice 值范围是 -20~19
root 可随意调整自己或他人进程的 Nice 值,且范围为 -20~19
一般使用者仅可调整自己进程的 Nice 值,且范围仅为 0~19(避免一般用户抢占系统资源)
一般使用者仅可将 nice 值越调越高;比如 nice 为 5,则未来仅能调整到大于 5;
那么调整 nice 值有两种方式:
一开始执行程序就立即给予一个特定的 nice 值:用 nice 指令
调整某个已经存在的 PID 的 nice 值:用 renice 指令
nice:新执行的指令给予新的 nice 值
1 2 3 4
nice [-n 数字] command
-n:后面接一个数值,数值范围 -20~19
1 2 3 4 5 6 7 8 9 10 11
# 范例 1: 用 root 给一个 nice 值为 -5,用于执行 vim,并观察该进程 [root@study ~]# nice -n -5 vim & [2] 30185 [root@study ~]# ps -l F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD 4 S 0 8985 7780 0 80 0 - 57972 do_wai pts/0 00:00:00 su 4 S 0 9051 8985 0 90 10 - 29118 do_wai pts/0 00:00:00 bash 4 T 0 30185 9051 0 85 5 - 10791 do_sig pts/0 00:00:00 vim 0 R 0 30652 9051 0 90 10 - 12407 - pts/0 00:00:00 ps # 原本的 bash PRI 为 90,所以 vim 预设为 90,这里给予 nice -5,所以最终 PRI 变成了 85 # 要注意:不一定正好变成 85,因为会动态调整的
[root@study home]# cd ~ [root@study ~]# umount /home/ umount: /home: target is busy. (In some cases useful info about processes that use the device is found by lsof(8) or fuser(1)) # 通过 fuser 知道有好几个进程在该目录下运行,可以通过如下的方式一个一个删除 [root@study ~]# fuser -mki /home/ /home: 7294c 7358c 7362c 7722c 8884c 19238c 19289c 19291c 19601c 25650c 25674c 25685c 25746c Kill process 7294 ? (y/N) # 以上指令有一个问题,颇为棘手,就是很容易杀到自己 bash 的进程,那么久直接把直接踢掉了 # 不知道这个这么排除掉是出方便的
# 3. 强制重新启动 crond,然后查看登录日志 [root@study ~]# systemctl restart crond [root@study ~]# tail /var/log/cron Mar 17 13:01:01 study run-parts(/etc/cron.hourly)[3889]: finished mcelog.cron Mar 17 13:10:01 study CROND[3972]: (root) CMD (/usr/lib64/sa/sa1 1 1) Mar 17 13:14:01 study crond[1400]: ((null)) Unauthorized SELinux context=system_u:system_r:system_cronjob_t:s0-s0:c0.c1023 file_context=unconfined_u:object_r:admin_home_t:s0 (/etc/cron.d/checktime) Mar 17 13:14:01 study crond[1400]: (root) FAILED (loading cron table) Mar 17 13:15:08 study crond[1400]: (CRON) INFO (Shutting down) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 13% if used.) Mar 17 13:15:08 study crond[4073]: ((null)) Unauthorized SELinux context=system_u:system_r:system_cronjob_t:s0-s0:c0.c1023 file_context=unconfined_u:object_r:admin_home_t:s0 (/etc/cron.d/checktime) Mar 17 13:15:08 study crond[4073]: (root) FAILED (loading cron table) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (running with inotify support) Mar 17 13:15:08 study crond[4073]: (CRON) INFO (@reboot jobs will be run at computer's startup.) # 上述日志中有 Unauthorized 的信息,表示有错误,因为原本的安全本文与文件的实际安全本文无法搭配的缘故, # 信息还列出了 SELinux context 与 file_context 的信息,表示的确不匹配
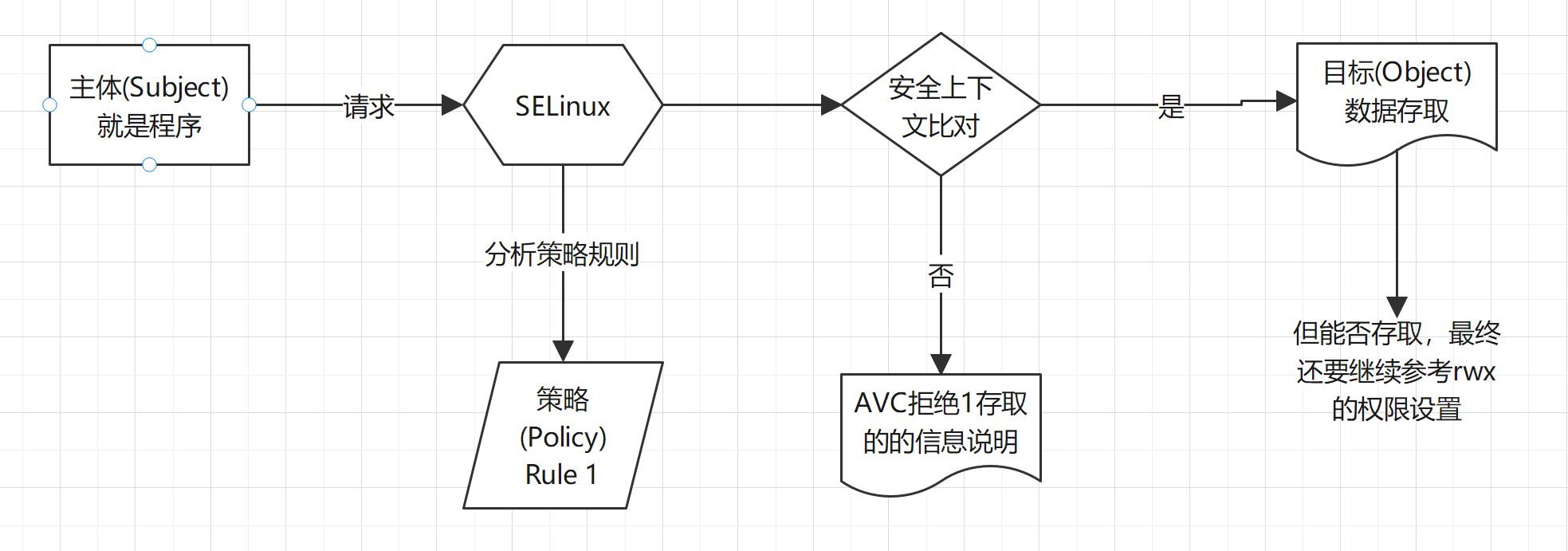
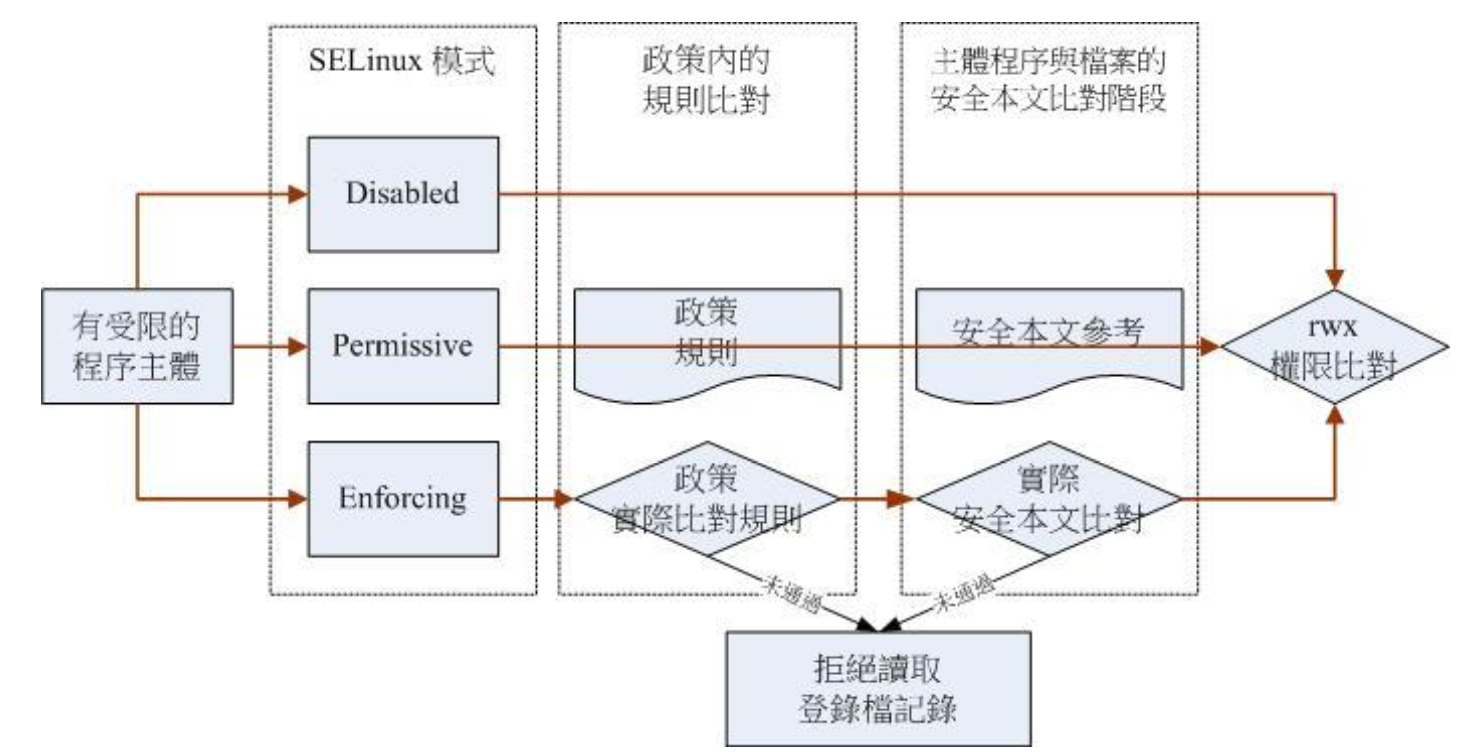
SELinux 三种模式的启动、关闭与观察
并非所有的 Linux distribution 都支持 SELinux,CentOS 7.x 本身就有支持 SELinux,所以你不需要自行编译 SELinux 到你的 Linux 核心中。目前 SELinux 是否启动有三种模式:
[root@study ~]# vim /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=enforcing # 可选择为上述 3 个 # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted # 可选值为上述 3 个
# 范例 1:查询所有的布尔值设置 [root@study ~]# getsebool -a abrt_anon_write --> off abrt_handle_event --> off abrt_upload_watch_anon_write --> on ... cron_can_relabel --> off # 这个与 cron 有关 cron_system_cronjob_use_shares --> off cron_userdomain_transition --> on ... httpd_anon_write --> off # 与网页 http 有关 httpd_builtin_scripting --> on httpd_can_check_spam --> off # 每一行都是一个规则
SELinux 各个规则规范的主体进程能够读取的文件 SELinux type 查询 seinfo、sesearch
# 范例 4:重新启动 crond 看看有没有正确启动 checktime [root@study ~]# systemctl restart crond [root@study ~]# tail /var/log/cron Mar 17 16:01:01 study CROND[5886]: (root) CMD (run-parts /etc/cron.hourly) Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5886]: starting 0anacron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5898]: finished 0anacron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5886]: starting mcelog.cron Mar 17 16:01:01 study run-parts(/etc/cron.hourly)[5904]: finished mcelog.cron Mar 17 16:10:01 study CROND[5989]: (root) CMD (/usr/lib64/sa/sa1 1 1) Mar 17 16:12:48 study crond[4073]: (CRON) INFO (Shutting down) Mar 17 16:12:48 study crond[6068]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 62% if used.) Mar 17 16:12:49 study crond[6068]: (CRON) INFO (running with inotify support) Mar 17 16:12:49 study crond[6068]: (CRON) INFO (@reboot jobs will be run at computer's startup.) # 没有报错信息
从这里看来 restorecon 很方便,chcon 还是比较麻烦的
semanage 默认目录的安全性本文查询与修改
为什么 restorecon 可以恢复原本的 SELinux type 呢?那一定是有个地方在记录每个文件/目录的 SELinux 默认类型
# 3. 查看里面的文件内容 [root@study ~]# curl ftp://localhost/pub/sysctl.conf # sysctl settings are defined through files in # /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/. # # Vendors settings live in /usr/lib/sysctl.d/. # To override a whole file, create a new file with the same in # /etc/sysctl.d/ and put new settings there. To override # only specific settings, add a file with a lexically later # name in /etc/sysctl.d/ and put new settings there. # # For more information, see sysctl.conf(5) and sysctl.d(5).
[root@study ~]# vim /var/log/messages Aug 9 02:55:58 station3-39 setroubleshoot:SELinux is preventing /usr/sbin/vsftpd from lock access on the file /home/ftptest/test.txt. For complete SELinux messages. run sealert -l 3axxxxxxxx # 之类的字样,关键词就是 sealert ,执行这条命令 [root@study ~]# sealert -l 3axxxxxxxx SELinux is preventing /usr/sbin/vsftpd from lock access on the file /home/ftptest/test/txt. # 下面说有 47.5% 的几率是由于这个原因所发生,并且可以使用 setsebool 去解决的意思 ******* Plugin catchall_boolean(47.5 confidence) suggests ********
if you want to allow ftp to home dir ... Do setsebool -P ftp_home_dir 1
If you want to allow vsftpd to have read access on the test.txt file Then you need to change the label on test.txt Do # 下面这一条数据 # semanage fcontext -a -t FILE_TYPE 'test.txt' .... 很多数据 Then execute: restorecon -v 'test.txt'# 还有这一条数据,都是要参考的解决方案
If you believe that vsftpd should be allowed read access on the test.txt file by default. Then you should report this as a bug. You can generate a local policy module to allow this access. Do allow this access for now by executing: # ausearch -c 'vsftpd' --raw | audit2allow -M my-vsftpd # semodule -i my-vsftpd.pp
Additional Information: Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023 Target Context unconfined_u:object_r:var_t:s0 Target Objects test.txt [ file ] Source vsftpd Source Path /usr/sbin/vsftpd Port <Unknown> Host study.centos.mrcode Source RPM Packages Target RPM Packages Policy RPM selinux-policy-3.13.1-252.el7.noarch Selinux Enabled True Policy Type targeted Enforcing Mode Enforcing Host Name study.centos.mrcode Platform Linux study.centos.mrcode 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 Alert Count 2 First Seen 2020-03-17 22:46:17 CST Last Seen 2020-03-17 22:46:32 CST Local ID 88f08c09-c510-4518-bbcc-58bcee06ffb0
Raw Audit Messages type=AVC msg=audit(1584456392.386:979): avc: denied { read } for pid=10979 comm="vsftpd" name="test.txt" dev="dm-0" ino=35108539 scontext=system_u:system_r:ftpd_t:s0-s0:c0.c1023 tcontext=unconfined_u:object_r:var_t:s0 tclass=file permissive=0
# 1. 先处理 vsftpd 的配置文件,加入 port 的端口参数 [root@study ~]# vim /etc/vsftpd/vsftpd.conf listen_port=555
# 2. 重启服务,并查看日志 [root@study ~]# systemctl restart vsftpd Job for vsftpd.service failed because the control process exited with error code. See "systemctl status vsftpd.service" and "journalctl -xe"for details. [root@study ~]# grep sealert /var/log/messages Mar 17 23:03:23 study setroubleshoot: SELinux is preventing /usr/sbin/vsftpd from name_bind access on the tcp_socket port 555. For complete SELinux messages run: sealert -l e3e3dee0-83eb-4cb8-b894-8be590fee082
[root@study ~]# sealert -l e3e3dee0-83eb-4cb8-b894-8be590fee082 SELinux is preventing /usr/sbin/vsftpd from name_bind access on the tcp_socket port 555.
If you want to allow /usr/sbin/vsftpd to bind to network port 555 Then you need to modify the port type. Do # semanage port -a -t PORT_TYPE -p tcp 555 where PORT_TYPE is one of the following: certmaster_port_t, cluster_port_t, ephemeral_port_t, ftp_data_port_t, ftp_port_t, hadoop_datanode_port_t, hplip_port_t, isns_port_t, port_t, postgrey_port_t, unreserved_port_t.
If you believe that vsftpd should be allowed name_bind access on the port 555 tcp_socket by default. Then you should report this as a bug. You can generate a local policy module to allow this access. Do allow this access for now by executing: # ausearch -c 'vsftpd' --raw | audit2allow -M my-vsftpd # semodule -i my-vsftpd.pp
Additional Information: Source Context system_u:system_r:ftpd_t:s0-s0:c0.c1023 Target Context system_u:object_r:hi_reserved_port_t:s0 Target Objects port 555 [ tcp_socket ] Source vsftpd Source Path /usr/sbin/vsftpd Port 555 Host study.centos.mrcode Source RPM Packages vsftpd-3.0.2-25.el7.x86_64 Target RPM Packages Policy RPM selinux-policy-3.13.1-252.el7.noarch Selinux Enabled True Policy Type targeted Enforcing Mode Enforcing Host Name study.centos.mrcode Platform Linux study.centos.mrcode 3.10.0-1062.el7.x86_64 #1 SMP Wed Aug 7 18:08:02 UTC 2019 x86_64 x86_64 Alert Count 1 First Seen 2020-03-17 23:03:20 CST Last Seen 2020-03-17 23:03:20 CST Local ID e3e3dee0-83eb-4cb8-b894-8be590fee082
Raw Audit Messages type=AVC msg=audit(1584457400.225:1008): avc: denied { name_bind } for pid=11443 comm="vsftpd" src=555 scontext=system_u:system_r:ftpd_t:s0-s0:c0.c1023 tcontext=system_u:object_r:hi_reserved_port_t:s0 tclass=tcp_socket permissive=0