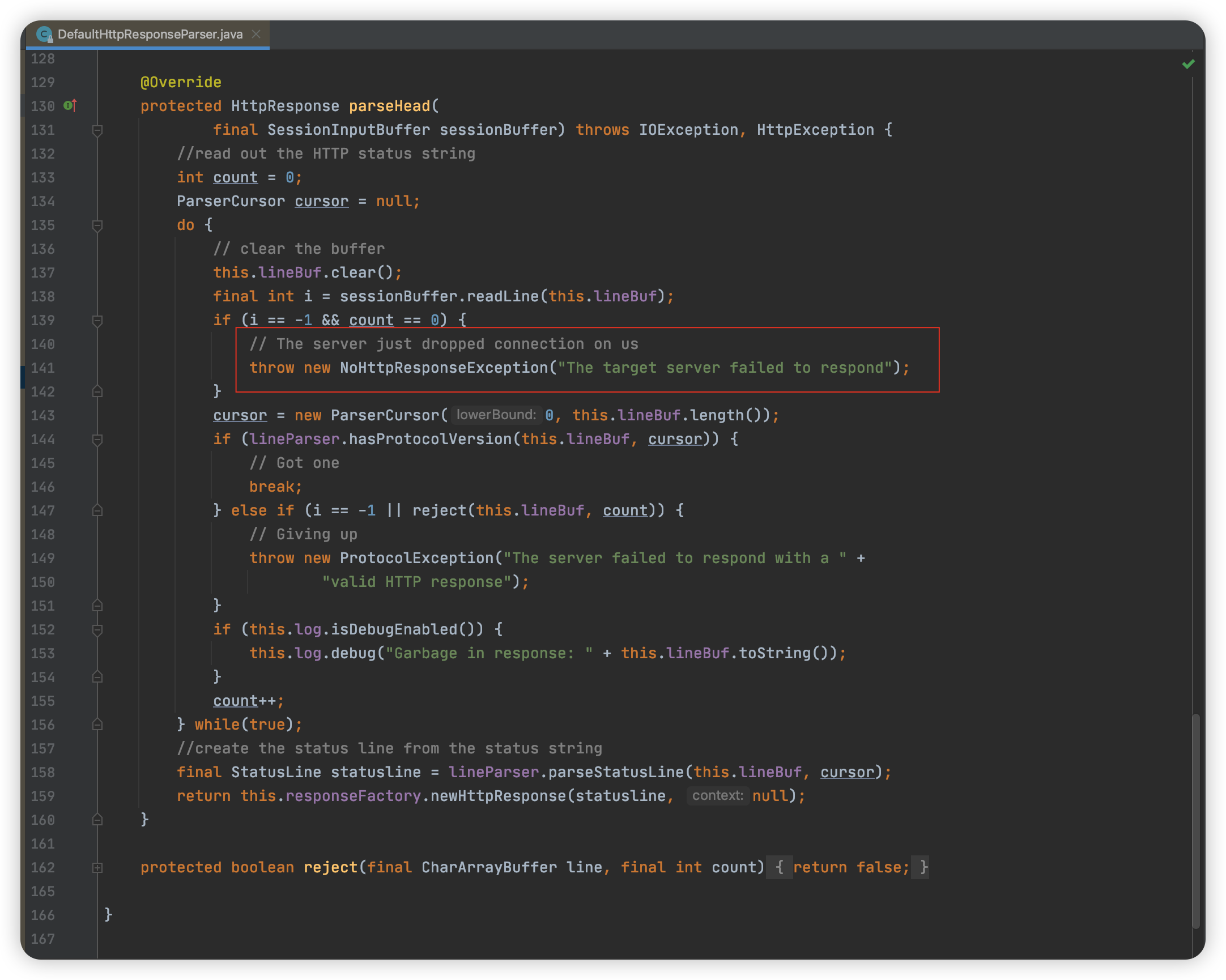
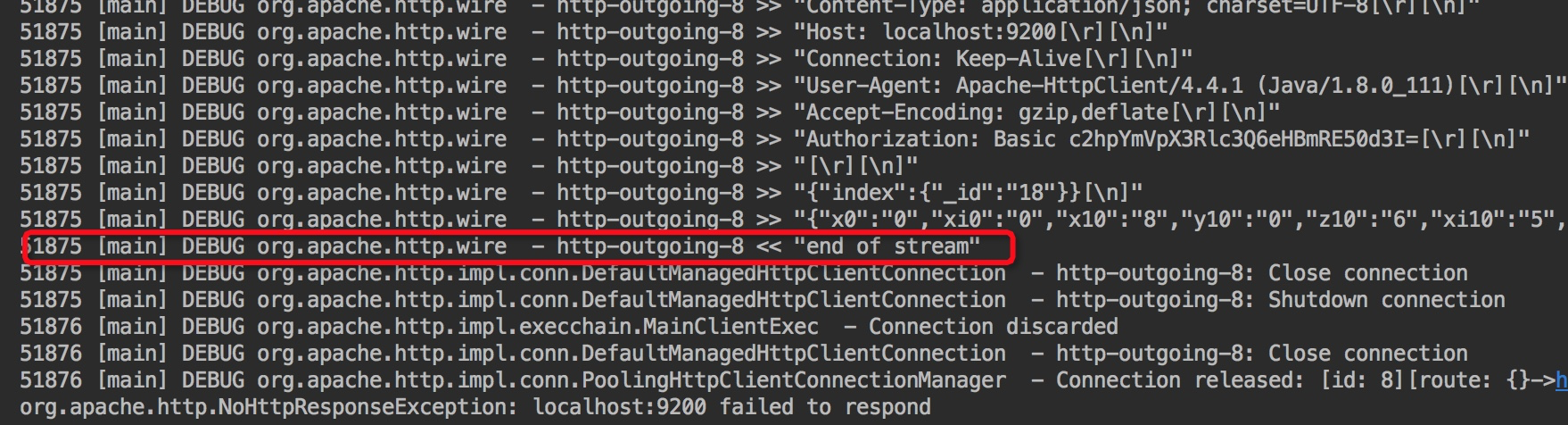
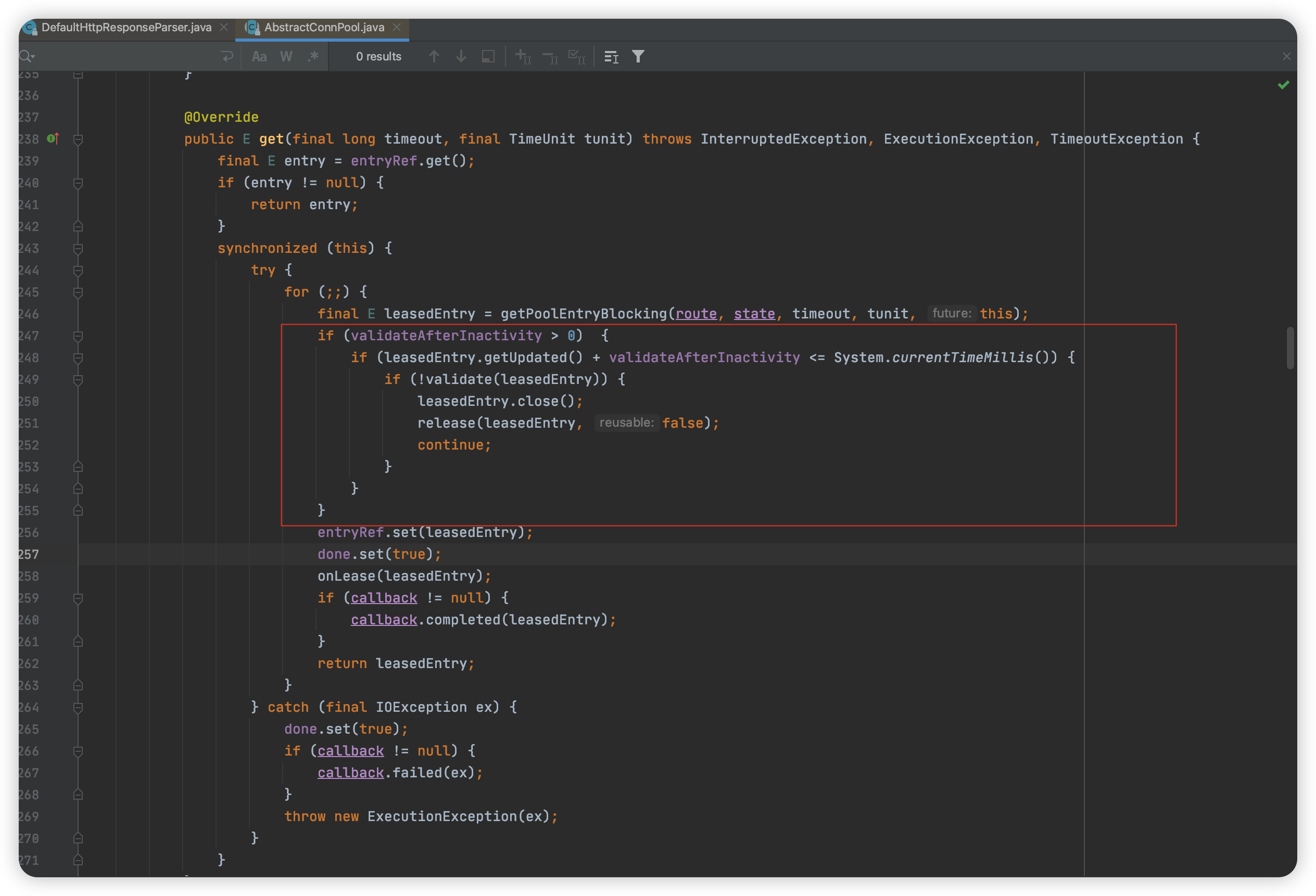
此时,502 Bad Gateway 的报错虽然没有出现,但是会偶发性的出现NoHttpResponseException的报错,大搞也是2亿笔出现3-4笔的NoHttpResponseException的报错。然后我们就怀疑502 Bad Gateway 报错和NoHttpResponseException报错本质上是一样的。
NoHttpResponseException错误详情:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
org.apache.http.NoHttpResponseException: target failed to respond at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:141) at org.apache.http.impl.conn.DefaultHttpResponseParser.parseHead(DefaultHttpResponseParser.java:56) at org.apache.http.impl.io.AbstractMessageParser.parse(AbstractMessageParser.java:259) at org.apache.http.impl.DefaultBHttpClientConnection.receiveResponseHeader(DefaultBHttpClientConnection.java:163) at org.apache.http.impl.conn.CPoolProxy.receiveResponseHeader(CPoolProxy.java:157) at org.apache.http.protocol.HttpRequestExecutor.doReceiveResponse(HttpRequestExecutor.java:273) at org.apache.http.protocol.HttpRequestExecutor.execute(HttpRequestExecutor.java:125) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:272) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)