// get a logger instance named "com.foo". Let us further assume that the // logger is of type ch.qos.logback.classic.Logger so that we can // set its level ch.qos.logback.classic.Logger logger = (ch.qos.logback.classic.Logger) LoggerFactory.getLogger("com.foo"); //set its Level to INFO. The setLevel() method requires a logback logger logger.setLevel(Level. INFO);
// This request is enabled, because WARN >= INFO logger.warn("Low fuel level.");
// This request is disabled, because DEBUG < INFO. logger.debug("Starting search for nearest gas station.");
// The logger instance barlogger, named "com.foo.Bar", // will inherit its level from the logger named // "com.foo" Thus, the following request is enabled // because INFO >= INFO. barlogger.info("Located nearest gas station.");
// This request is disabled, because DEBUG < INFO. barlogger.debug("Exiting gas station search");
year = 1900 if year % 400 == 0: print"This is a leap year!" # 两个条件都满足才执行 elif year % 4 == 0and year % 100 != 0: print"This is a leap year!" else: print"This is not a leap year." This isnot a leap year.
// 第一种方式,forin strs = 'hello,world' for s in strs: print(s) // 第二种方式,内置函数range()或xrange() for i inrange(len(strs)): print(strs[i])
// 第三种方式,内置函数enumerate() for index, strinenumerate(strs): print(index,str) // 第四种方式,内置函数iter() forstriniter(strs): print(str)
字符串方法
大小写转换
s.upper()方法返回一个将s中的字母全部大写的新字符串。
s.lower()方法返回一个将s中的字母全部小写的新字符串。
1
"hello world".upper()
1
'HELLO WORLD'
这两种方法也不会改变原来s的值:
1 2 3
s = "HELLO WORLD" print(s.lower()) print(s)
1 2
hello world HELLO WORLD
首字母大写
s.capitalize()方法返回一个将s中首字母大写的新字符串。
1 2
s = 'hello,world' print(s.capitalize()) //Hello,world
s.title()方法返回一个将s中每个首字母大写的新字符串。
1 2
print(s.title()) Hello,World
str类型是不可变类型
查找子串
s.index()从左到右查找子串,可以指定起始查找位置,默认是0
s.rindex() 则是从右向左查找
1 2 3 4
s = 'hello,world' print(s.index('l')) print(s.index('l',3)) print(s.rindex('l'))
1 2 3
2 3 9
如果查找不到则会程序报错
1
print(s.index('re'))
1 2 3 4
Traceback (most recent call last): File "/Users/mac7/PycharmProjects/pythonBasic/helloworld.py", line 114, in <module> print(s.index('re')) ValueError: substring not found
s.find() 查找不到则会返回-1
1 2
print(s.find('l')) print(s.find('oo'))
1 2
2 -1
格式化输出
1 2 3 4 5 6 7 8 9 10 11 12 13
# 将字符串以指定的宽度居中并在两侧填充指定的字符 print(s.center(50, '*')) # 将字符串以指定的宽度靠右放置左侧填充指定的字符 print(s.rjust(50, '-')) # 将字符串以指定的宽度靠左放置右侧填充指定的字符 print(s.ljust(50, '-')) # 0填充,使得字符串的长度达到指定的长度 n = '12345' print(n.zfill(10)) # The original string is returned if width is less than or equal to len(s). # 如果指定的长度小于等于原始的长度,则返回原始的字符串 n = '12345' print(n.zfill(5)) // 12345
defsplit(self, *args, **kwargs):# real signature unknown """ Return a list of the words in the string, using sep as the delimiter string. sep 参数一:指定的分割字符 The delimiter according which to split the string. None (the default value) means split according to any whitespace, and discard empty strings from the result. maxsplit 参数二:最大允许分割数量,不指定则默认-1 Maximum number of splits to do. -1 (the default value) means no limit.
1 2 3
line = "1,2,3,4,5,6" numbers = line.split(",",maxsplit=3) print(numbers)
# 创建字典的字面量语法 b = {'one': 'this is number 1', 'two': 'this is number 2'} # 创建字典的构造器语法 items1 = dict(one=1, two=2, three=3, four=4) # 创建字典的推导式语法 items3 = {num: num ** 2for num inrange(1, 10)}
Python 使用 {} 或者 dict() 来创建一个空的字典:
1 2
a = {} type(a)
1
dict
1 2
a = dict() type(a)
1
dict
基本操作
有了dict之后,可以用索引键值的方法向其中添加元素,也可以通过索引来查看元素的值:
插入键值
1 2 3
a["one"] = "this is number 1" a["two"] = "this is number 2" print(a)
1
{'one': 'this is number 1', 'two': 'this is number 2'}
查看键值
1
a['one']
1
'this is number 1'
更新键值
1 2
a["one"] = "this is number 1, too" a
1
{'one': 'this is number 1, too', 'two': 'this is number 2'}
遍历
1 2 3 4 5 6 7 8 9 10 11 12
# 对字典中所有键值对进行遍历 dic = dict(one=1, two=2, three=3, four=4) for key in dic: print(f'{key}: {dic[key]}') # 遍历字典中所以的值 for value in dic.values(): print(value)
# 遍历键值对 for key, value in dic.items(): print(key, value)
TypeError: quad() got multiple values for keyword argument 'a'
作用域
A scope is a textual region of a Python program where a namespace is directly accessible. “Directly accessible” here means that an unqualified reference to a name attempts to find the name in the namespace.
a = (2,3,4) b = [10,5,3] print(list(map(add, a, b))) # [12, 8, 7]
一等函数
Python中的函数是一等函数
函数可以作为函数的参数
函数可以作为函数的返回值
函数可以赋值给变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defcalculate(init_value, fn, *args, **kwargs): total = init_value for arg in args: total = fn(total, arg) for kwarg in kwargs.values(): total = fn(total, kwarg) return total
我们测试一下代码。我们创建List. 然后我们将使用该Stream.distinct()方法查找具有唯一性的 Person 类的所有实例id。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//Java 程序通过 id 查找不同的人 Person lokeshOne = new Person(1, "Lokesh", "Gupta"); Person lokeshTwo = new Person(1, "Lokesh", "Gupta"); Person lokeshThree = new Person(1, "Lokesh", "Gupta"); Person brianOne = new Person(2, "Brian", "Clooney"); Person brianTwo = new Person(2, "Brian", "Clooney"); Person alex = new Person(3, "Alex", "Kolen"); //Add some random persons Collection<Person> list = Arrays.asList(alex, brianOne, brianTwo, lokeshOne, lokeshTwo, lokeshThree);
// Get distinct people by id List<Person> distinctElements = list.stream() .distinct() .collect( Collectors.toList() );
// Let's verify distinct people System.out.println( distinctElements );
1 2 3 4 5 6
输出 [ Person [id=1, fname=Lokesh, lname=Gupta], Person [id=2, fname=Brian, lname=Clooney], Person [id=3, fname=Alex, lname=Kolen] ]
Java 程序按姓名查找不同的人Person lokeshOne = new Person(1, "Lokesh", "Gupta"); Person lokeshTwo = new Person(2, "Lokesh", "Gupta"); Person lokeshThree = new Person(3, "Lokesh", "Gupta"); Person brianOne = new Person(4, "Brian", "Clooney"); Person brianTwo = new Person(5, "Brian", "Clooney"); Person alex = new Person(6, "Alex", "Kolen"); //Add some random persons Collection<Person> list = Arrays.asList(alex, brianOne, brianTwo, lokeshOne, lokeshTwo, lokeshThree);
List<String> arr1 = new ArrayList<String>(); int count = 0; arr1.add("Geeks"); arr1.add("For"); arr1.add("Geeks"); arr1.stream().forEach(s -> { // this will cause an error count++; // print all elements System.out.print(s); });
List<Integer> array = Arrays.asList(-2, 0, 4, 6, 8); int sum = array.stream().reduce(0,(element1, element2) -> element1 + element2); System.out.println("The sum of all elements is " + sum);
Person p1 = new Person(1,"zhang","san"); Person p2 = new Person(2,"li","si"); Person p3 = new Person(3,"wang","wu"); Person p4 = new Person(1,"zhang","san"); Person p5 = new Person(2,"li","si"); Collection<Person> list = Arrays.asList(p1, p2, p3, p4, p5);
List<Person> distinctElements = list.stream().distinct().collect( Collectors.toList() ); System.out.println(distinctElements); //[Person [id=1, fname=zhang, lname=san], Person [id=2, fname=li, lname=si], Person [id=3, fname=wang, lname=wu]]
// ArrayList with duplicate elements ArrayList<Integer> numbersList = new ArrayList<>(Arrays.asList(1, 1, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 8)); Map<Integer, Long> elementCountMap = numbersList.stream() .collect(Collectors.toMap(Function.identity(), v -> 1L, Long::sum)); System.out.println(elementCountMap);
程序输出:
1
{1=2, 2=1, 3=3, 4=1, 5=1, 6=3, 7=1, 8=1}
去重
1 2 3 4 5 6 7 8 9 10 11 12
Person p1 = new Person(1,"zhang","san"); Person p2 = new Person(2,"li","si"); Person p3 = new Person(3,"wang","wu"); Person p4 = new Person(1,"zhang","san"); Person p5 = new Person(2,"li","si"); Collection<Person> list = Arrays.asList(p1, p2, p3, p4, p5);
CREATE VIEW emp_depart AS SELECT CONCAT(last_name,'(',department_name,')') AS emp_dept FROM employees e JOIN departments d WHERE e.department_id = d.department_id
查看视图
语法1:查看数据库的表对象、视图对象
1
SHOW TABLES;
语法2:查看视图的结构
1
DESC / DESCRIBE 视图名称;
语法3:查看视图的属性信息
1 2
# 查看视图信息(显示数据表的存储引擎、版本、数据行数和数据大小等) SHOW TABLE STATUS LIKE '视图名称'\G
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...) [characteristics ...] BEGIN sql语句1; sql语句2;
END $
代码举例
举例1:创建存储过程select_all_data(),查看 emps 表的所有数据
1 2 3 4 5 6 7 8 9
DELIMITER $
CREATE PROCEDURE select_all_data() BEGIN SELECT * FROM emps; END $
DELIMITER ;
举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资
1 2 3 4 5 6 7 8
DELIMITER //
CREATE PROCEDURE avg_employee_salary () BEGIN SELECT AVG(salary) AS avg_salary FROM emps; END //
DELIMITER ;
举例3:创建存储过程show_max_salary(),用来查看“emps”表的最高薪资值。
1 2 3 4 5 6 7 8 9 10 11
CREATE PROCEDURE show_max_salary() LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '查看最高薪资' BEGIN SELECT MAX(salary) FROM emps; END //
CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DOUBLE) BEGIN SELECT salary INTO empsalary FROM emps WHERE ename = empname; END //
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(20)) BEGIN SELECT ename INTO empname FROM emps WHERE eid = (SELECT MID FROM emps WHERE ename=empname); END //
CREATE FUNCTION email_by_name() RETURNS VARCHAR(25) DETERMINISTIC CONTAINS SQL BEGIN RETURN (SELECT email FROM employees WHERE last_name = 'Abel'); END //
CREATE FUNCTION email_by_id(emp_id INT) RETURNS VARCHAR(25) DETERMINISTIC CONTAINS SQL BEGIN RETURN (SELECT email FROM employees WHERE employee_id = emp_id); END //
CREATE FUNCTION count_by_id(dept_id INT) RETURNS INT LANGUAGE SQL NOT DETERMINISTIC READS SQL DATA SQL SECURITY DEFINER COMMENT '查询部门平均工资' BEGIN RETURN (SELECT COUNT(*) FROM employees WHERE department_id = dept_id); END //
DELIMITER ;
调用:
1 2
SET @dept_id = 50; SELECT count_by_id(@dept_id);
注意:
若在创建存储函数中报错“you might want to use the less safe log_bin_trust_function_creators variable”,有两种处理方法:
方式1:加上必要的函数特性“[NOT] DETERMINISTIC”和“{CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA}”
方式2:
1
mysql> SET GLOBAL log_bin_trust_function_creators = 1;
系统变量分为全局系统变量(需要添加global 关键字)以及会话系统变量(需要添加 session 关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。如果不写,默认会话级别。静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
CREATE PROCEDURE set_value() BEGIN DECLARE emp_name VARCHAR(25); DECLARE sal DOUBLE(10,2); SELECT last_name,salary INTO emp_name,sal FROM employees WHERE employee_id = 102; SELECT emp_name,sal; END //
DELIMITER ;
举例2:声明两个变量,求和并打印 (分别使用会话用户变量、局部变量的方式实现)
1 2 3 4 5 6
#方式1:使用用户变量 SET @m=1; SET @n=1; SET @sum=@m+@n;
SELECT @sum;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
#方式2:使用局部变量 DELIMITER //
CREATE PROCEDURE add_value() BEGIN #局部变量 DECLARE m INT DEFAULT 1; DECLARE n INT DEFAULT 3; DECLARE SUM INT; SET SUM = m+n; SELECT SUM; END //
CREATE PROCEDURE different_salary(IN emp_id INT,OUT dif_salary DOUBLE) BEGIN #声明局部变量 DECLARE emp_sal,mgr_sal DOUBLE DEFAULT 0.0; DECLARE mgr_id INT; SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id; SELECT manager_id INTO mgr_id FROM employees WHERE employee_id = emp_id; SELECT salary INTO mgr_sal FROM employees WHERE employee_id = mgr_id; SET dif_salary = mgr_sal - emp_sal;
END //
DELIMITER ;
#调用 SET @emp_id = 102; CALL different_salary(@emp_id,@diff_sal);
CREATE PROCEDURE UpdateDataNoCondition() BEGIN SET @x = 1; UPDATE employees SET email = NULL WHERE last_name = 'Abel'; SET @x = 2; UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel'; SET @x = 3; END //
CREATE PROCEDURE UpdateDataNoCondition() BEGIN #定义处理程序 DECLARE CONTINUE HANDLER FOR 1048 SET @proc_value = -1; SET @x = 1; UPDATE employees SET email = NULL WHERE last_name = 'Abel'; SET @x = 2; UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel'; SET @x = 3; END //
#准备工作 CREATE TABLE departments AS SELECT * FROM atguigudb.`departments`;
ALTER TABLE departments ADD CONSTRAINT uk_dept_name UNIQUE(department_id);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
DELIMITER //
CREATE PROCEDURE InsertDataWithCondition() BEGIN DECLARE duplicate_entry CONDITION FOR SQLSTATE '23000' ; DECLARE EXIT HANDLER FOR duplicate_entry SET @proc_value = -1; SET @x = 1; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 2; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 3; END //
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
SELECT DATEDIFF(CURDATE(),hire_date)/365 INTO hire_year FROM employees WHERE employee_id = emp_id;
IF emp_salary < 8000 AND hire_year > 5 THEN UPDATE employees SET salary = salary + 500 WHERE employee_id = emp_id; ELSE UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id; END IF; END //
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id; SELECT commission_pct INTO bonus FROM employees WHERE employee_id = emp_id;
IF emp_salary < 9000 THEN UPDATE employees SET salary = 9000 WHERE employee_id = emp_id; ELSEIF emp_salary < 10000 AND bonus IS NULL THEN UPDATE employees SET commission_pct = 0.01 WHERE employee_id = emp_id; ELSE UPDATE employees SET salary = salary + 100 WHERE employee_id = emp_id; END IF; END //
DELIMITER ;
分支结构之 CASE
CASE 语句的语法结构1:
1 2 3 4 5 6 7
#情况一:类似于switch CASE 表达式 WHEN 值1 THEN 结果1或语句1(如果是语句,需要加分号) WHEN 值2 THEN 结果2或语句2(如果是语句,需要加分号) ... ELSE 结果n或语句n(如果是语句,需要加分号) END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
CASE 语句的语法结构2:
1 2 3 4 5 6 7
#情况二:类似于多重if CASE WHEN 条件1 THEN 结果1或语句1(如果是语句,需要加分号) WHEN 条件2 THEN 结果2或语句2(如果是语句,需要加分号) ... ELSE 结果n或语句n(如果是语句,需要加分号) END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
举例1:
使用CASE流程控制语句的第1种格式,判断val值等于1、等于2,或者两者都不等。
1 2 3 4 5
CASE val WHEN 1 THEN SELECT 'val is 1'; WHEN 2 THEN SELECT 'val is 2'; ELSE SELECT 'val is not 1 or 2'; END CASE;
举例2:
使用CASE流程控制语句的第2种格式,判断val是否为空、小于0、大于0或者等于0。
1 2 3 4 5 6
CASE WHEN val IS NULL THEN SELECT 'val is null'; WHEN val < 0 THEN SELECT 'val is less than 0'; WHEN val > 0 THEN SELECT 'val is greater than 0'; ELSE SELECT 'val is 0'; END CASE;
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id; SELECT commission_pct INTO bonus FROM employees WHERE employee_id = emp_id;
CASE WHEN emp_sal<9000 THEN UPDATE employees SET salary=9000 WHERE employee_id = emp_id; WHEN emp_sal<10000 AND bonus IS NULL THEN UPDATE employees SET commission_pct=0.01 WHERE employee_id = emp_id; ELSE UPDATE employees SET salary=salary+100 WHERE employee_id = emp_id; END CASE; END //
SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id; SELECT ROUND(DATEDIFF(CURDATE(),hire_date)/365) INTO hire_year FROM employees WHERE employee_id = emp_id;
CASE hire_year WHEN 0 THEN UPDATE employees SET salary=salary+50 WHERE employee_id = emp_id; WHEN 1 THEN UPDATE employees SET salary=salary+100 WHERE employee_id = emp_id; WHEN 2 THEN UPDATE employees SET salary=salary+200 WHERE employee_id = emp_id; WHEN 3 THEN UPDATE employees SET salary=salary+300 WHERE employee_id = emp_id; WHEN 4 THEN UPDATE employees SET salary=salary+400 WHERE employee_id = emp_id; ELSE UPDATE employees SET salary=salary+500 WHERE employee_id = emp_id; END CASE; END //
CREATE PROCEDURE update_salary_loop(OUT num INT) BEGIN DECLARE avg_salary DOUBLE; DECLARE loop_count INT DEFAULT 0; SELECT AVG(salary) INTO avg_salary FROM employees; label_loop:LOOP IF avg_salary >= 12000 THEN LEAVE label_loop; END IF; UPDATE employees SET salary = salary * 1.1; SET loop_count = loop_count + 1; SELECT AVG(salary) INTO avg_salary FROM employees; END LOOP label_loop; SET num = loop_count;
CREATE PROCEDURE update_salary_while(OUT num INT) BEGIN DECLARE avg_sal DOUBLE ; DECLARE while_count INT DEFAULT 0; SELECT AVG(salary) INTO avg_sal FROM employees; WHILE avg_sal > 5000 DO UPDATE employees SET salary = salary * 0.9; SET while_count = while_count + 1; SELECT AVG(salary) INTO avg_sal FROM employees; END WHILE; SET num = while_count;
END //
DELIMITER ;
循环结构之REPEAT
REPEAT语句创建一个带条件判断的循环过程。与WHILE循环不同的是,REPEAT 循环首先会执行一次循环,然后在 UNTIL 中进行表达式的判断,如果满足条件就退出,即 END REPEAT;如果条件不满足,则会就继续执行循环,直到满足退出条件为止。
REPEAT语句的基本格式如下:
1 2 3 4
[repeat_label:] REPEAT 循环体的语句 UNTIL 结束循环的条件表达式 END REPEAT [repeat_label]
CREATE PROCEDURE update_salary_repeat(OUT num INT) BEGIN DECLARE avg_sal DOUBLE ; DECLARE repeat_count INT DEFAULT 0; SELECT AVG(salary) INTO avg_sal FROM employees; REPEAT UPDATE employees SET salary = salary * 1.15; SET repeat_count = repeat_count + 1; SELECT AVG(salary) INTO avg_sal FROM employees; UNTIL avg_sal >= 13000 END REPEAT; SET num = repeat_count; END //
begin_label: BEGIN IF num<=0 THEN LEAVE begin_label; ELSEIF num=1 THEN SELECT AVG(salary) FROM employees; ELSEIF num=2 THEN SELECT MIN(salary) FROM employees; ELSE SELECT MAX(salary) FROM employees; END IF; SELECT COUNT(*) FROM employees; END //
DELIMITER // CREATE PROCEDURE leave_while(OUT num INT)
BEGIN # DECLARE avg_sal DOUBLE;#记录平均工资 DECLARE while_count INT DEFAULT 0; #记录循环次数 SELECT AVG(salary) INTO avg_sal FROM employees; #① 初始化条件 while_label:WHILE TRUE DO #② 循环条件 #③ 循环体 IF avg_sal <= 10000 THEN LEAVE while_label; END IF; UPDATE employees SET salary = salary * 0.9; SET while_count = while_count + 1; #④ 迭代条件 SELECT AVG(salary) INTO avg_sal FROM employees; END WHILE; #赋值 SET num = while_count;
BEGIN DECLARE num INT DEFAULT 0; my_loop:LOOP SET num = num + 1; IF num < 10 THEN ITERATE my_loop; ELSEIF num > 15 THEN LEAVE my_loop; END IF; SELECT '尚硅谷:让天下没有难学的技术'; END LOOP my_loop;
BEGIN DECLARE sum_salary DOUBLE DEFAULT 0; #记录累加的总工资 DECLARE cursor_salary DOUBLE DEFAULT 0; #记录某一个工资值 DECLARE emp_count INT DEFAULT 0; #记录循环个数 #定义游标 DECLARE emp_cursor CURSOR FOR SELECT salary FROM employees ORDER BY salary DESC; #打开游标 OPEN emp_cursor; REPEAT #使用游标(从游标中获取数据) FETCH emp_cursor INTO cursor_salary; SET sum_salary = sum_salary + cursor_salary; SET emp_count = emp_count + 1; UNTIL sum_salary >= limit_total_salary END REPEAT; SET total_count = emp_count; #关闭游标 CLOSE emp_cursor; END //
DELIMITER ;
小结
游标是 MySQL 的一个重要的功能,为逐条读取结果集中的数据,提供了完美的解决方案。跟在应用层面实现相同的功能相比,游标可以在存储程序中使用,效率高,程序也更加简洁。
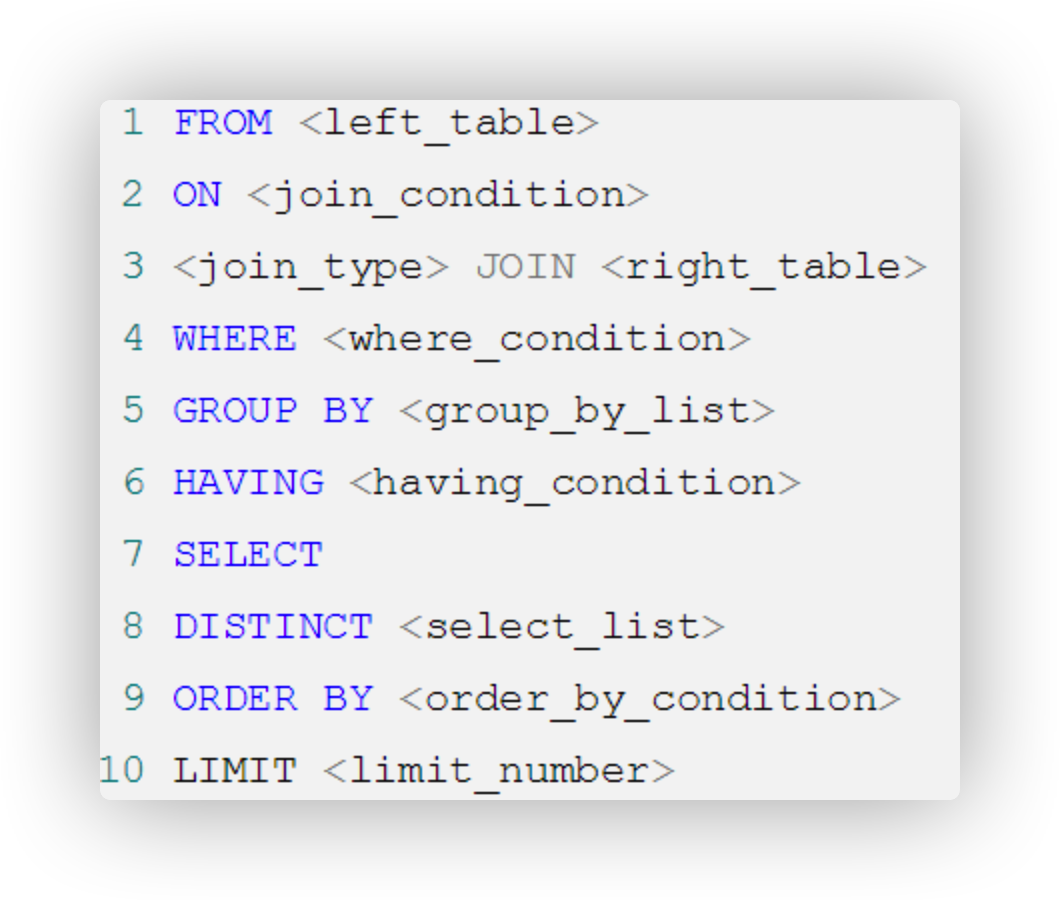
SELECT ... FROM ... WHERE ... GROUPBY ... HAVING ... ORDERBY ... LIMIT...
2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
1
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
1 2 3 4 5 6 7
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5 FROM player JOIN team ON player.team_id = team.team_id # 顺序 1 WHERE height > 1.80 # 顺序 2 GROUP BY player.team_id # 顺序 3 HAVING num > 2 # 顺序 4 ORDER BY num DESC # 顺序 6 LIMIT 2 # 顺序 7
CREATE TABLE test_blob1( id INT, img MEDIUMBLOB );
TEXT和BLOB的使用注意事项:
在使用text和blob字段类型时要注意以下几点,以便更好的发挥数据库的性能。
① BLOB和TEXT值也会引起自己的一些问题,特别是执行了大量的删除或更新操作的时候。删除这种值会在数据表中留下很大的”空洞“,以后填入这些”空洞”的记录可能长度不同。为了提高性能,建议定期使用 OPTIMIZE TABLE 功能对这类表进行碎片整理。
② 如果需要对大文本字段进行模糊查询,MySQL 提供了前缀索引。但是仍然要在不必要的时候避免检索大型的BLOB或TEXT值。例如,SELECT * 查询就不是很好的想法,除非你能够确定作为约束条件的WHERE子句只会找到所需要的数据行。否则,你可能毫无目的地在网络上传输大量的值。
③ 把BLOB或TEXT列分离到单独的表中。在某些环境中,如果把这些数据列移动到第二张数据表中,可以让你把原数据表中的数据列转换为固定长度的数据行格式,那么它就是有意义的。这会减少主表中的碎片,使你得到固定长度数据行的性能优势。它还使你在主数据表上运行 SELECT * 查询的时候不会通过网络传输大量的BLOB或TEXT值。
INSERT INTO test_json (js) VALUES ('{"name":"songhk", "age":18, "address":{"province":"beijing", "city":"beijing"}}');
当需要检索JSON类型的字段中数据的某个具体值时,可以使用“->”和“->>”符号。
1 2 3 4 5 6 7 8
mysql> SELECT js -> '$.name' AS NAME,js -> '$.age' AS age ,js -> '$.address.province' AS province, js -> '$.address.city' AS city -> FROM test_json; +----------+------+-----------+-----------+ | NAME | age | province | city | +----------+------+-----------+-----------+ | "songhk" | 18 | "beijing" | "beijing" | +----------+------+-----------+-----------+ 1 row in set (0.00 sec)
在 MySQL 里,外键约束是有成本的,需要消耗系统资源。对于大并发的 SQL 操作,有可能会不适合。比如大型网站的中央数据库,可能会因为外键约束的系统开销而变得非常慢。所以, MySQL 允许你不使用系统自带的外键约束,在应用层面完成检查数据一致性的逻辑。也就是说,即使你不用外键约束,也要想办法通过应用层面的附加逻辑,来实现外键约束的功能,确保数据的一致性。
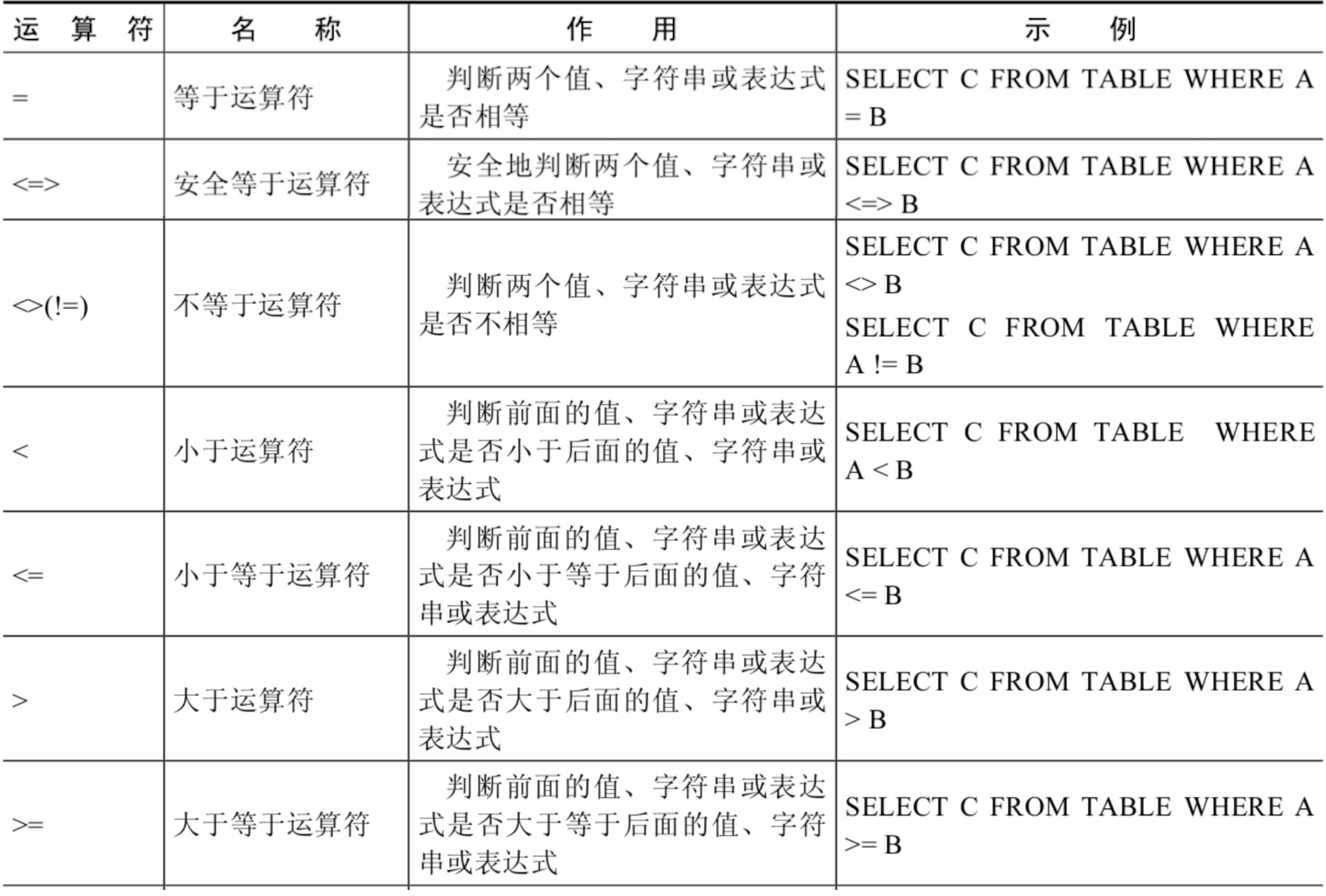
SELECT 字段列表 FROM A表 INNER JOIN B表 ON 关联条件 WHERE 等其他子句;
例子:
1 2 3 4
SELECT e.employee_id, e.last_name, e.department_id, d.department_id, d.location_id FROM employees e JOIN departments d ON (e.department_id = d.department_id);
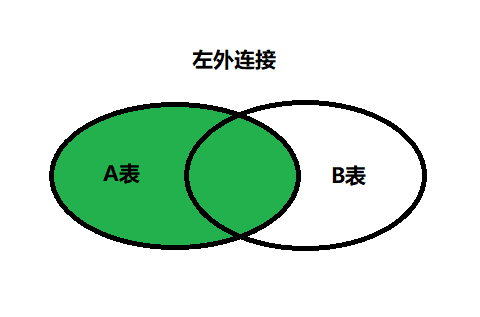
外连接(OUTER JOIN)的实现
左外连接(LEFT OUTER JOIN)
语法:
1 2 3 4 5
#实现查询结果是A SELECT 字段列表 FROM A表 LEFT JOIN B表 ON 关联条件 WHERE 等其他子句;
举例:
1 2 3 4
SELECT e.last_name, e.department_id, d.department_name FROM employees e LEFT OUTER JOIN departments d ON (e.department_id = d.department_id) ;
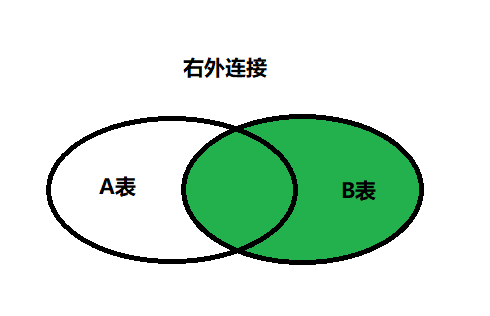
右外连接(RIGHT OUTER JOIN)
语法:
1 2 3 4 5
#实现查询结果是B SELECT 字段列表 FROM A表 RIGHT JOIN B表 ON 关联条件 WHERE 等其他子句;
举例:
1 2 3 4
SELECT e.last_name, e.department_id, d.department_name FROM employees e RIGHT OUTER JOIN departments d ON (e.department_id = d.department_id) ;
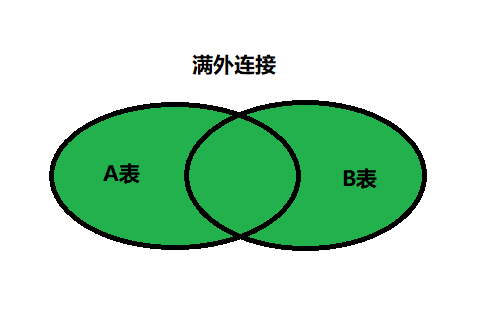
满外连接(FULL OUTER JOIN)
满外连接的结果 = 左右表匹配的数据 + 左表没有匹配到的数据 + 右表没有匹配到的数据。
SQL99是支持满外连接的。使用FULL JOIN 或 FULL OUTER JOIN来实现。
需要注意的是,MySQL不支持FULL JOIN,但是可以用 LEFT JOIN UNION RIGHT join代替。
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d ON e.`department_id` = d.`department_id` AND e.`manager_id` = d.`manager_id`;
在 SQL99 中你可以写成:
1 2
SELECT employee_id,last_name,department_name FROM employees e NATURAL JOIN departments d;
USING连接
当我们进行连接的时候,SQL99还支持使用 USING 指定数据表里的同名字段进行等值连接。但是只能配合JOIN一起使用。比如:
1 2 3
SELECT employee_id,last_name,department_name FROM employees e JOIN departments d USING (department_id);
SELECT DATE_ADD(NOW(), INTERVAL 1 DAY) AS col1,DATE_ADD('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col2, ADDDATE('2021-10-21 23:32:12',INTERVAL 1 SECOND) AS col3, DATE_ADD('2021-10-21 23:32:12',INTERVAL '1_1' MINUTE_SECOND) AS col4, DATE_ADD(NOW(), INTERVAL -1 YEAR) AS col5, #可以是负数 DATE_ADD(NOW(), INTERVAL '1_1' YEAR_MONTH) AS col6 #需要单引号 FROM DUAL;
1 2 3 4
SELECT DATE_SUB('2021-01-21',INTERVAL 31 DAY) AS col1, SUBDATE('2021-01-21',INTERVAL 31 DAY) AS col2, DATE_SUB('2021-01-21 02:01:01',INTERVAL '1 1' DAY_HOUR) AS col3 FROM DUAL;
第2组:
函数
用法
ADDTIME(time1,time2)
返回time1加上time2的时间。当time2为一个数字时,代表的是秒,可以为负数
SUBTIME(time1,time2)
返回time1减去time2后的时间。当time2为一个数字时,代表的是秒,可以为负数
DATEDIFF(date1,date2)
返回date1 - date2的日期间隔天数
TIMEDIFF(time1, time2)
返回time1 - time2的时间间隔
FROM_DAYS(N)
返回从0000年1月1日起,N天以后的日期
TO_DAYS(date)
返回日期date距离0000年1月1日的天数
LAST_DAY(date)
返回date所在月份的最后一天的日期
MAKEDATE(year,n)
针对给定年份与所在年份中的天数返回一个日期
MAKETIME(hour,minute,second)
将给定的小时、分钟和秒组合成时间并返回
PERIOD_ADD(time,n)
返回time加上n后的时间
举例:
1 2 3 4
SELECTADDTIME(NOW(),20),SUBTIME(NOW(),30),SUBTIME(NOW(),'1:1:3'),DATEDIFF(NOW(),'2021-10-01'), TIMEDIFF(NOW(),'2021-10-25 22:10:10'),FROM_DAYS(366),TO_DAYS('0000-12-25'), LAST_DAY(NOW()),MAKEDATE(YEAR(NOW()),12),MAKETIME(10,21,23),PERIOD_ADD(20200101010101,10) FROM DUAL;
日期的格式化与解析
函数
用法
DATE_FORMAT(date,fmt)
按照字符串fmt格式化日期date值
TIME_FORMAT(time,fmt)
按照字符串fmt格式化时间time值
GET_FORMAT(date_type,format_type)
返回日期字符串的显示格式
STR_TO_DATE(str, fmt)
按照字符串fmt对str进行解析,解析为一个日期
上述非GET_FORMAT函数中fmt参数常用的格式符:
格式符
说明
格式符
说明
%Y
4位数字表示年份
%y
表示两位数字表示年份
%M
月名表示月份(January,….)
%m
两位数字表示月份(01,02,03。。。)
%b
缩写的月名(Jan.,Feb.,….)
%c
数字表示月份(1,2,3,…)
%D
英文后缀表示月中的天数(1st,2nd,3rd,…)
%d
两位数字表示月中的天数(01,02…)
%e
数字形式表示月中的天数(1,2,3,4,5…..)
%H
两位数字表示小数,24小时制(01,02..)
%h和%I
两位数字表示小时,12小时制(01,02..)
%k
数字形式的小时,24小时制(1,2,3)
%l
数字形式表示小时,12小时制(1,2,3,4….)
%i
两位数字表示分钟(00,01,02)
%S和%s
两位数字表示秒(00,01,02…)
%W
一周中的星期名称(Sunday…)
%a
一周中的星期缩写(Sun.,Mon.,Tues.,..)
%w
以数字表示周中的天数(0=Sunday,1=Monday….)
%j
以3位数字表示年中的天数(001,002…)
%U
以数字表示年中的第几周,(1,2,3。。)其中Sunday为周中第一天
%u
以数字表示年中的第几周,(1,2,3。。)其中Monday为周中第一天
%T
24小时制
%r
12小时制
%p
AM或PM
%%
表示%
GET_FORMAT函数中date_type和format_type参数取值如下:
日期类型
格式化类型
返回的格式化字符串
DATE
USA
%m.%d.%Y
DATE
JIS
%Y-%m-%d
DATE
ISO
%Y-%m-%d
DATE
EUR
%d.%m.%Y
DATE
INTERNAL
%Y%m%d
TIME
USA
%h:%i:%s %p
TIME
JIS
%H:%i:%s
TIME
ISO
%H:%i:%s
TIME
EUR
%H.%i.%s
TIME
INTERNAL
%H%i%s
DATETIME
USA
%Y-%m-%d %H.%i.%s
DATETIME
JIS
%Y-%m-%d %H:%i:%s
DATETIME
ISO
%Y-%m-%d %H:%i:%s
DATETIME
EUR
%Y-%m-%d %I-L%i.%s
DATETIME
INTERNAL
%Y%m%d%H%i%s
举例:
1 2 3 4 5 6 7
mysql> SELECT DATE_FORMAT(NOW(), '%H:%i:%s'); +--------------------------------+ | DATE_FORMAT(NOW(), '%H:%i:%s') | +--------------------------------+ | 22:57:34 | +--------------------------------+ 1 row in set (0.00 sec)
1 2 3 4 5 6 7 8
SELECT STR_TO_DATE('09/01/2009','%m/%d/%Y') FROM DUAL;
SELECT STR_TO_DATE('20140422154706','%Y%m%d%H%i%s') FROM DUAL;
SELECT STR_TO_DATE('2014-04-22 15:47:06','%Y-%m-%d %H:%i:%s') FROM DUAL;
1 2 3 4 5 6 7 8 9 10
mysql> SELECT GET_FORMAT(DATE, 'USA'); +-------------------------+ | GET_FORMAT(DATE, 'USA') | +-------------------------+ | %m.%d.%Y | +-------------------------+ 1 row in set (0.00 sec)
SELECT DATE_FORMAT(NOW(),GET_FORMAT(DATE,'USA')), FROM DUAL;
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 …. [ELSE resultn] END
相当于Java的if…else if…else…
CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 …. [ELSE 值n] END
相当于Java的switch…case…
1 2
SELECT IF(1 > 0,'正确','错误') ->正确
1 2
SELECT IFNULL(null,'Hello Word') ->Hello Word
1 2 3 4 5 6 7 8
SELECT CASE WHEN 1 > 0 THEN '1 > 0' WHEN 2 > 0 THEN '2 > 0' ELSE '3 > 0' END ->1 > 0
1 2 3 4
SELECT CASE 1 WHEN 1 THEN '我是1' WHEN 2 THEN '我是2' ELSE '你是谁'
1 2 3 4 5
SELECT employee_id,salary, CASE WHEN salary>=15000 THEN '高薪' WHEN salary>=10000 THEN '潜力股' WHEN salary>=8000 THEN '屌丝' ELSE '草根' END "描述" FROM employees;
1 2 3 4 5 6
SELECT oid,`status`, CASE `status` WHEN 1 THEN '未付款' WHEN 2 THEN '已付款' WHEN 3 THEN '已发货' WHEN 4 THEN '确认收货' ELSE '无效订单' END FROM t_order;
1 2 3 4 5 6
SELECT last_name, job_id, salary, CASE job_id WHEN 'IT_PROG' THEN 1.10*salary WHEN 'ST_CLERK' THEN 1.15*salary WHEN 'SA_REP' THEN 1.20*salary ELSE salary END "REVISED_SALARY" FROM employees;
Unexpected @FunctionalInterface annotation @FunctionalInterface ^ WorkerInterface is not a functional interfacemultiple non-overridingabstractmethodsfoundininterfaceWorkerInterface 1 error
publicstaticvoidmain(args[]){ List languages = Arrays.asList("Java", "Scala", "C++", "Haskell", "Lisp"); System.out.println("Languages which starts with J :"); filter(languages, (str)->str.startsWith("J")); System.out.println("Languages which ends with a "); filter(languages, (str)->str.endsWith("a")); System.out.println("Print all languages :"); filter(languages, (str)->true); System.out.println("Print no language : "); filter(languages, (str)->false); System.out.println("Print language whose length greater than 4:"); filter(languages, (str)->str.length() > 4); } publicstaticvoidfilter(List names, Predicate condition){ names.stream().filter((name) -> (condition.test(name))).forEach((name) -> { System.out.println(name + " "); }); }
多个Predicate组合filter
1 2 3 4 5 6 7
// 可以用and()、or()和xor()逻辑函数来合并Predicate, // 例如要找到所有以J开始,长度为四个字母的名字,你可以合并两个Predicate并传入 Predicate<String> startsWithJ = (n) -> n.startsWith("J"); Predicate<String> fourLetterLong = (n) -> n.length() == 4; names.stream() .filter(startsWithJ.and(fourLetterLong)) .forEach((n) -> System.out.print("nName, which starts with 'J' and four letter long is : " + n));
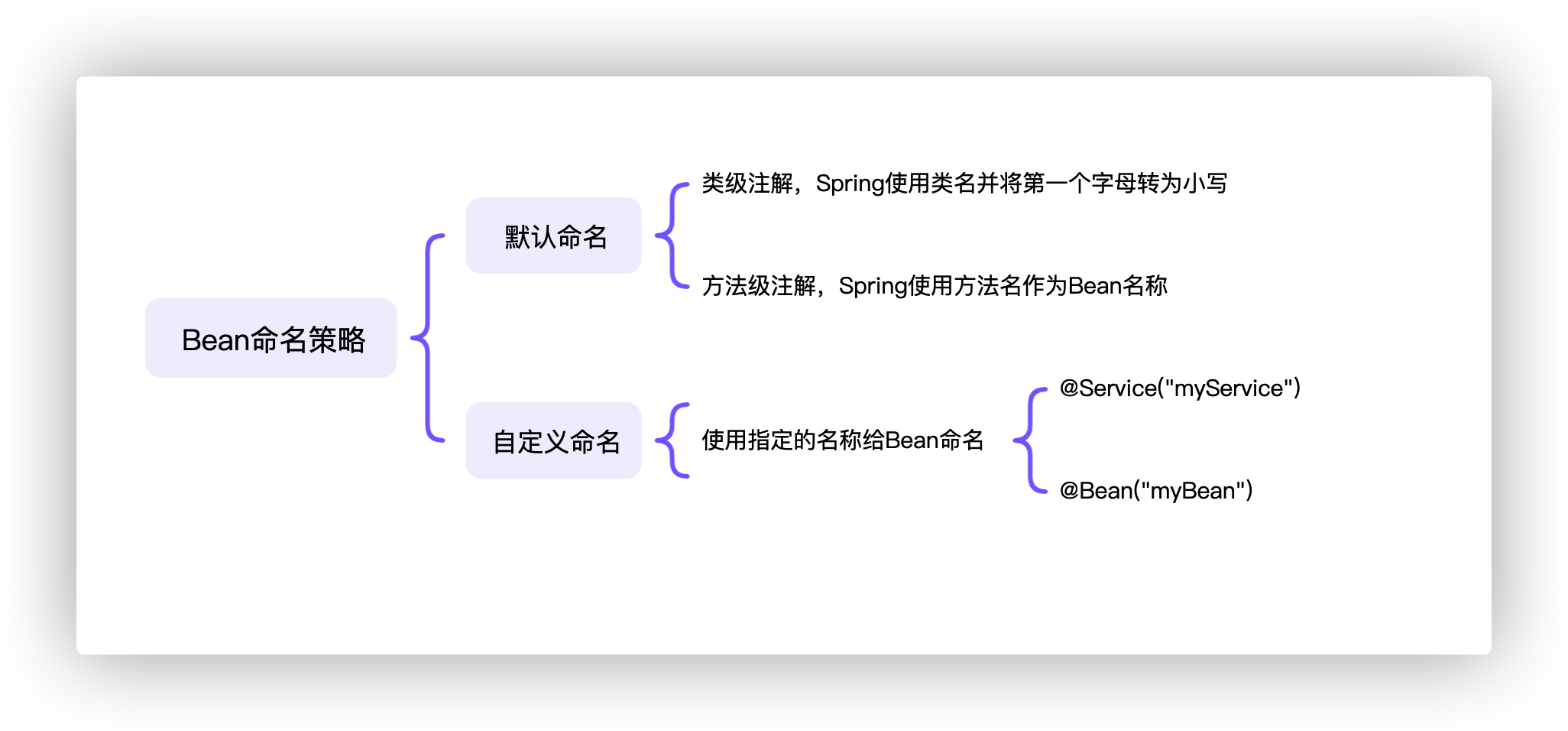
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Component public@interface Service {
/** * The value may indicate a suggestion for a logical component name, * to be turned into a Spring bean in case of an autodetected component. * @return the suggested component name, if any (or empty String otherwise) */ @AliasFor(annotation = Component.class) String value()default "";
/** * The value may indicate a suggestion for a logical component name, * to be turned into a Spring bean in case of an autodetected component. * @return the suggested component name, if any (or empty String otherwise) */ @AliasFor(annotation = Component.class) String value()default "";
Advantage of @Inject annotation is that rather than inject a reference directly, you could ask @Inject to inject a Provider. The Provider interface enables, among other things, lazy injection of bean references and injection of multiple instances of a bean. In case we have few implementation of an interface or a subclass we can narrow down the selection using the @Named annotation to avoid ambiguity. @Named annotation works much like Spring’s @Qualifier
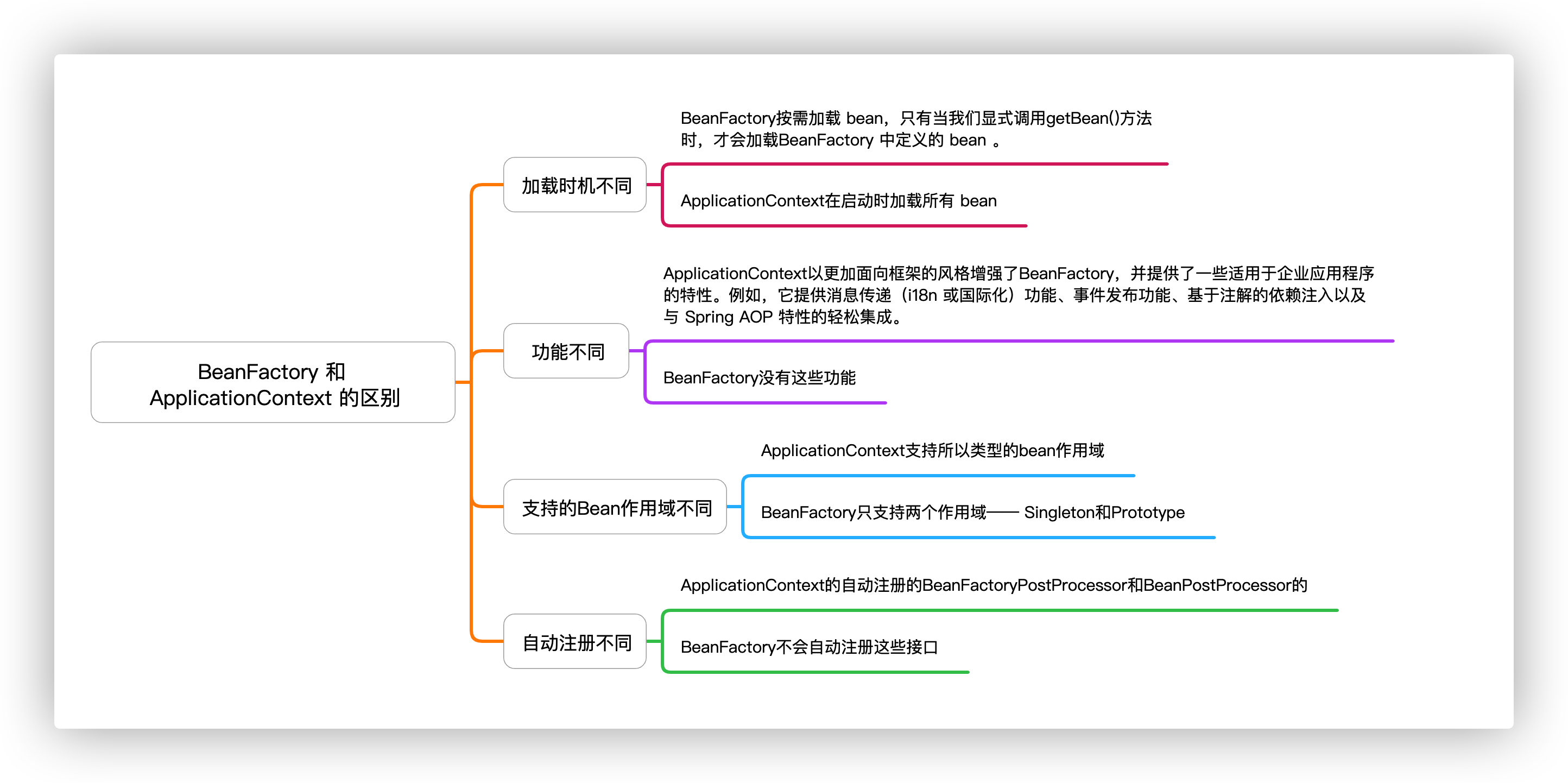
在构建 bean 时,@ Autowired依赖项应该可用。否则,如果 Spring 无法解析用于连接的 bean,它将抛出异常。
因此,它会阻止 Spring 容器成功启动,但以下形式除外:
1 2 3 4 5
Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type [com.autowire.sample.FooDAO] found for dependency: expected at least 1 bean which qualifies as autowire candidate forthis dependency. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true)}













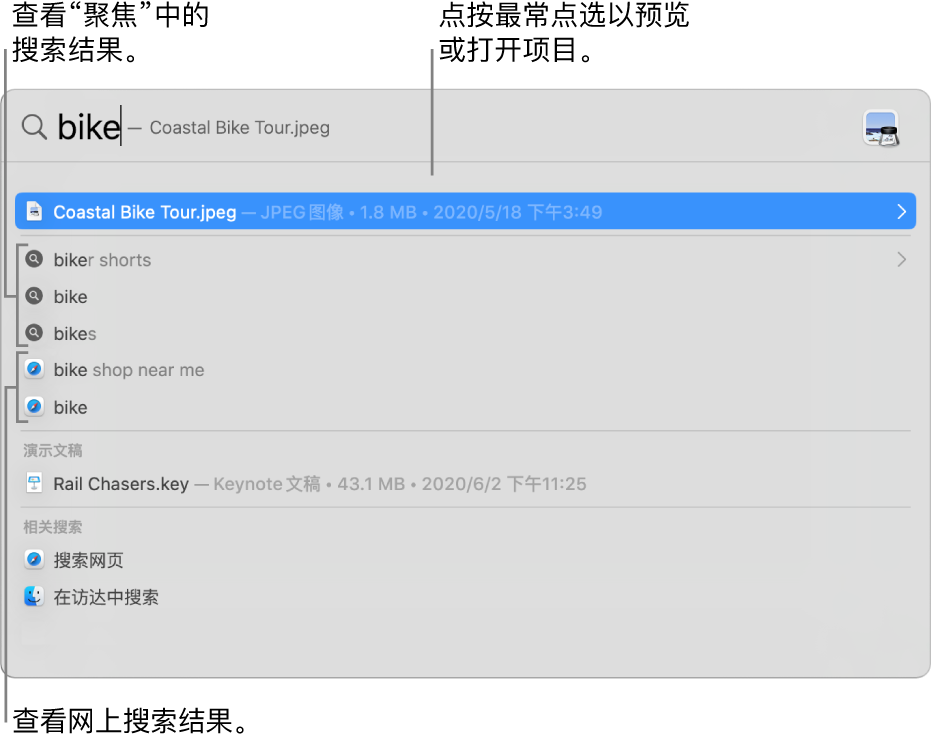
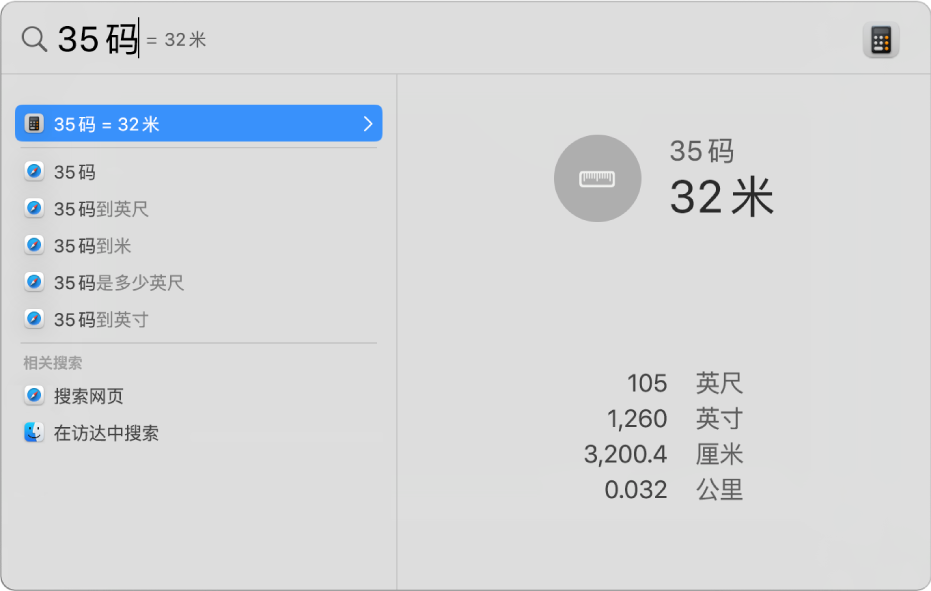
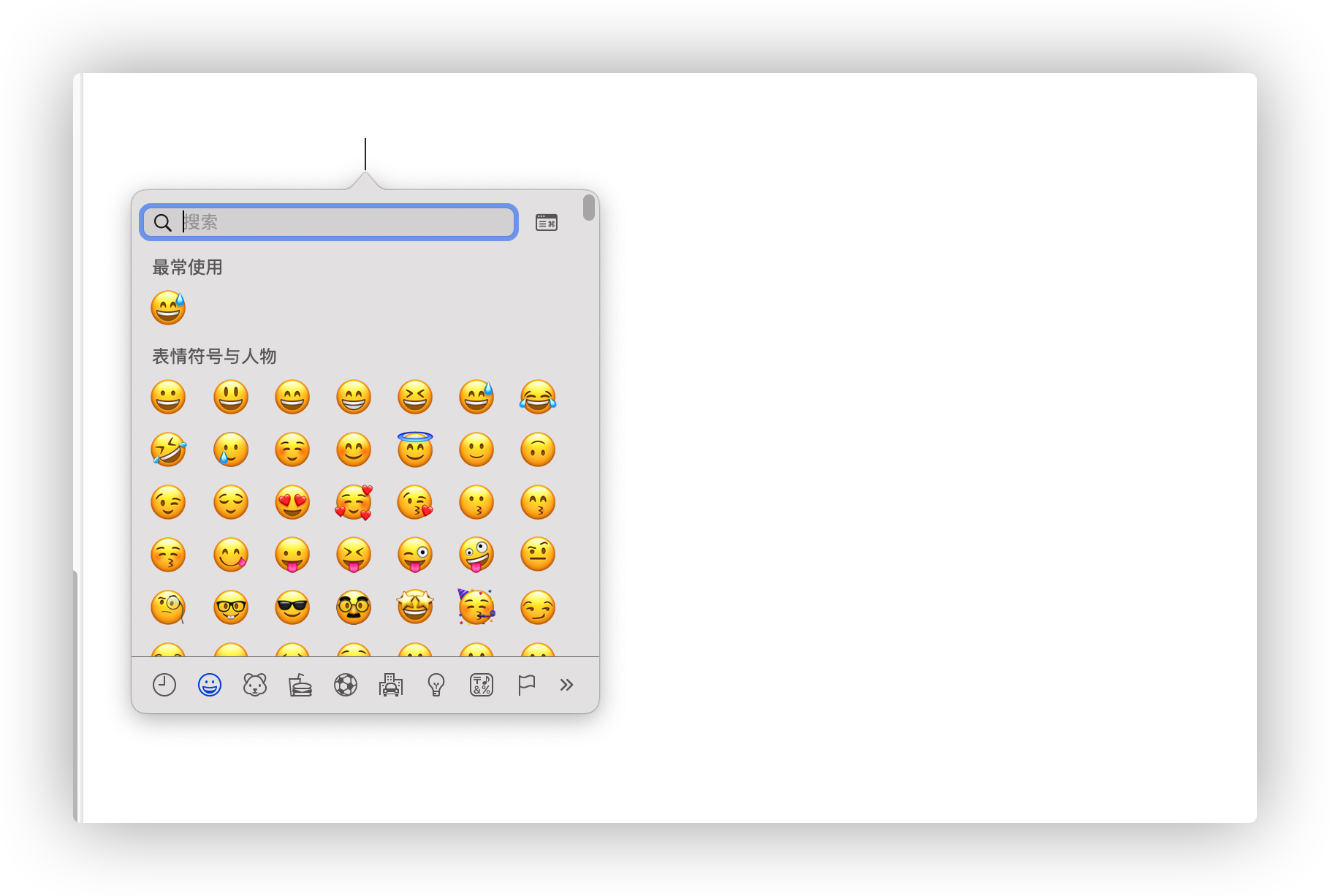
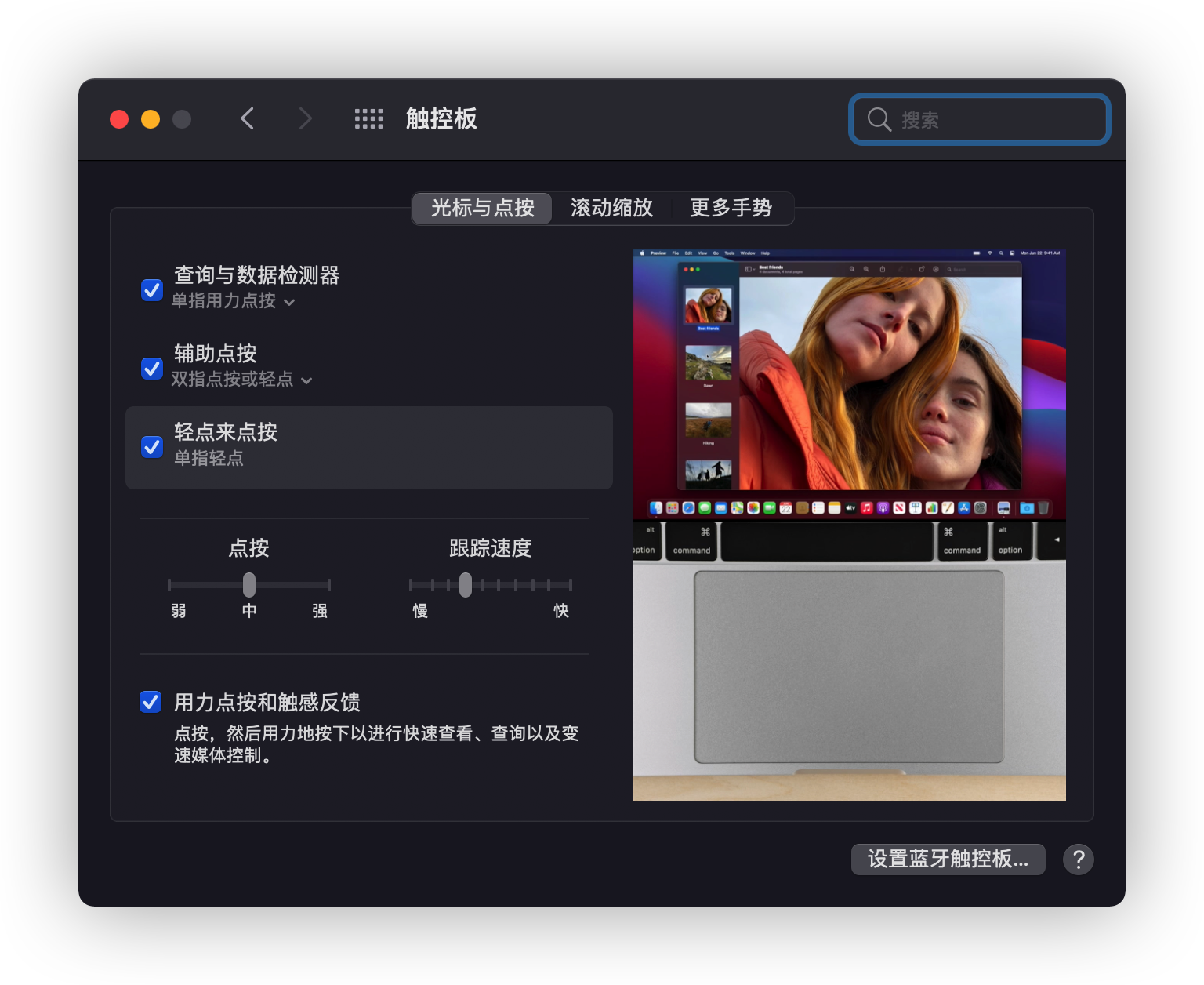
 (如果显示),或者按下 Command-空格键或按下键盘上功能键行中的
(如果显示),或者按下 Command-空格键或按下键盘上功能键行中的