/** * declared as volatile to ensure atomic access by multiple threads. */ privatestaticvolatile ThreadSafeLazyLoadedSingleton instance;
/** * Private constructor to prevent instantiation from outside the class. */ privateThreadSafeLazyLoadedSingleton(){ // Protect against instantiation via reflection if (instance != null) { thrownew IllegalStateException("Already initialized."); } }
/** * The instance doesn't get created until the method is called for the first time. */ publicstaticsynchronized ThreadSafeLazyLoadedSingleton getInstance(){ if (instance == null) { instance = new ThreadSafeLazyLoadedSingleton(); } return instance; }
/** * declared as volatile to ensure atomic access by multiple threads. */ privatestaticvolatile ThreadSafeDoubleCheckSingleton instance;
/** * Private constructor to prevent instantiation from outside the class. */ privateThreadSafeDoubleCheckSingleton(){ // Protect against instantiation via reflection if (instance != null) { thrownew IllegalStateException("Already initialized."); } }
/** * To be called by user to obtain instance of the class. */ publicstatic ThreadSafeDoubleCheckSingleton getInstance(){ // local variable increases performance by 25 percent ThreadSafeDoubleCheckSingleton result = instance; // Check if singleton instance is initialized. if (instance == null) { synchronized (ThreadSafeDoubleCheckSingleton.class) { result = instance; if (result == null) { result = new ThreadSafeDoubleCheckSingleton(); instance = result; } } } return result; }
/** * Private constructor to prevent instantiation from outside the class. */ privateStaticInnerClassSingleton(){
}
/** * The InstanceHolder is a static inner class, and it holds the Singleton instance. * It is not loaded into memory until the getInstance() method is called. */ privatestaticclassInstanceHolder{ privatestaticfinal StaticInnerClassSingleton INSTANCE = new StaticInnerClassSingleton(); }
/** * When this method is called, the InstanceHolder is loaded into memory * and creates the Singleton instance. This method provides a global access point * for the singleton instance. */ publicstatic StaticInnerClassSingleton getInstance(){ return InstanceHolder.INSTANCE; }
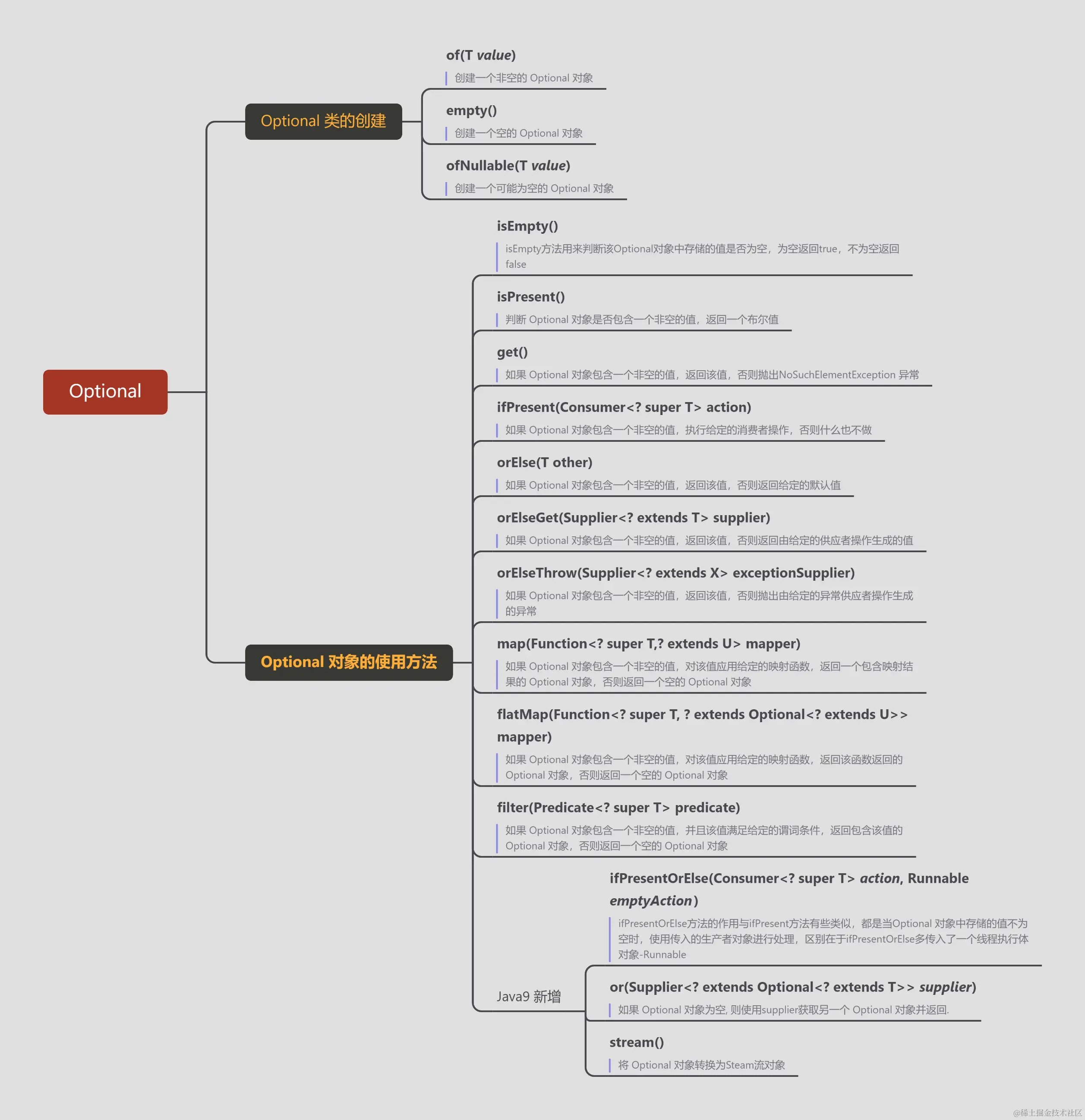
/** * Return the value if present, otherwise return {@code other}. */ public T orElse(T other){ return value != null ? value : other; }
/** * Return the value if present, otherwise invoke {@code other} and return * the result of that invocation. */ public T orElseGet(Supplier<? extends T> other){ return value != null ? value : other.get(); }
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes){ List<String> configurations = new ArrayList(SpringFactoriesLoader.loadFactoryNames(this.getSpringFactoriesLoaderFactoryClass(), this.getBeanClassLoader())); ImportCandidates.load(AutoConfiguration.class, this.getBeanClassLoader()).forEach(configurations::add); Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories nor in META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports. If you are using a custom packaging, make sure that file is correct."); return configurations; }
属性是理解 POM 基础知识的最后一个必需部分。Maven 属性是值占位符,就像 Ant 中的属性一样。它们的值可以通过使用符号${X}在 POM 中的任何位置访问,其中X是属性。 或者它们可以被插件用作默认值,例如:
1 2 3 4 5 6 7 8 9 10 11 12
<project> ... <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <!-- Following project.-properties are reserved for Maven in will become elements in a future POM definition. --> <!-- Don't start your own properties properties with project. --> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> </properties> ... </project>
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <!-- "Project Build" contains more elements than just the BaseBuild set --> <build>...</build> <profiles> <profile> <!-- "Profile Build" contains a subset of "Project Build"s elements --> <build>...</build> </profile> </profiles> </project>
finalName: 这是最终构建时项目的名称(不带文件扩展名,例如:my-project-1.0.jar)。 默认为${artifactId}-${version}。不过,”finalName “这个术语有点名不副实,因为构建捆绑项目的插件完全有权忽略/修改这个名称(但它们通常不会这样做)。例如,如果maven-jar-plugin被配置为给 jar 提供一个 test 分类器,那么上面定义的实际 jar 将被构建为my-project-1.0-test.jar。
<configuration> <itemscombine.children="append"> <!-- combine.children="merge" is the default --> <item>child-1</item> </items> <propertiescombine.self="override"> <!-- combine.self="merge" is the default --> <childKey>child</childKey> </properties> </configuration>
POM 4.0 的一个新功能是项目可以根据构建环境改变设置。一个profile元素既包含可选激活(配置文件触发器),也包含激活该配置文件后对 POM 所做的一系列更改。例如,为测试环境构建的项目可能与最终部署环境有着不同的数据库。或者,根据所使用的 JDK 版本不同,依赖关系也可能来自不同的资源库。The elements of profiles are as follows:
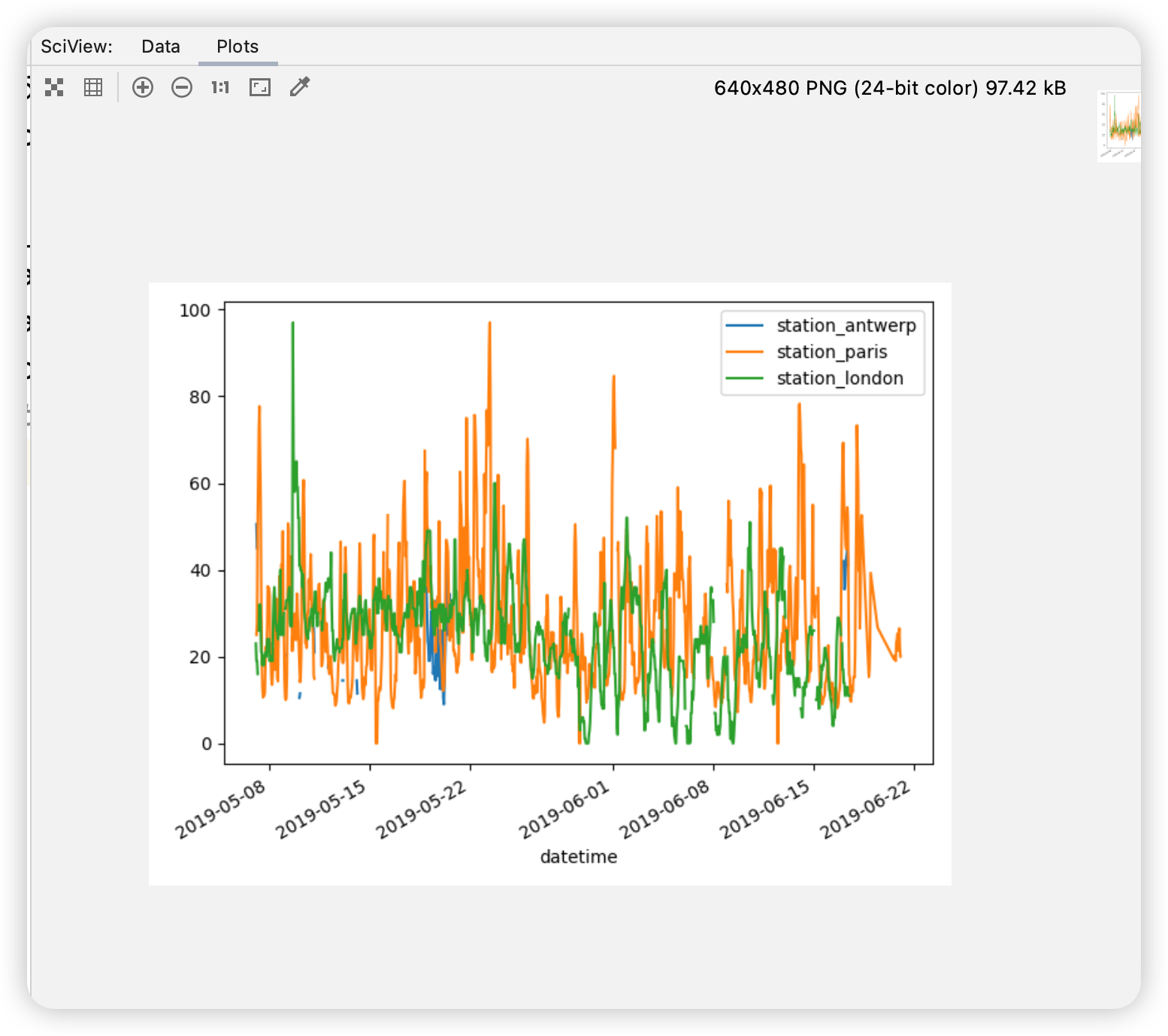
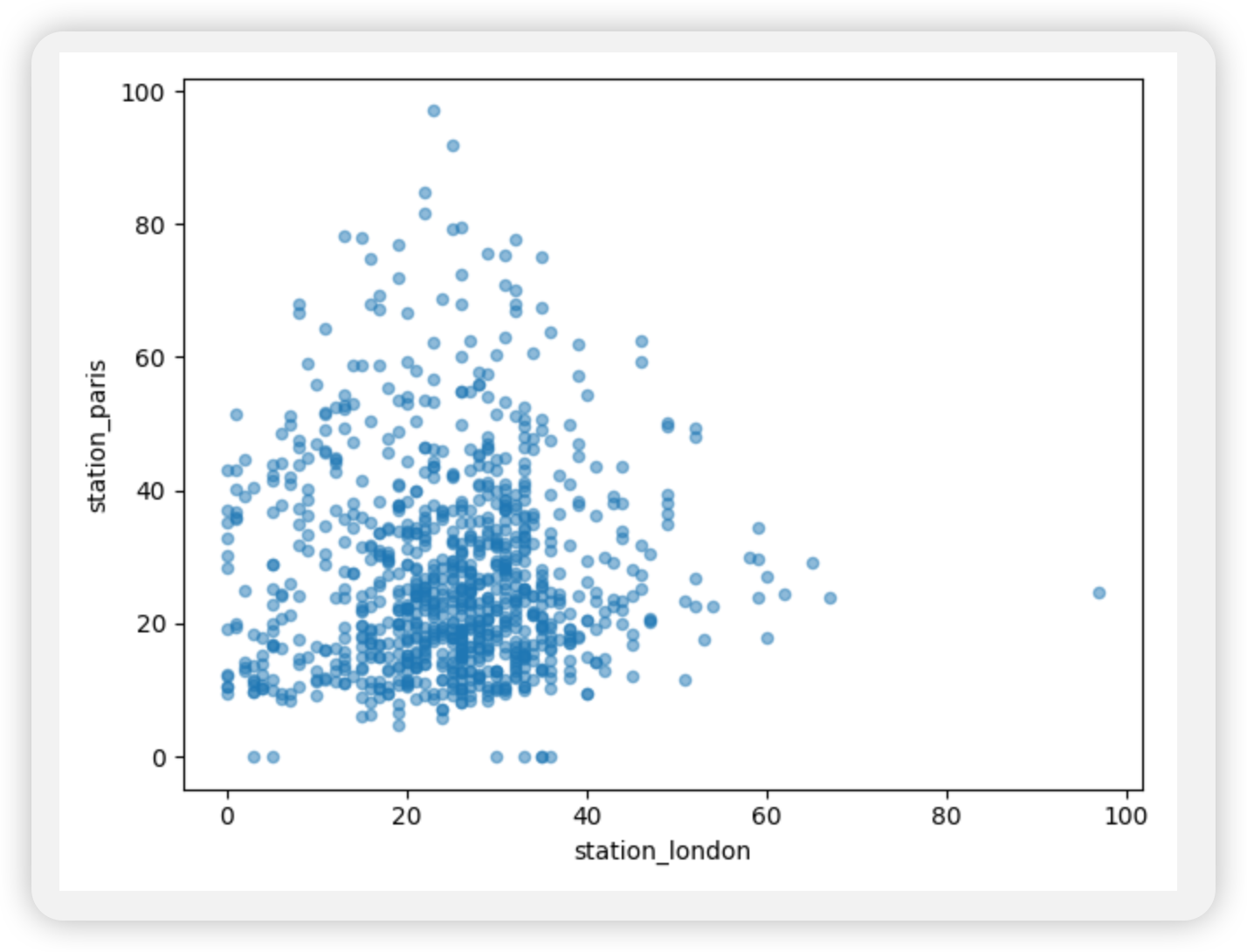
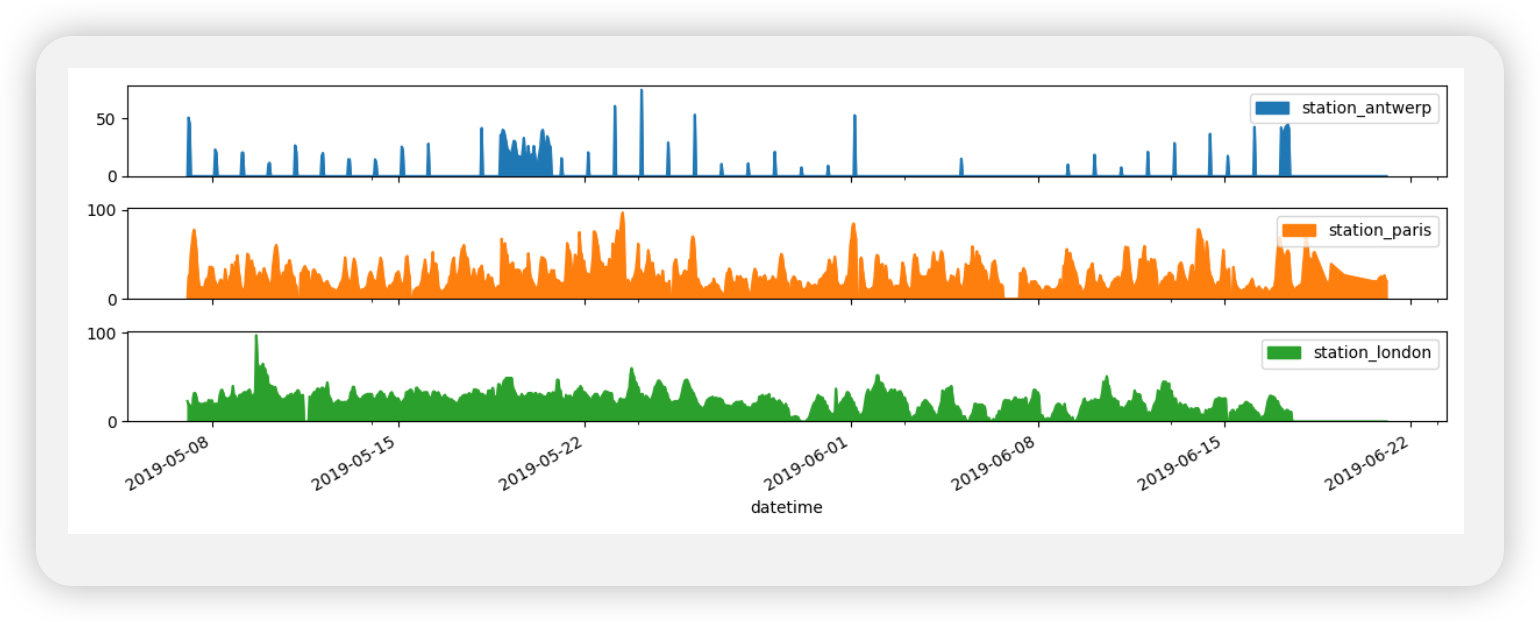
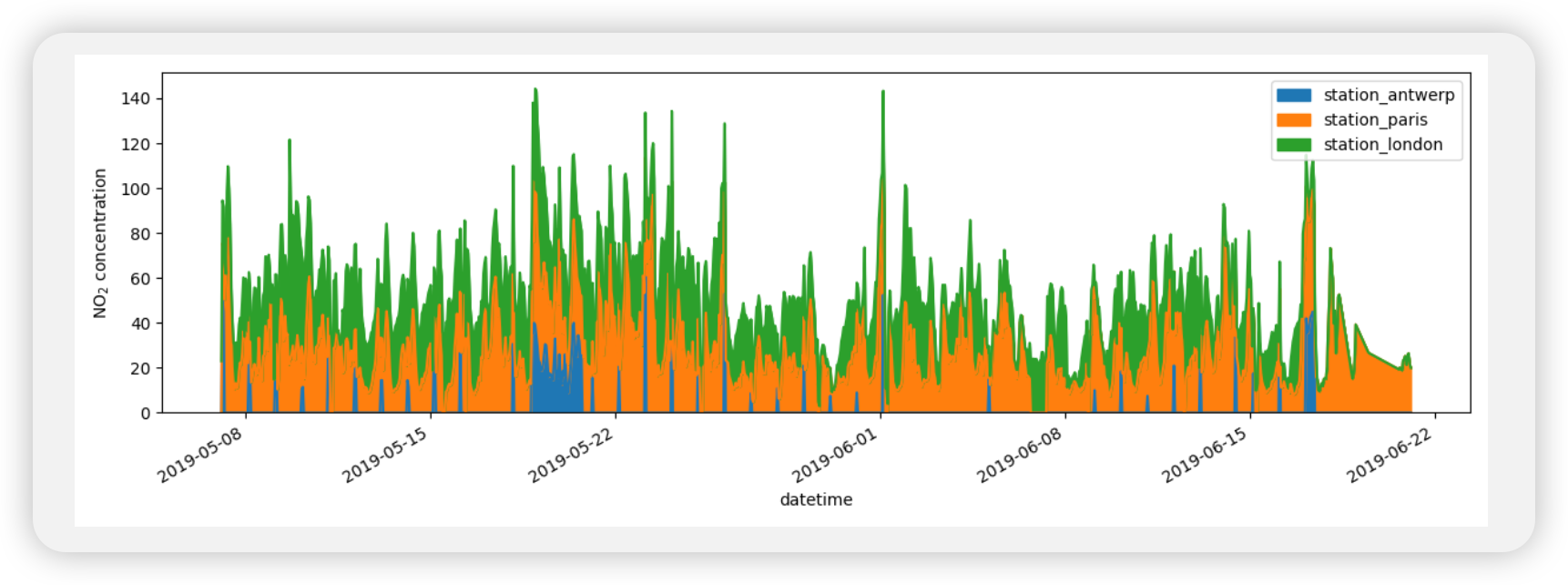
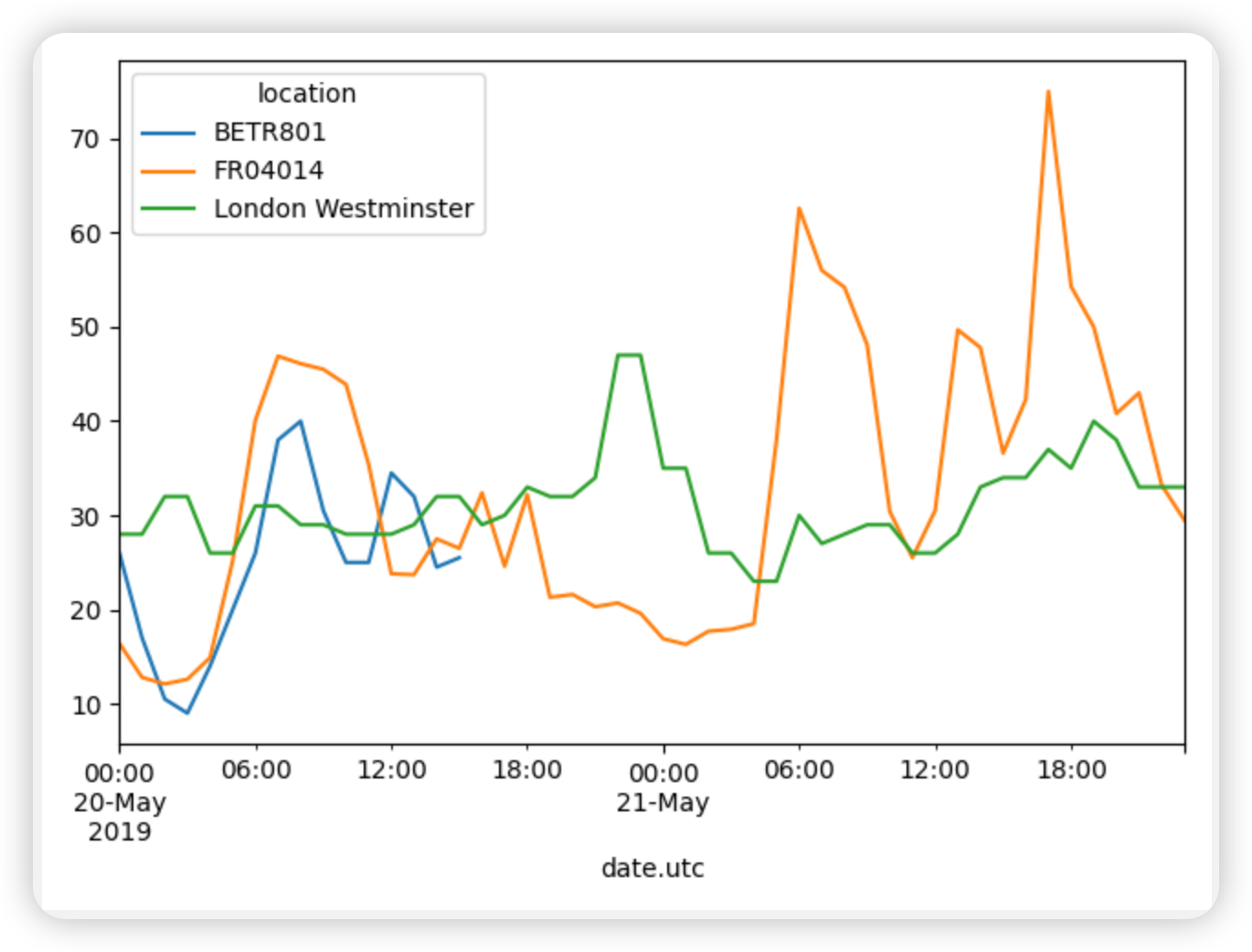
city country location parameter value unit date.utc 2019-06-1806:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-1708:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-1707:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-1706:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-1705:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
air_quality = pd.read_csv( "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ) # filter for no2 data only no2 = air_quality[air_quality["parameter"] == "no2"] # use 2 measurements (head) for each location (groupby) no2_subset = no2.sort_index().groupby(["location"]).head(2) print(no2_subset)
Out:
1 2 3 4 5 6 7 8 9
city country ... value unit date.utc ... 2019-04-09 01:00:00+00:00 Antwerpen BE ... 22.5 µg/m³ 2019-04-09 01:00:00+00:00 Paris FR ... 24.4 µg/m³ 2019-04-09 02:00:00+00:00 London GB ... 67.0 µg/m³ 2019-04-09 02:00:00+00:00 Antwerpen BE ... 53.5 µg/m³ 2019-04-09 02:00:00+00:00 Paris FR ... 27.4 µg/m³
name age sex height blood 0 张三 20 男 175 O 1 李四 21 女 160 A 2 王五 50 男 170 B 3 赵六 30 男 173 AB 4 田七 40 男 180 A 0 小明 18 男 181 O 1 小黄 24 男 177 A 2 小红 17 女 170 B 3 小李 32 男 157 AB 4 小花 29 女 168 A
print("shape of class_01_students:", class_01_students.shape) # shape of class_01_students: (5, 5) print("shape of class_02_students:", class_02_students.shape) # shape of class_02_students: (5, 5) print("shape of students:", students.shape) # shape of students: (10, 5)
name age sex height blood 2 小红 17 女 170 B 0 小明 18 男 181 O 0 张三 20 男 175 O 1 李四 21 女 160 A 1 小黄 24 男 177 A 4 小花 29 女 168 A 3 赵六 30 男 173 AB 3 小李 32 男 157 AB 4 田七 40 男 180 A 2 王五 50 男 170 B
name age sex height blood 2 王五 50 男 170 B 4 田七 40 男 180 A 3 小李 32 男 157 AB 3 赵六 30 男 173 AB 4 小花 29 女 168 A 1 小黄 24 男 177 A 1 李四 21 女 160 A 0 张三 20 男 175 O 0 小明 18 男 181 O 2 小红 17 女 170 B
name age sex height blood student_id chinese math english physics 0 张三 20 男 175 O 1 89.0 76.0 88.0 90.0 1 李四 21 女 160 A 2 76.0 67.0 50.0 89.0 2 王五 50 男 170 B 3 57.0 82.0 91.0 88.0 3 赵六 30 男 173 AB 4 23.0 43.0 54.0 76.0 4 田七 40 男 180 A 5 NaN NaN NaN NaN